

1. 서 론
2. 단자유도 시스템 제어기 설계
2.1 가변 강성 단자유도 시스템
2.2 최적 제어 기반 제어기 설계
2.3 강화학습 기반 제어기 설계
3. 제어기 설계 결과 및 성능 비교
3.1 수치 예제 및 제어기 설계 조건
3.2 강화학습 기반 제어기 설계 결과
3.3 공칭 성능 비교
3.4 강인 성능 비교
4. 토의 및 결론
1. 서 론
구조물의 진동 제어를 위한 준능동 제어(semi-active control)는 외부 에너지를 이용하여 제어력을 직접 구조물에 가하는 능동 제어와 달리, 구조물의 강성이나 감쇠와 같은 동적 특성을 실시간으로 조절함으로써 진동 응답을 저감하는 방법이다(Housner et al., 1997; Symans and Constantinou, 1999). 준능동 제어는 능동 제어가 갖는 우수한 적응성과 수동 제어의 에너지 효율성을 동시에 확보할 수 있어, 상대적으로 작은 제어 에너지로도 대형 구조물의 진동을 효과적으로 제어할 수 있다는 장점이 있다.
이러한 준능동 제어 개념의 하나인 가변 강성 제어(variable stiffness control)는 구조 시스템의 강성을 시간에 따라 조절함으로써 진동 제어 성능을 향상시키는 방법으로 로봇 공학, 차량 서스펜션, 항공기 및 위성 구조물 등 다양한 공학 분야에서 활발히 적용되어 왔다. 토목 구조물 분야에서도 가변 강성 내진 구조 시스템이나 적응형 동조 질량 감쇠기(adaptive tuned mass damper, ATMD)와 같은 형태로 연구 및 적용 사례가 보고되고 있다(Ikeda and Saito, 2000; Kim and Lee, 2015; Nagarajaiah and Varadarajan, 2005).
진동 제어를 위한 가변 강성 제어기 설계의 핵심은 진동 에너지 최소화 또는 구조 응답 최소화와 같은 제어 목적을 달성하기 위하여 실시간으로 적절한 강성 값을 결정하는 제어 법칙을 정의하는 데 있다. 이를 위해 최적 제어(optimal control), 슬라이딩 모드 제어(sliding mode control), 적응 제어(adaptive control) 등 다양한 전통적 제어 이론이 적용되어 왔으며(Slotine and Li, 1991; Soong, 1990; Utkin, 1992), 가변 강성 시스템의 경우 강성 변화에 따른 시스템 비선형성 및 강성의 상・하한 제한 조건을 고려한 제어기 설계가 요구된다.
최근에는 이러한 비선형성과 제약 조건을 보다 유연하게 다루기 위한 방법으로 강화 학습(reinforcement learning, RL)을 활용한 제어기 설계에 대한 연구가 활발히 진행되고 있다(Sutton and Barto, 2018; Wang and Chen, 2020; Yang et al., 2018). 강화 학습 기반 제어는 우수한 환경 적응성, 복잡한 비선형 제어 전략의 학습 능력, 그리고 모델 프리(model-free) 학습이 가능하다는 장점으로 인해 정확한 수학적 모델링이 어려운 시스템의 제어에 특히 유리한 것으로 알려져 있다(Li et al., 2021; Recht, 2019).
이 연구의 목적은 강화 학습 기반 제어기, 특히 깊은 신경망(deep neural network)을 활용한 제어기가 기존의 전통적인 가변 강성 제어 방법과 비교하여 어떠한 특성을 갖는지를 분석하는 데 있다. 구체적으로, 동일한 목적함수 또는 보상함수를 적용한 경우 최적 제어 기반 제어기와 강화 학습 제어기 간의 성능 차이, 그리고 시스템의 비선형성 및 불확실성이 존재할 때의 응답 특성을 비교・분석하고자 한다(Recht, 2019; Sutton and Barto, 2018).
이를 위한 첫 단계로서 본 연구에서는 가장 단순한 형태의 비선형 구조 시스템 중 하나인 단자유도(single-degree-of-freedom, SDOF) 가변 강성 시스템을 대상으로 제어기 설계 및 수치 해석을 수행하였다. 강화 학습 제어기로는 연속적인 행동 공간을 직접 다룰 수 있는 대표적인 심층 강화 학습 알고리즘인 심층 결정적 정책 경사(Deep Deterministic Policy Gradient, DDPG) 방법을 적용하였다(Lillicrap et al., 2015). 비교 대상 제어 방법으로는 진동 에너지의 증감 방향을 고려한 bang-bang 제어 방법(Karnopp, 1984)과, 선형 최적 제어 해를 기반으로 제어 입력의 제한을 고려한 제한 최적 제어(clipped-optimal control) 방법(Dyke et al., 1996; Spencer et al., 1997)을 사용하였다.
본 논문의 구성은 다음과 같다. 2장에서는 가변 강성 단자유도 시스템의 수학적 모델과 기존 제어 방법 및 강화 학습 기반 DDPG 제어기 설계 절차를 설명한다. 3장에서는 자유 진동 및 강제 진동 조건 하에서 각 제어기의 공칭 성능과 센서 잡음이 존재하는 경우의 강인 성능을 비교・분석한다. 마지막으로 4장에서는 해석 결과를 바탕으로 결론 및 향후 연구 방향을 제시한다.
2. 단자유도 시스템 제어기 설계
2.1 가변 강성 단자유도 시스템
이 연구에서 고려하는 가변 강성 단자유도 시스템의 운동방정식은 다음 식 (1)과 같다.
