

1. 서 론
2. 본 론
2.1 FETI-local 알고리즘
2.2 선택적 역행렬 성분 계산
2.3 다중 프론탈 기법 적용
2.4 개선된 FETI-local 알고리즘
2.5 수치예제 결과 및 고찰
3. 결 론
1. 서 론
병렬 계산 장비의 발달에 힘입어 대자유도 유한요소 구조해석에 대한 수요는 점진적으로 증가해 왔다. 그러나 유한요소 구조해석에서 통상적으로 활용되는 행렬 연산 알고리즘 중 상당수는 대자유도 해석 병렬화에 있어 한계를 보인다. 예를 들어, 직접해법(direct solution) 기반 희박행렬 연산 알고리즘의 계산 비용은 2차원 판(plate), 3차원 솔리드(solid) 요소일 경우 각각 자유도 수의 1.5, 2제곱에 비례한다(Davis, 2006). 이러한 기하급수적인 계산 비용의 증가는 병렬 대자유도 해석의 확장성(scalability)을 저해한다. 따라서 유한요소 방정식의 별도 정식화를 통한 병렬 연산 알고리즘 및 적용 방법이 제시되었다.
영역분할(domain decomposition) 기법은 전체 에너지 방정식을 각 부영역(subdomain) 에너지 및 부영역 간 경계(interface) 에너지의 합으로 정식화하며, 부영역의 독립성으로 인해 병렬 계산에 적극적으로 활용되었다. Farhat과 Roux(1991)은 비중첩(non-overlapping) 영역분할 기법의 일종인 유한요소 분할 및 합성법(FETI: finite element tearing and interconnecting)을 제시하였으며, 전역(global) Lagrange 승수를 통해 부영역 간 경계문제를 정의하였다. 이후 Park 등(1997)은 국부(local) Lagrange 승수 기반의 A(algebraically partitioned)-FETI 알고리즘을 제시하였다. 이어서 성긴 절점(coarse node) 및 전역 Lagrange 승수에 기반한 FETI-DP(dual-primal) 알고리즘이 개발되었으며(Farhat et al., 2001), 이는 현재에도 가장 각광 받는 영역분할 기법 중의 하나다.
한편, 국부 Lagrange 승수 기반 FETI 알고리즘의 개발도 지속되었다. Bauchau(2010)는 국부 Lagrange 승수 및 성긴 절점 기반의 부영역 간 경계문제에 벌칙 계수(penalty coefficient)를 추가하여 부영역 랭크(rank) 부족 해소 및 경계문제의 예조건화(preconditioning)를 도모하였다. 이는 이후 FETI-local로 명명되었으며, 직접해법 기반 알고리즘을 바탕으로 판, 쉘(shell) 유한요소 병렬 해석에 활용되었다(Gong et al., 2017; Kwak et al., 2012; 2014). 해당 문헌은 부영역별 행렬 연산을 병렬 프로세서(processor)가 분담하여 독립적으로 수행하고 경계 자유도 연산을 호스트(host) 프로세서에서 수행하는 방식을 취하였다. 그러나 이러한 접근은 3차원 솔리드 유한요소 해석으로의 확장 시 대폭 증가하는 경계 자유도로 인해 상당한 계산 비용을 초래하였다(Joo et al., 2020). 최근 Gong 등(2022)은 직접해법을 Jacobi 예조건화 켤레 기울기법(conjugate gradient method) 기반 반복해법(iterative solution)으로 변경하여 계산 시간 및 메모리의 절감을 도모했으나, 예조건 행렬의 고도화 등 필요 추가 연구가 산적해 있다.
최근 영역분할 연구 동향은 반복해법 기반 알고리즘에 집중되어 있으나, 희박행렬 인수분해(factorization) 등 직접해법의 내용을 상당 부분 차용한다. 또한, 직접해법 기반 알고리즘은 반복해법 기반 알고리즘보다 행렬 조건 수(condition number)의 제약을 적게 받는 등의 장점으로 인해 특정 상황에서 여전히 선호된다(Tak et al., 2013). FETI-local 알고리즘 고도화의 일환으로, 본 논문은 직접해법 기반 FETI-local 병렬 해석의 개선 방안을 소개한다. 선택적 역행렬 성분 계산 등 최신 직접해법 기반 희박행렬 연산 알고리즘의 기능을 적극적으로 도입하였다. 또한, 병렬 다중 프론탈(multi-frontal) 기법을 사용하여 기존 단일(serial) 프로세서 기반 경계 자유도 해석 단계를 병렬 프로세서 과정으로 변경하였다. 이후 개선 알고리즘의 성능을 확인하였다.
2. 본 론
이 장에서는 정적 구조물을 대상으로 한 FETI-local 알고리즘의 지배방정식 및 흐름도를 간단히 소개한다. 이후 선택적 역행렬 성분 계산, 병렬 다중 프론탈 기법 도입 등 직접해법 기반 FETI-local 해석 과정 개선 방안을 제시한다.
2.1 FETI-local 알고리즘
2.1.1 정적 구조 지배방정식
FETI-local 알고리즘에 의한 부영역 간 경계문제 정의는 Fig. 1과 같다. 번째 부영역 의 경계 변위 와 이와 연관된 성긴 절점 변위 간에 연속조건이 정의된다. 위 두 성분은 국부 Lagrange 승수에 의한 하중 을 주고받는다. 이때 는 부영역 의 변위이며, 는 내의 경계 변위를 추출하는 Boolean 행렬이다. 는 전체 성긴 절점 변위이며, 는 중 부영역 와 연관된 성분을 추출하는 Boolean 행렬이다. 에너지 방정식 서술 시, FETI-local은 연속 조건 및 국부 Lagrange 승수에 의한 에너지 성분에 벌칙 계수 를 각각 부여한다. 이를 기반으로 한 부영역 전체 퍼텐셜 에너지 의 합 은 아래와 같다(Bauchau, 2010; Gong et al., 2022).
는 전체 부영역 수이며 는 부영역 에 작용하는 외력 하중이다. 식 (1)에 최소 퍼텐셜 에너지 원리를 적용하여 아래 식 (3)과 같은 정적 구조 평형 방정식을 도출한다. 본 논문에선 벌칙 계수에 대해 임을 가정하였다.
이때, 이다. 는 크기 의 단위 정방행렬이며, 는 부영역 와 연결된 성긴 절점 자유도 수이다.
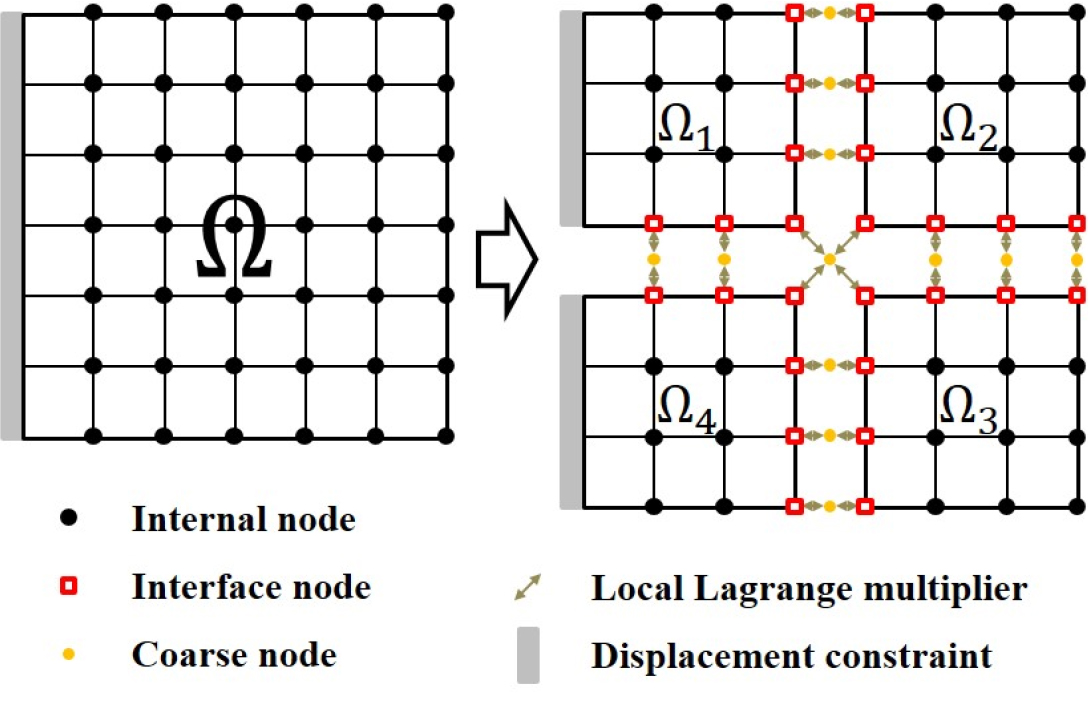
2.1.2 경계 자유도 연산(Step I, II)
블록(block) 행렬 연산을 통해 식 (3)을 성긴 절점 변위 에 대해 정리하면 아래와 같다.