여기서, 는 시간 에서의 변위 응답, 은 질량, 는 감쇠 계수, 는 강성, 는 외부 하중이고, 제어기에 따라 실시간으로 변화하는 가변 강성을 로 표시하였다. 이 연구에서 가변 강성은 일반적인 구조 제어 시스템의 제어 장치를 고려하여 양의 값을 가지는 인 것으로 가정한다.
2.2 최적 제어 기반 제어기 설계
이 연구에서는 구조계의 진동 응답을 최소화하는 진동 제어 설계 방법 중에서 전통적인 최적 제어 설계 방법을 성능 평가를 위한 비교 기준으로 삼는다. 식 (1)의 단자유도 시스템에 대하여 전통적인 최적 설계 제어에서는 다음 식 (2)와 같은 성능 지수(performance index) 를 최소화하는 제어 법칙을 구한다.
여기서, , 는 성능 지수의 파라미터로서 으로 하면 진동 시스템의 역학적 에너지를 최소화하는 제어기를 설계할 수 있다. 이 제어기 설계 문제의 해석적인 해는 Pontryagin’s Maximum(or Minimum) Principle에 의해 구할 수 있으며, 이 때 최적 제어력은 최대 또는 최소의 값만을 선택적으로 사용하는 bang-bang 제어력의 형태로 나타난다. 그러나 이 최적 해는 수반 방정식(co-state equation)을 포함하는 2점 경계치 문제(two-point boundary value problem)를 풀어서 결정되어야 하므로, 실시간 진동 제어에 사용할 수 있는 on-line 제어 법칙을 직접적으로 구현하지 못한다(Kirk, 2004).
전통적으로 이 문제의 실시간 제어를 위한 제어 법칙은 에너지 증감 방향을 고려한 bang-bang 제어 방법과 최적 제어 해에 기반한 제한 최적 제어(clipped-optimal control) 방법이 사용된다. 이 연구에서는 이 두 가지 방법을 비교 기준으로 하여 2.3절에 제시하는 강화 학습 기반 제어기와 성능을 비교한다. 첫 번째로 이 연구에서 사용하는 에너지 방향을 이용한 가변 강성 제어는 다음과 같다.
식 (3)의 제어 법칙은 일 때는 변위의 절대값이 감소하며 원점으로 돌아오는 상태이므로 복원력을 최대화한다. 반대의 경우는 변위의 절대값이 증가하며 원점에서 멀어지는 방향이므로 추가적인 에너지 저장을 최소화하기 위해 최소의 강성을 선택한다. 이 같은 제어 법칙은 최적 bang-bang 제어와 유사한 해를 제공하며 시스템의 역학적 에너지를 지속적으로 감소시킨다(Djajakesukma et al., 2002).
두 번째 제어기인 제한 최적 제어는 다음과 같다.
이 연구에서 식 (4)의 최적 제어 해인 는 식 (1)에서 가변 강성이 0일 때의 단자유도 진동계에 대하여 식(2)의 성능지수 으로 한 LQR(Linear Quadratic Regulator) 최적 해이다(Anderson and Moore, 2007). 식 (4)의 제한 최적 제어는 가변 강성 시스템에 의한 제어력 가 LQR 최적 제어력 와 같도록 하는 를 선택하되, 의 제한 조건을 적용하여 최대 및 최소 제어력이 사용된다. 이후 이 논문에서는 bang-bang 제어기를 BB-I, 제한 최적 제어기를 BB-II라 명명하고 비교 결과를 기술한다.
2.3 강화학습 기반 제어기 설계
이 연구에서 적용한 강화학습 방법은 심층 결정적 정책 경사(Deep Deterministic Policy Gradient, DDPG) 방법이다. DDPG 방법은 연속적인 행동 공간을 다루는 대표적인 강화학습 방법의 하나로서 정책 기반 방법과 가치 기반 방법을 결합한 액터-크리틱(Actor-Critic) 구조를 갖는다(Lillicrap et al., 2015).
식 (1)의 단자유도 시스템에 대하여 DDPG 제어기를 설계하기 위해서는 환경(environment), 에피소드(episode), 보상 함수(reward function), 액터 신경망, 크리틱 신경망이 정의되어야 하며, 학습 알고리즘과 그에 따른 적절한 하이퍼파라미터(hyperparameters)들이 결정되어야 한다.
이 강화학습에서 환경은 제어 대상이 되는 시스템으로 단자유도 시스템의 운동방정식인 식 (1)로부터 정의된다. 환경의 상태(state)는 센서로 측정 가능한 시스템의 상태 변수로서, 여기서는 단자유도 시스템의 변위 및 속도를 상태 로 정의하였다. 강화학습 제어기에 입력으로 사용되는 센서 출력은 변위와 속도로 하였고, 제어기의 출력에 해당하는 행동(action)은 로서 가변 강성으로 정의한다. 즉, 환경은 시간별 행동이 포함된 식 (1)을 시간 적분하여 상태 전이를 시뮬레이션 한다.
이 연구에서 하나의 에피소드는 임의의 초기 조건 에 대하여 미리 설정한 종료 시간 까지의 자유 진동으로 정의하였다. 이는 선형 진동계에서 강제 진동 응답은 임의의 초기 조건에 대한 자유 진동의 합으로 나타낼 수 있다는 원리에 기반한 것으로 임의의 초기 조건에 대한 제어기가 강제 진동 응답의 제어에도 유용한 것에 착안한 것이다.
보상 함수는 식 (2)에 기반하여 다음과 같이 정의하였다.