식 (5)는 FETI-local 알고리즘의 경계문제 정의이다. 이때, 이며 이다. 이는 요소 강성행렬 및 요소 하중 벡터 을 갖는 개 초요소(super- element)의 정적 구조 평형 방정식과 같다. 이때, Boolean 행렬 는 연결 행렬(connectivity matrix)의 역할을 한다.
식 (5)의 를 직접해법에 기반하여 계산할 경우, 부영역별 경계 강성행렬 을 도출하는 선행 과정이 필요하다. 이는 희박행렬 의 인수분해 및 역행렬 성분 계산을 요구하며, 상당한 비용을 요구한다. 부영역별 경계 하중 벡터 의 경우 의 인수분해 결과를 활용할 경우 비교적 수월하게 계산할 수 있다. 이러한 및 의 계산 과정을 본 논문에선 Step I이라 명명하였다.
이후 부영역별 경계 강성행렬 및 하중 벡터를 조립(assemblage)하여 성긴 절점 변위 를 계산하며, 이 과정을 Step II이라 명명하였다. 앞서 언급하였듯, 판, 쉘 요소 기반의 영역분할 해석을 동일 전역 자유도 수를 지니는 3차원 솔리드 요소 기반 해석으로 확장할 경우 경계 자유도 수는 대폭 증가한다(Joo et al., 2020).
2.1.3 부영역별 자유도 연산(Step III)
전역 성긴 절점 변위 를 계산한 이후엔, 부영역별 변위 를 부영역별 성긴 절점 변위 를 통해 독립적으로 계산한다. 식 (3)에 따르면, 부영역 내 변위 계산 과정은 아래와 같으며, 본 논문에선 이 과정을 Step III이라 명명하였다.
앞서 Step I에서 행렬 의 인수분해를 수행했으므로, 이를 활용할 경우 Step III의 계산 비용은 다른 과정에 비해 미미하다.
2.2 선택적 역행렬 성분 계산
식 (5)에서 확인할 수 있듯, 직접해법 기반 FETI-local 알고리즘은 부영역별로 을 계산하는 것을 요구한다. 그러나, 해당 행렬의 도출을 위해 강성행렬의 역행렬 내 모든 성분을 계산하는 것은 상당히 비효율적이다. 행렬 가 Boolean 행렬 및 단위행렬 로 구성된 점을 활용하면 역행렬 중 필요 성분을 파악할 수 있다.
가 대칭행렬일 경우, 이를 내부 및 경계 자유도 성분으로 나누면 아래와 같다.
는 부영역 의 내부 변위 자유도 수이다. 식 (6)을 통해 행렬 을 표현하면 아래와 같다.
Boolean 행렬 는 대상 행렬 앞에서 작용할 경우(), 행렬()의 행(row) 중 성긴 절점 자유도와 연관된 행을 추출한다. 뒤에서 작용할 경우(), 행렬()의 열(column)을 마찬가지로 추출한다. Fig. 2는 일 때 Boolean 행렬 연산 예시이다. 각 곱셈 연산 시 추출되는 행렬 성분 중 상삼각(upper-triangle) 성분이 표시되어 있다. 예시의 경우 의 169개 성분 중 21개 성분만으로 행렬 를 도출한다. 일반적인 경우, 총 개 성분 중 개 성분만을 통해 행렬 의 계산이 가능하다. 따라서, 본 논문에선 내 개 성분을 선택적으로 계산하여 을 도출하는 방법으로 Step I의 개선을 도모하였다.
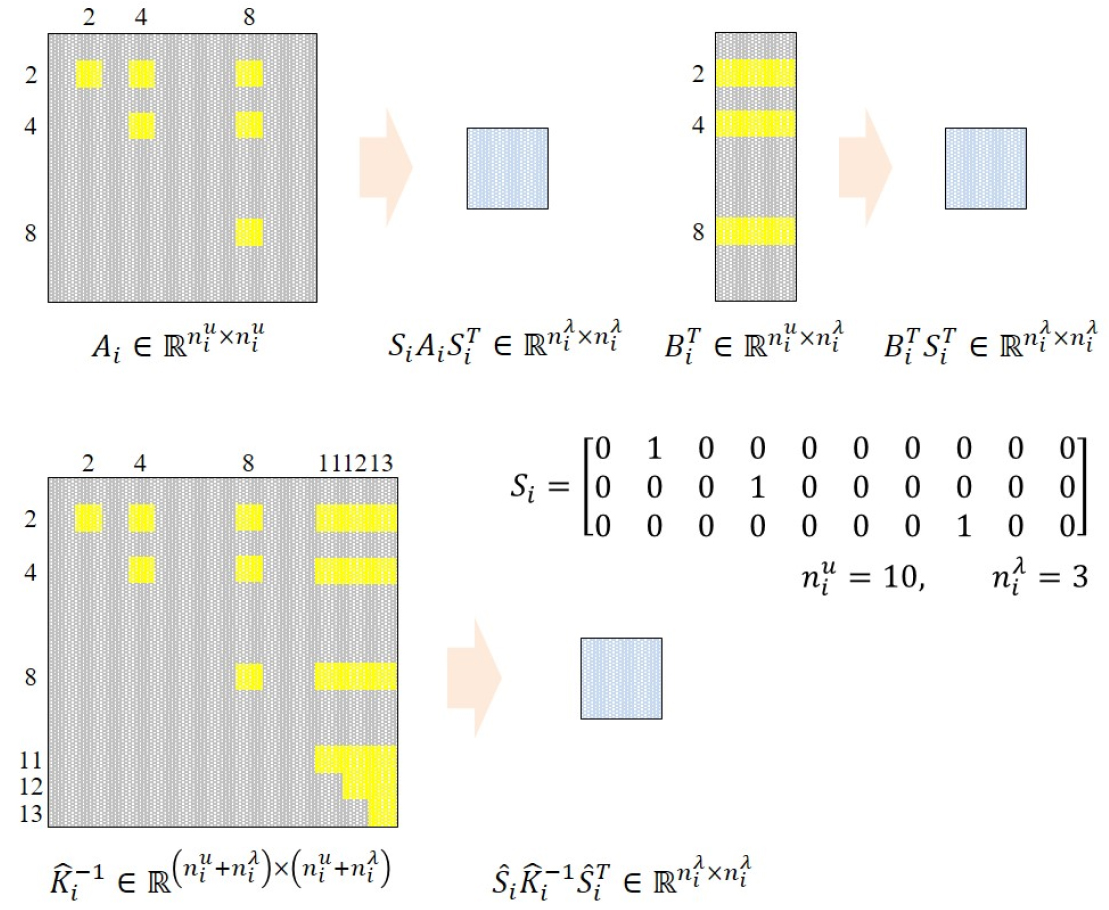
최근 PARDISO(Bollhöfer et al., 2019), MUMPS(Amestoy et al., 2019) 등 많은 수의 직접해법 기반 희박행렬 라이브러리가 선택적 역행렬 성분 계산 기능을 지원하며, 이에 관한 연구가 지속되고 있다. 본 논문은 MUMPS 5.5.0을 도입하여 해당 기능을 구현하였다.
Step I에서 MUMPS는 단일 프로세서별로 실행되었으며, 우선 행렬 의 인수분해를 수행하였다. 이때, 희박행렬 는 성분별로 행렬 색인을 지니는 좌표 형식(coordinate format)으로 저장되었다. 이후 인수분해 결과를 바탕으로 필요 역행렬 성분을 순차적으로 계산하였고 부영역 경계 강성행렬 을 구성하였다. 인수분해 결과는 Step I의 부영역 경계 하중 벡터 의 계산 및 Step III의 최종 변위 계산에서 또한 활용되었다. 자세한 과정은 2.4절에 설명되어 있다.
2.3 다중 프론탈 기법 적용
직접해법 기반 FETI-local 알고리즘의 Step II는 부영역 경계 강성행렬 및 하중 벡터를 바탕으로 전역 경계 강성행렬 및 하중 벡터를 조립하고 성긴 절점 변위 를 계산하는 과정이다. 기존 Step II는 각 프로세서에서 계산한 부영역 정보를 호스트 프로세서로 전송한 뒤, 해당 프로세서에서 조립 및 성긴 절점 변위 계산을 수행하는 방식이었다(Gong et al., 2017; Joo et al., 2020; Kwak et al., 2012; 2014). 그러나 이러한 방식은 호스트 프로세서의 계산량 및 메모리 과다를 유발한다. 본 논문에선 단일 프로세서의 계산량 집중 완화 및 Step II의 병렬화를 위해 MUMPS의 다중 프론탈 행렬 연산 기능을 도입하였다.