보상 함수 식 (5)는 식 (2) 성능지수를 정규화하여 이산화한 것으로 이다. 또한 는 임의의 초기 조건 에 대한 성능지수 값의 정규화를 위한 값이다. 이는 해당 초기 조건에 대한 비 제어시의 성능지수 값이다. 이 값은 발산하지 않는 안정한 진동계에서 종료 시간이 무한히 길 때 수렴하는 값으로 다음과 같이 해석 해로 구할 수 있다.
식 (6)에서 는 식 (7)의 Lyapunov 방정식의 해이며, 식 (7)의 시스템 행렬 와 성능 지수 가중행렬 는 다음과 같다.
식 (5)의 정규화된 보상 함수는 임의의 초기 조건에 대하여 동일한 기준으로 보상 함수 값을 계산할 수 있다. 만일 정규화하지 않는다면 초기 조건 값에 따라 서로 다른 보상 함수 값을 가지게 되므로 적절한 학습이 불가능하게 된다.
이 연구에서 사용한 액터 신경망은 연속 상태-행동 공간에서 결정론적 정책을 근사하도록 설계된 피드포워드(feed-forward) 신경망 구조이다. 입력 관측 상태 벡터는 환경 상태와 같은 변위와 속도 응답으로 하였다. 신경망의 첫 계층은 상태 입력의 크기를 단위 벡터로 하는 정규화 계층으로 하여 안정적인 학습을 도모하였다. 이후 신경망은 400개의 뉴런을 갖는 완전연결 계층과 ReLU 활성화 함수, 이어서 300개의 뉴런을 갖는 완전연결 계층과 ReLU 활성화 함수를 차례로 통과하면서 비선형 변환을 수행한다. 마지막으로 행동 차원에 대응하는 완전연결층과 tanh 활성화 함수를 거쳐 출력 범위를 제한하였다. 최종 출력은 스케일링 계층(scaling layer)을 통해 [0,1] 사이로서 최대 강성 범위 내 연속 값을 출력하여 가변 강성값을 결정할 수 있도록 하였다.
크리틱 신경망은 상태 입력 경로(state path), 행동 입력 경로(action path), 그리고 공통 경로(common path)로 구성하였다. 상태 입력 경로에서는 관측 상태 벡터를 입력으로 하여 정규화하고 이후 액터 신경망과 같은 구조의 두 개의 완전연결 계층(400, 300 노드)과 ReLU 활성화 함수를 거쳐 상태 특징(state feature)을 추출한다. 행동 입력 경로에서는 행동 차원을 입력으로 하고 300 노드의 완전연결 계층을 거쳐 행동 특징(action feature)을 출력한다. 이후 두 입력 경로의 결과를 합산 계층에서 합산하고 이어서 ReLU 활성화 함수를 거쳐 주어진 상태-행동 쌍의 행동-가치 함수 값(Q-value)을 근사하는 최종 값을 출력한다. 액터 및 크리틱 신경망 구조는 시행착오를 거쳐 결정하였으며 별도의 최적화 과정을 거치지 않았다.
신경망의 학습은 진화 연산 방법을 사용하는 MATLAB Reinforcement Learning Toolbox의 trainWithEvolutionStrategy() 함수를 사용하였다. 일반적으로 DDPG 방법에서는 액터 신경망과 크리틱 신경망의 학습 파라미터에 대한 미분 값(gradient)를 이용하여 학습을 수행하게 된다. 이 연구에서 사용한 학습 방법은 기본적으로 진화 연산 기반이지만 미분 값 정보를 사용하는 해의 개체를 같이 사용하는 하이브리드 최적화 알고리즘으로서 탐색성과 수렴성을 모두 갖춘 방법으로 평가된다. 다음 Table 1에 학습에 사용한 주요 하이퍼파라미터를 제시하였다.
3. 제어기 설계 결과 및 성능 비교
이 장에서는 2장에서 제시한 단자유도 시스템과 제어 방법들에 대한 수치 예제 및 해석 결과를 제시한다.
3.1 수치 예제 및 제어기 설계 조건
수치 예제로서 식 (1)에 제시한 가변 강성 단자유도 시스템의 질량, 감쇠 및 강성은 고유진동수 1.0Hz, 감쇠비 1%가 될 수 있도록 Table 2와 같이 정하였다.
시스템 강성에 추가되는 가변 강성의 최소값은 0, 최대값은 전체 강성이 시스템 강성의 최대 1.5배까지 변할 수 있도록 로 하였다.
BB-II 제한 최적 제어 방법 및 DDPG 강화 학습 제어에 사용한 식 (2), 식 (9)의 성능 지수 파라미터는 , 로 하였다.
DDPG 제어기 설계에서는 매 에피소드마다 임의로 주어지는 초기 조건에 대하여 학습이 이루어진다. 이 예제에서 임의의 초기조건은 변위 ±0.5m, 속도 ±1.0m/s 이내의 균일 랜덤 분포 샘플을 사용하였다.
3.2 강화학습 기반 제어기 설계 결과
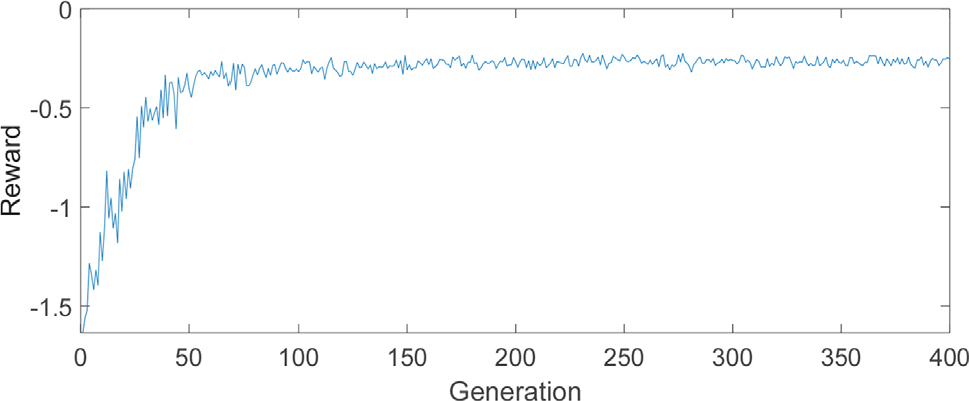
식 (5)의 보상 함수를 최대화하는 DDPG 제어기 신경망의 학습과정을 Fig. 1에 나타내었다. 각 에피소드는 = 0.01초, 종료 시간 = 40초까지의 자유진동으로 하였으며, 한 에피소드의 종료 시에 보상 함수의 평가에 있어서 제어 성공과 실패에 따른 별도의 보상 및 벌칙 값은 사용하지 않았다. 보상 함수 값은 100 세대이후 수렴하는 양상을 보였으며 최종적으로 약 -0.3에 근접하였다. 이는 제시하는 제어기가 비 제어시의 성능지수 값의 약 30% 수준으로 제어할 수 있음을 나타낸다.
3.3 공칭 성능 비교
제어기들의 성능을 비교하기 위해 초기 변위 0.5m, 초기 속도 1.0m/s에 대한 자유진동 제어 응답을 살펴보았다. Fig. 2에 나타낸 바와 같이 BB-I, BB-II, DDPG 제어기 모두 진동 변위 응답을 잘 제어하였다. 세 가지 제어 방법은 매우 비슷한 성능을 보였는데 BB-I 및 BB-II 제어기가 각 주기의 피크에서 미소하게 DDPG 제어기 보다 작은 최대 변위를 보임을 알 수 있다.
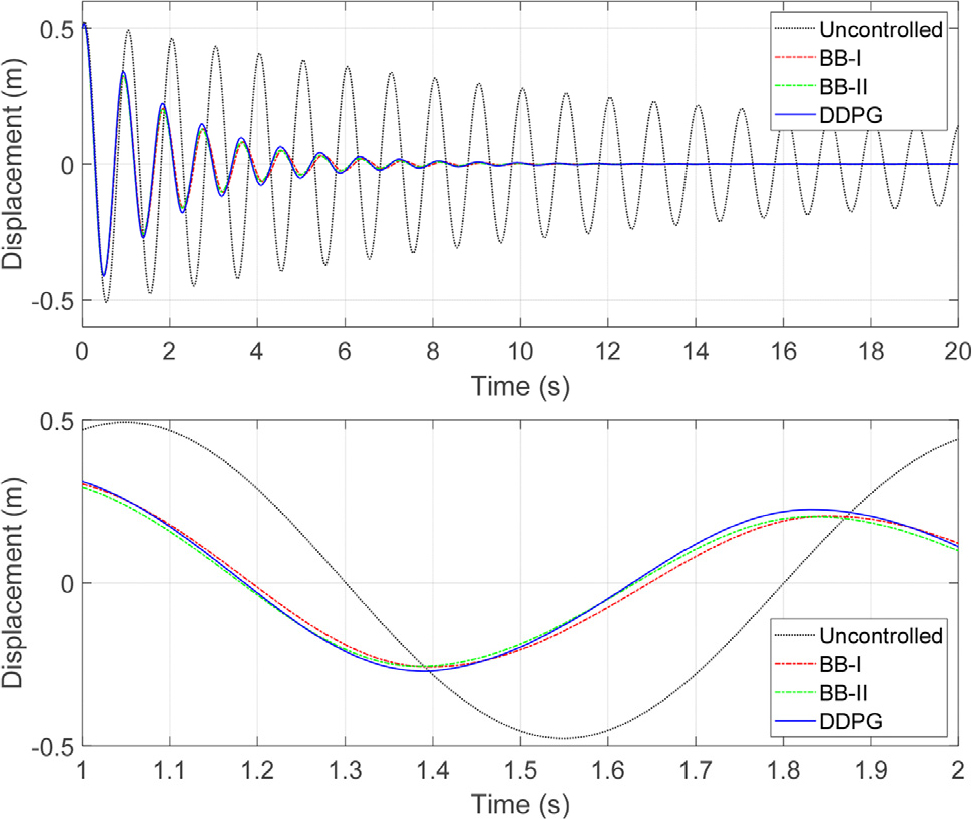
이러한 성능 차이를 정량적으로 판단하기 위해 식 (2)의 성능지수를 조사하였다. 조사 결과 BB-I, BB-II, DDPG 제어기의 성능지수 값은 각각 6.01, 5.92, 6.53으로 평가되었다(Table 3). 또한 같은 초기 조건에 대한 비 제어시의 성능지수 식 (6) 값은 21.75였으며, 이는 진동 에너지 관점에서 볼 때, 각 제어기가 비 제어 시에 비하여 각각 27.6%, 27.2%, 30.0% 수준으로 진동을 저감시킴을 의미한다. 또한 제한 최적 해인 BB-II 제어기의 성능이 가장 좋으며, 강화 학습 DDPG 제어기의 성능이 가장 좋지 않은 것을 확인할 수 있다.
Table 3.