다중 프론탈 기법 적용 시 분산 저장 형식을 사용하였다. 우선 Step I에서 계산한 부영역 경계 강성행렬 및 하중 벡터의 행렬 및 벡터 색인을 생성하였다. 이때 색인은 Step I과 같이 좌표 형식이지만 전역 경계 행렬식 (5)을 기준으로 하였다. 분산 저장 형식은 동일한 행렬 혹은 벡터 색인이 발생하면 이를 합 연산으로 취급한다. 따라서 호스트 프로세서에 부영역 정보를 전송하지 않고 병렬 프로세서상에서 전역 경계 강성행렬 및 하중 벡터 조립을 구현하는 것이 가능하다. 이러한 분산 저장 형식은 호스트 프로세서의 메모리 요구량을 절감하며, MUMPS뿐만 아니라 PARDISO 등 많은 수의 희박행렬 라이브러리에서 지원한다. Fig. 3는 2개의 프로세서가 각각 2개의 부영역 경계 강성행렬 및 하중 벡터를 지닐 때 전역 경계 강성행렬 및 하중 벡터 분산 저장 예시를 설명한다.
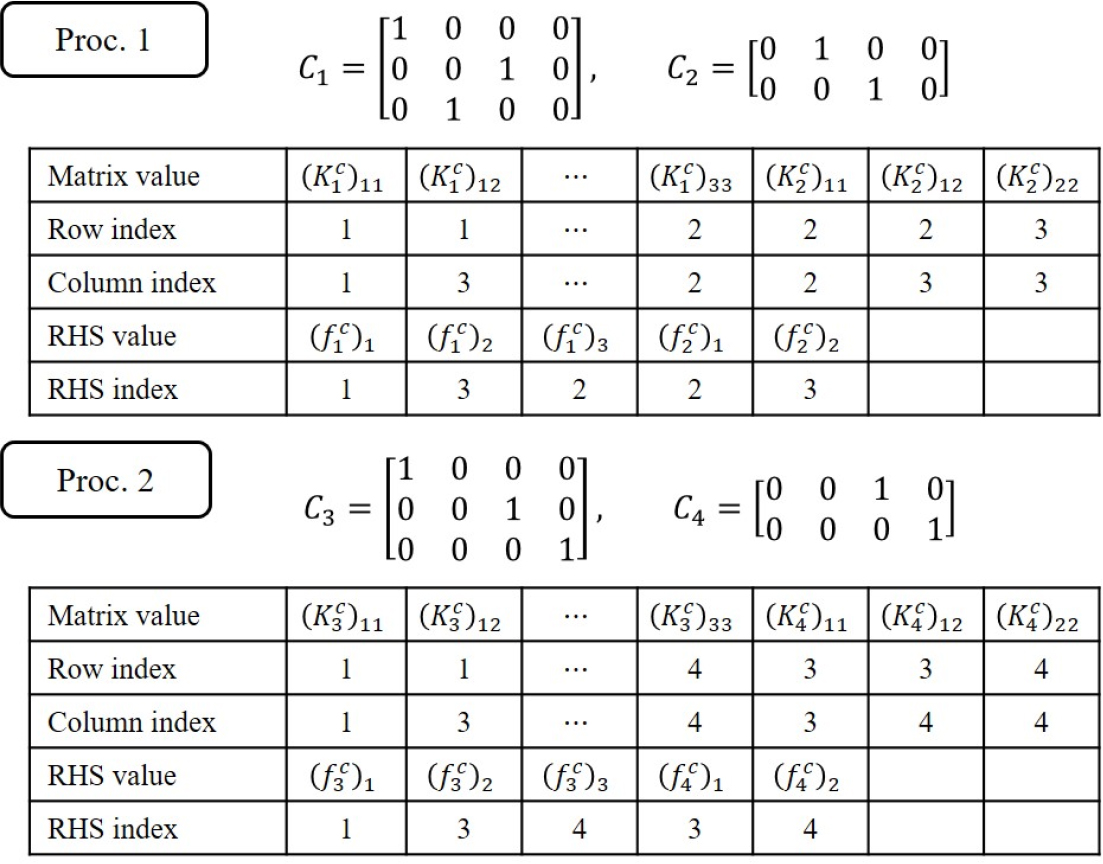
전역 경계 강성 및 하중의 분산 저장 이후 MUMPS를 통해 식 (5)를 병렬 프로세서상에서 계산하였다. 이때, 그래프 분할 라이브러리인 METIS 5.1.0(Karypis and Kumar, 1998)를 별도로 연동하여 MUMPS의 행렬 성분 분석 단계에서 사용하였다. 계산된 성긴 절점 변위 는 각 부영역에 꼴로 할당되어 Step III의 부영역별 변위 계산에 사용되었다.