Free vibration performance indices of controllers under different sensor noise levels
| SNR | No noise | 80dB | 40dB | 20dB |
| BB-I | 6.0137 | 6.0138 | 6.1096 | 6.7681 |
| BB-II | 5.9226 | 8.0293 | 8.2318 | 9.2501 |
| DDPG | 6.5263 | 6.5245 | 6.6357 | 7.2608 |
좀 더 직관적인 성능 비교를 위하여 제어시의 성능 지수와 동일한 값을 낼 수 있는 비 제어 시스템의 감쇠비를 찾고 이를 일종의 등가 감쇠비로 하여 비교한다. 이 경우 각 제어기의 등가 감쇠비는 BB-I, BB-II, DDPG 제어기 별로 약 3.68%, 3.74%, 3.38% 임을 알 수 있다.
강제 진동 제어 응답 성능 평가는 각 제어 시스템에 대하여 지반 가속도를 받는 단자유도 진동계의 변위 응답을 비교하였다. 입력 지반 운동은 PGA 0.32g의 El Centro 지진을 사용하였으며 변위 응답을 Fig. 3에 제시하였다. 각 제어기 모두 비 제어시에 비하여 향상된 제어 성능을 보였으며, 자유 진동 제어와 마찬가지로 대부분의 구간에서 미소한 차이로 BB-II, BB-I, DDPG 제어기의 순서로 우수한 제어 성능을 발휘하였다.
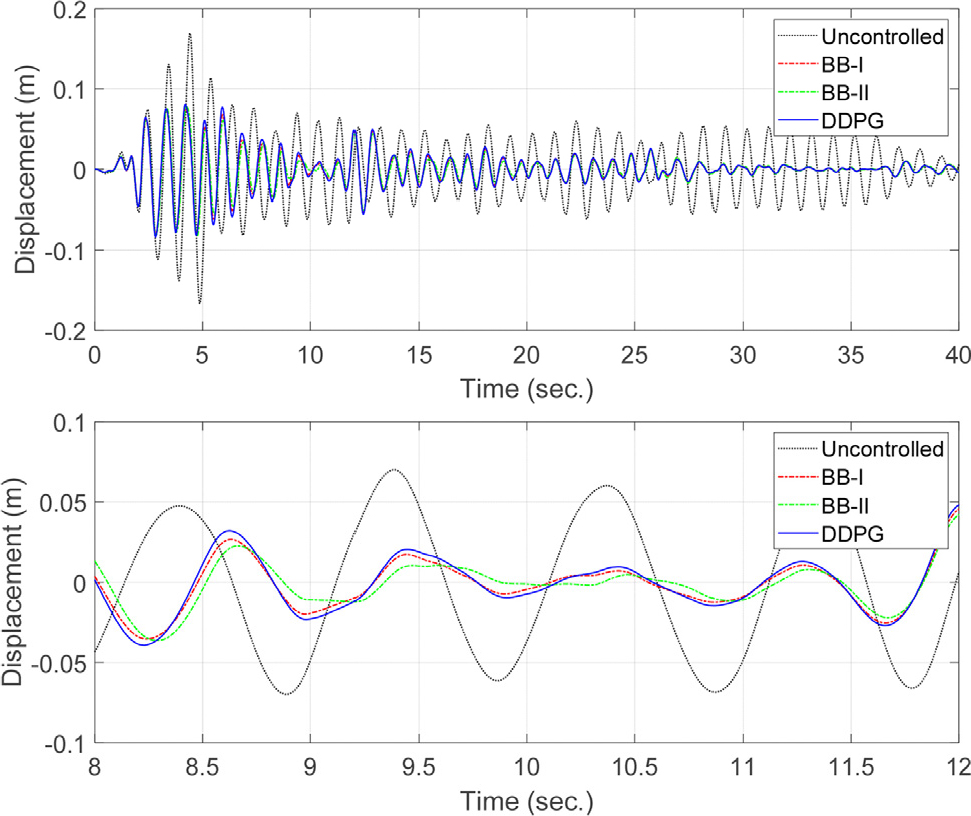
각 제어기 별 성능을 정량적으로 살펴보기 위해 최대 변위 값과 RMS(root mean square) 변위 값을 조사하였다. 비 제어 최대 변위는 16.96cm였으며 BB-I 제어기는 8.08cm, BB-II 제어기는 8.25cm, DDPG 제어기는 8.33cm로 나타났다. 변위의 rms 값은 비 제어시에 4.31cm이고, BB-I 제어기는 2.02cm, BB-II 제어기는 2.00cm, DDPG 제어기는 2.17cm이다. 최대 및 RMS 변위 모두 DDPG 제어기의 성능이 가장 안 좋은 것으로 나타났고 이는 자유 진동 해석의 경우와 동일하다. 다만 BB-I 과 BB-II 제어기의 성능 비교에서는 최대 값의 경우 BB-I 이 BB-II 보다 좀 더 좋은 값을 보였다.
이상의 결과를 종합하여 볼 때, 주어진 단자유도 시스템의 준 능동 제어 문제에 대하여 강화 학습 기반의 DDPG 제어기는 잘 알려진 bang-bang 제어기의 성능과 유사하지만 그에 못 미치는 공칭 제어 성능을 발휘하는 것을 확인하였다.
3.4 강인 성능 비교
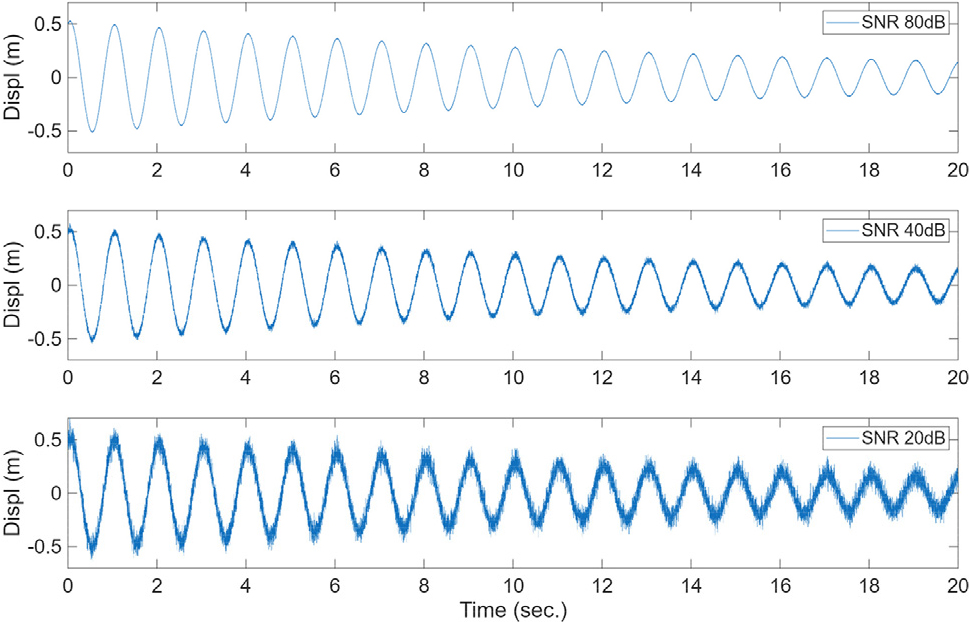
일반적으로 제어기는 공칭 시스템에서 모델링 되지 않는 환경에서도 강인한(robust) 성능을 가지는 것이 중요하다. 이 연구에서는 각 제어기에 대하여 센서 잡음에 대한 강인 성능을 평가하고 비교한다. 비 제어시의 변위 및 속도 센서 응답에 대하여 신호 대 잡음비(SNR)가 각각 80dB, 40dB, 20dB인 경우에 대하여 성능을 조사하였다. 잡음은 백색 가우시안 잡음(White Gaussian Noise)으로 모델링하였다. Fig. 4는 자유진동 시 잡음이 포함 된 변위 센서 신호를 신호 대 잡음비 별로 나타낸 것이다.
센서 신호에 잡음이 있을 때 제어기들의 강인 성능을 비교하기 위해 초기 변위 0.5m, 초기 속도 1.0m/s에 대한 자유진동 제어 응답을 살펴보았다. 예로서 센서 잡음이 없을 때와 SNR 20dB 잡음이 있을 때, 각 제어기의 자유진동 제어 변위 응답 시간이력을 Fig. 5에 표시하였다. Fig. 5에서 보는 바와 같이 모든 제어기는 센서 잡음이 있을 때 제어 성능이 저하되었으며, 특히 BB-II 제어기의 경우 그러한 경향이 크게 나타나 센서 잡음에 대한 강인 성능이 세 제어기 중 가장 좋지 않음을 알 수 있다.
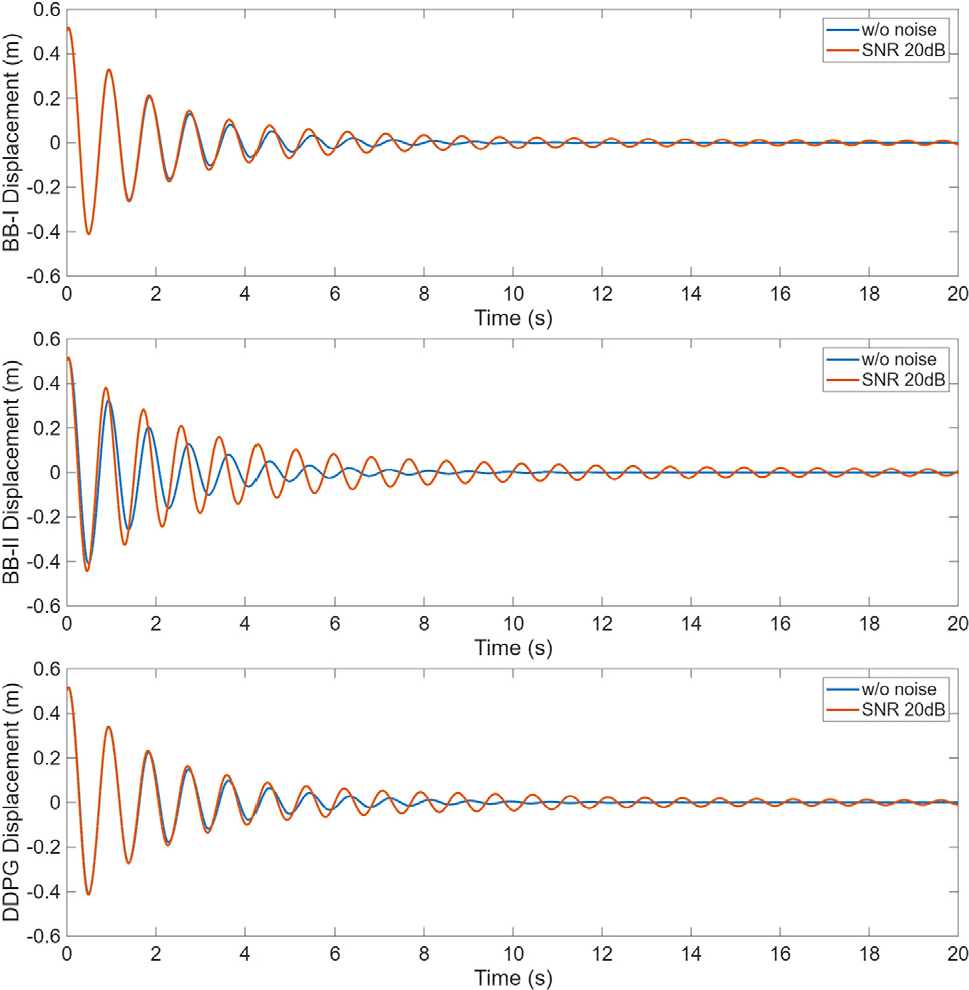
센서 잡음 세기에 대한 각 제어기의 강인 제어 성능을 정량적으로 살펴보기 위해 각 제어기의 자유진동 제어에 대한 식 (2)의 성능 지수 값을 잡음 세기 별로 조사하였다 (Table 3). 식 (2)의 성능 지수 값은 진동 에너지에 상응하는 값이므로 제어 성능이 좋을수록 작은 값을, 나쁠수록 큰 값을 가진다. 해석 결과 Table 3에서 나타낸 바와 같이 잡음의 세기가 증가할수록 각 제어기의 성능 지수 값은 증가하고 있어 제어 성능이 저하됨을 확인할 수 있다. 잡음이 없을 때와 가장 잡음의 세기가 큰 20dB의 경우의 성능 지수 증가율을 비교해 보면, BB-I 제어기는 잡음이 없을 때에 비하여 약 12.54%의 성능 지수 증가율을 보였다. BB-II 제어기는 56.18%, DDPG 제어기는 11.25%의 증가율을 기록하였다. 이 같은 결과는 강인제어 성능에 있어서 DDPG 제어기가 가장 우수하며, BB-II 제어기가 가장 강인제어 성능이 떨어지는 것으로 해석할 수 있다. 흥미로운 사실은 잡음이 없을 때의 자유진동 제어 공칭 성능의 경우 BB-II 제어기가 가장 우수한 제어 성능을 보였으나, 잡음이 포함될 경우에는 모든 잡음 세기에서 가장 안 좋은 제어 성능을 보인 점이다. 이는 공칭 성능이 우수할 지라도 강인 성능은 그렇지 못할 수 있다는 점을 잘 보여주는 예라고 할 수 있다.