2.4 개선된 FETI-local 알고리즘
앞선 내용을 바탕으로 개선된 FETI-local 알고리즘의 흐름도는 Fig. 4와 같다. 우선, 유한요소로 이산화된 해석 대상의 영역을 METIS를 이용해 분할하였다. Fig. 4의 경우 부영역 개수는 16개이다. 이후 부영역 정보를 프로세서에 균일하게 할당하였다. Fig. 4는 프로세서가 8개이며, 각 프로세서당 2개의 부영역이 할당된 경우이다.
이후 Step I에 진입하였다. Step I은 프로세서 간 통신 없이 독립적으로 이루어졌다. 우선 부영역 행렬 을 인수분해하였다. 이후 2.2절의 내용과 같이 선택적 역행렬 성분 계산을 수행하여 을 도출하였다. 부영역 경계 강성행렬 는 을 연산함으로써 계산하였다. 부영역 경계 하중 벡터 는 앞선 의 인수분해 결과를 바탕으로 방정식 을 계산한 후, 와 같이 도출하였다. Step I의 인수분해, 선택적 역행렬 성분 계산, 계산에 필요한 행렬 연산은 각 프로세서에서 단일 MUMPS를 통해 수행되었다. 이때 단일 MUMPS의 실행은 개별 MPI(message passing interface) 커뮤니케이터(MPI_COMM_SELF)를 입력하여 구현되었다.
Step II에선 Fig. 3과 같이 및 의 분산 저장 양식 색인을 생성함으로써 전역 경계 방정식 (5)에 필요한 항을 구축하였다. 이후 전역 경계 강성행렬 의 인수분해를 수행하고, 성긴 절점 변위 를 계산하였다. Step II의 인수분해 및 성긴 절점 변위 의 계산은 병렬 MUMPS를 통해 수행되었다. 이때, 병렬 MUMPS의 실행은 전역 MPI 커뮤니케이터(MPI_ COMM_WORLD)를 입력하여 구현되었다. 즉, Step II에서 프로세서 간 통신이 발생하였다.
Step III에서 프로세서별로 할당된 부영역 성긴 절점 변위 를 이용해 부영역 정적 구조 방정식 (6)을 계산하였다. 이때, 앞서 Step I에서 수행한 행렬 의 인수분해 결과를 활용하였다.
2.5 수치예제 결과 및 고찰
이 장에서는 기존 직접해법 기반 FETI-local 알고리즘 대비 본 논문에서 제시한 알고리즘의 계산 성능 개선을 검증한다. 또한, 대자유도 구조 해석 예제를 통해 알고리즘의 적용성을 확인한다.
성능 검증을 위한 프로그램은 Window 10 운영체제상에서 FORTRAN90 언어 기반으로 구현되었다. 실수 및 정수 자료형의 경우 각각 배수 정밀도(64bit) 실수 및 32bit 정수가 사용되었다. 계산 사양은 데스크톱 컴퓨터 사양으로, Intel® Core™ i9-10900KF 3.70GHz 프로세서 및 4개의 삼성 DDR4 PC4- 25600 32GB 메모리가 장착되었다. MPI 통신은 Intel MPI를 통해 구현되었다.
2.5.1 계산 성능 검증
기존 및 개선 알고리즘의 동등한 비교를 위해, 기존 알고리즘의 프로그램은 선택적 역행렬 성분 계산 및 Step II 병렬화 외에 개선 알고리즘과 동일하게 구성하였다. 즉, Fig. 4의 선택적 역행렬 성분 계산은 기존의 전체 역행렬 성분 계산으로 대체되었다. Step II는 호스트 프로세서에 전역 경계 행렬식 (5)의 정보를 전송하고 해당 프로세서 내에서 연산을 수행하는 방식으로 대체되었다.
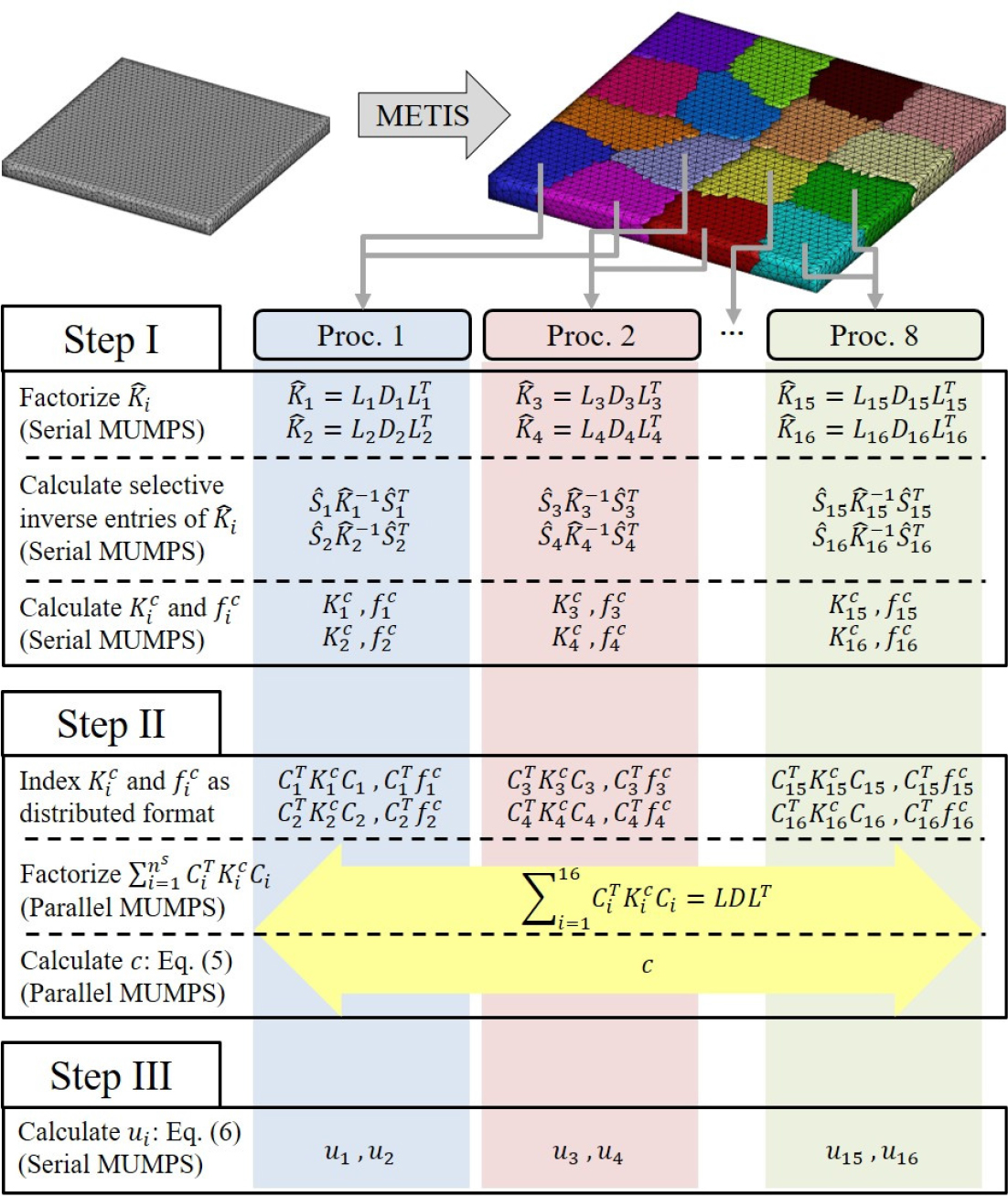
Fig. 5와 같이 균열이 있는 탄소 섬유/에폭시 시편 예제를 대상으로 FETI-local 알고리즘의 계산 성능을 확인하였다. 시편의 한쪽 끝은 고정단이며, 반대쪽엔 인장 변위 경계조건이 가해졌다. 또한, 옆면에는 1/4 대칭 해석을 위한 변위 경계조건이 부여되었다. 유한요소 이산화는 약 64만 개의 변위 자유도 및 약 118만 개의 사면체 솔리드 요소로 구성되었다. 예제에 대한 자세한 설명은 참고문헌(Gong et al. 2022)에 기술되어 있다.