성능 지수의 크기를 보면 모든 잡음 세기에서 BB-I 제어기가 가장 우수한 제어 성능을 보인다. 이는 제어 알고리즘이 식(3)에 보인 바와 같이 변위와 속도 곱의 부호에만 의존하기 때문인 것으로 설명할 수 있다. 즉, 센서의 잡음이 있더라도 원래의 변위 및 속도 신호의 부호가 유지되면 잡음이 없을 때와 같은 제어 값을 나타내기 때문이다. 즉, 변위 및 속도 응답이 0에서 잡음 크기 이상으로 충분히 떨어진 값들은 잡음에 의해 그 부호가 바뀔 가능성이 거의 없기 때문일 것으로 보인다.
제한 최적 제어인 BB-II 제어기는 센서 잡음이 있을 때 상대적으로 제어 성능이 크게 저하됨을 알 수 있다. 식 (4)의 알고리즘을 보게 되면 강성의 스위칭을 결정하는 규칙이 변위 및 속도의 크기에 민감한 규칙임을 알 수 있다. 잡음이 들어간 변위 및 속도 신호를 이용하여 이 규칙을 사용하게 되면 최적 값과는 다른 잘못된 판단을 하게 될 가능성이 큰 것으로 판단할 수 있다.
DDPG제어기는 잡음이 없을 때의 공칭 성능은 최적 제어기인 BB-I 및 BB-II에 비하여 떨어지지만, 센서 잡음에 대한 강인 성능은 우수함을 알 수 있다. 센서 잡음이 작게 포함된 80dB 신호의 경우에는 잡음이 없을 때 (J = 6.54)보다 미소하지만 더 작은 성능 지수 값(J = 6.52)을 보이기도 하였다. 이는 DDPG 제어가 사용하고 있는 깊은 신경망이 잡음이 포함된 신호를 입력으로 하여 결정한 제어 출력 값이 결과적으로 더 좋은 제어 성능을 보인 경우이다. 일반적으로 최적 제어 알고리즘은 센서 잡음이 있는 경우 잡음이 없을 때 보다 항상 더 큰 성능 지수 값이 나오게 되지만, 학습으로 결정한 깊은 신경망은 통계적으로는 잡음이 있을 때 성능이 떨어지지만 항상 최적의 값을 주는 것은 아니므로 특정한 잡음 상태에 대해서는 이러한 현상이 나타날 수 있는 것으로 보인다. 또한 DDPG 제어기의 학습에는 일정 정도 센서의 오차를 고려하여 학습하고 있으므로, 센서 잡음이 없는 경우에 대하여 항상 최적 값을 주는 것은 아니라고 할 수 있다.
센서 잡음이 있는 경우 각 제어기의 강제 진동 제어 응답 성능 을 평가하였다. 각 제어 시스템에 대하여 지반 가속도를 받는 단자유도 진동계의 변위 응답을 비교하였다. 입력 지반 운동은 PGA 0.32g의 El Centro 지진을 사용하였다. 센서 잡음의 강도는 자유진동 제어의 경우와 같이 변위 및 속도 센서 응답에 대하여 신호 대 잡음비(SNR)가 각각 80dB, 40dB, 20dB인 경우로 하였다. 잡음은 백색 가우시안 잡음(White Gaussian Noise)으로 모델링하였다.
각 제어기 별 성능을 정량적으로 살펴보기 위해 최대 변위 값과 RMS변위 값을 조사하였다. 각 제어기에 대한 해석 결과는 Table 4에 보였고, 예 로서 신호 대 잡음비가 20dB인 경우의 변위 응답 시간 이력 비교를 Fig. 6에 보였다. 해석 결과 최대 응답 성능은 센서 잡음이 없을 때나 있을 때 모두 대체적으로는 BB-I, BB-II, DDPG 제어기 순으로 응답이 작게 나타났다. 다만 중간 정도의 잡음 세기인 SNR 40dB의 경우에는 DDPG 제어기의 최대 응답이 8.49cm로서 BB-II 제어기 보다 좋은 성능을 발휘했다. RMS 응답의 경우에도 비슷한 경향을 보이고 있으며 가장 센서 잡음이 큰 20dB의 경우에 BB-II 가 가장 좋은 응답을 보이는 것도 확인할 수 있었다.
Table 4.
Comparison of maximum and RMS displacement responses (cm) of the control systems subjected to the El Centro earthquake record (PGA = 0.32g) with varying sensor noise levels

이러한 결과는 센서잡음이 있는 경우 자유진동 제어의 강인 성능이 우수한 것으로 나타났던 DDPG 제어기가 특정 입력에 대한 강제진동에서는 최대 응답과 RMS 응답을 지표로 했을 때, 더 우수한 성능을 보이지 않았다는 것을 나타낸다. 그러나 Fig. 6에서 보인 바와 같이 27초 이후 구간에서는 DDPG 및 BB-II 제어기가 더 좋은 제어 응답을 보이는 구간도 관찰할 수 있다.
4. 토의 및 결론
이 연구에서는 강화학습 기반 제어기와 전통적인 제어기의 성능을 비교함으로써, 강화학습을 이용한 구조 진동 제어 시스템의 특성을 분석하였다. 이를 위해 단자유도 가변 강성 시스템을 대상으로 제어기 설계 및 수치 해석을 수행하였다. 강화학습 제어기로는 연속 제어 입력을 직접 다룰 수 있는 DDPG 방법을 적용하였으며, 비교 대상으로는 스위칭 법칙에 기반한 bang-bang 제어(BB-I)와 제한 최적 제어(clipped-optimal control, BB-II)를 사용하였다. 성능 평가는 자유 진동 및 El Centro 지진 가속도에 의한 강제 진동 응답을 대상으로 수행하였다.
해석 결과, 센서 잡음이 없는 공칭 조건에서 DDPG 제어기는 bang-bang 제어기와 유사하나 전반적으로 다소 낮은 제어 성능을 보였다. 센서 잡음이 존재하는 경우에는 자유 진동 제어에서 DDPG 제어기가 가장 우수한 강인 성능을 나타낸 반면, 강제 진동 제어에서는 기존 제어기 대비 뚜렷한 성능 우위를 보이지 못하였다.
이러한 결과는 다음과 같은 시사점을 제공한다. 첫째, 동일한 보상 함수와 동일한 시스템 조건 하에서 깊은 신경망 기반 강화학습 제어기가 공칭 성능 측면에서 수학적 최적해 또는 규칙 기반 제어기의 성능을 초과하기는 어렵다. 이는 문제 정의상 수학적 최적해가 이미 최적 성능을 보장하기 때문이며, 강화학습은 이상적인 환경 모델과 충분한 탐색이 확보되는 경우에 한해 최적 제어 해와 동일한 정책으로 수렴할 수 있음이 기존 연구에서 보고된 바 있다(Bradtke, 1992). 본 연구 결과 역시 실제 문제 설정에서 강화학습 제어기가 공칭 최적해보다 낮은 수준의 성능을 보일 가능성이 있음을 확인하였다.
둘째, 강화학습 기반 제어는 비선형성이나 불확실성이 존재하는 실제 시스템에서 공칭 최적 제어기 수준에 근접하거나 이를 상회할 잠재력을 가지지만, 이를 달성하기 위해서는 공칭 제어기 설계와는 차별화된 환경 모델링과 보상 함수 설계가 필수적이다. 본 연구에서는 비교적 단순한 비선형 가변 강성 모델과 센서 잡음만을 고려한 환경에서 DDPG 제어기를 학습시켰으며, 그 결과 일정 수준의 강인 성능은 확보되었으나 기존 최적 또는 규칙 기반 제어기를 일관되게 상회하지는 못하였다. 이는 실제 시스템의 불확실성을 충분히 반영하지 못한 환경 모델과 보상 함수 설정이 강화학습 제어기의 기대 성능을 제한할 수 있음을 시사한다.
이상의 결과를 바탕으로 향후 강화학습 기반 진동 제어의 효과를 극대화하기 위해 다음과 같은 과제가 요구된다. 첫째, 외력 특성, 액추에이터 및 센서 동역학, 구조물의 비선형 거동과 불확실성을 충분히 반영할 수 있는 고정밀 시뮬레이션 환경의 구축이 필요하다. 둘째, 진동 제어 목적에 특화된 신경망 구조와 보상 함수의 개발이 요구된다. 마지막으로 강화학습의 성능은 학습 데이터의 구성에 크게 의존하므로, 지진이나 풍하중 특성을 반영한 입력 하중 데이터의 체계적인 구성 또한 중요한 연구 과제로 남아 있다.