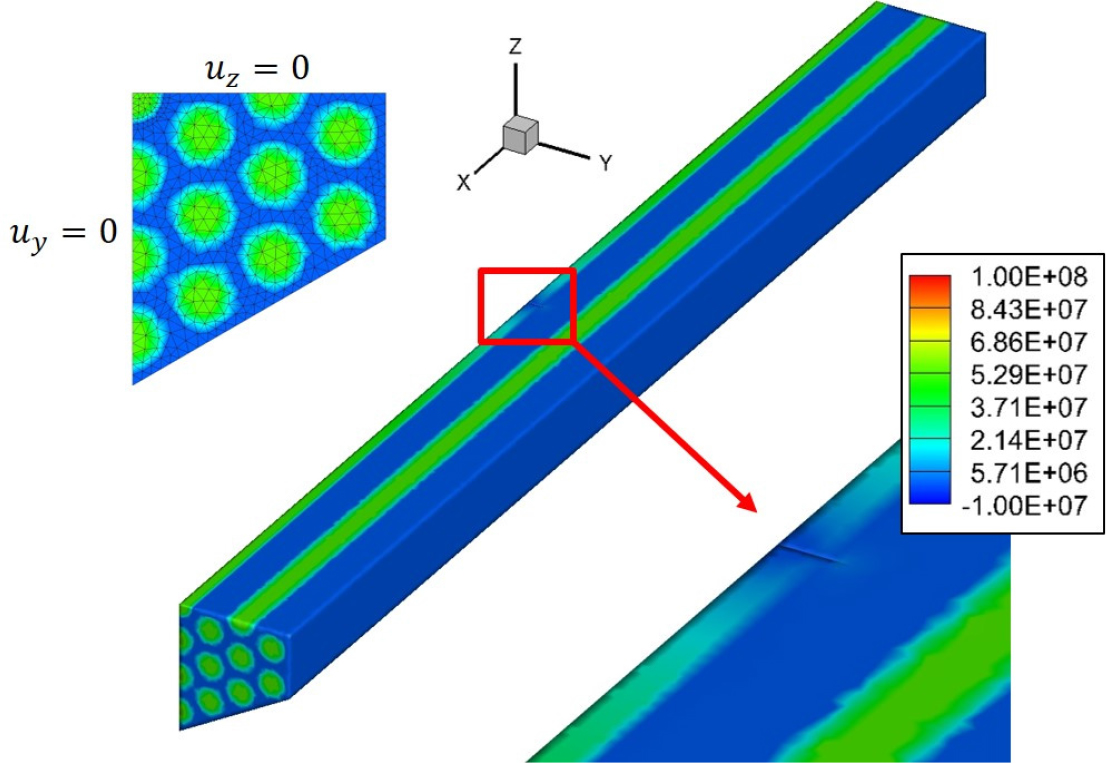
Fig. 6과 같이 부영역 수 64, 128개인 경우에 대해 계산이 수행되었으며, 각 경우의 성긴 절점 자유도 개수는 각각 약 8만, 11만 개이다. 프로세서 수를 1개부터 8개까지 변경하여 계산 시간을 확인하였다.
Table 1은 Step I부터 III까지의 총 계산 시간을 부영역 수, 프로세서 수별로 정리한 것이다. 본 논문에서 개선한 FETI-local 알고리즘은 기존 대비 최대 97.8%의 계산 시간 감소를 달성함을 확인하였다. 전반적으론 97% 내외의 계산 시간 감소가 이루어졌다.
Table 1.
Carbon fiber/epoxy specimen: total computational time and reduction
Fig. 7은 총 계산 시간 중 각 단계에 소요되는 시간을 분류한 것이다. 알고리즘 개선에 따른 계산 속도 향상이 가장 많이 이루어진 과정은 Step I으로, 이는 선택적 역행렬 성분 계산의 성능을 방증한다. 기존 알고리즘의 Step II는 단일 프로세서 연산이므로, 프로세서 수와 관계없이 일정한 계산 시간을 보였다. 반면에. 본 논문에서 제시한 FETI-local 알고리즘의 Step II는 다중 프론탈 기법 기반 병렬 프로세서 과정이므로, 프로세서 수에 따라 계산 시간이 감소하였다. 그러나 Step I 및 III와는 달리 Step II는 프로세서 간 통신이 발생하는 과정이므로, 프로세서 수가 증가함에 따라 계산 속도 향상 정도가 감소함을 확인하였다. Step III의 경우 기존 및 본 논문에서 제시한 FETI-local 알고리즘상에서 동일하므로, 유사한 계산 소요시간을 보였다.
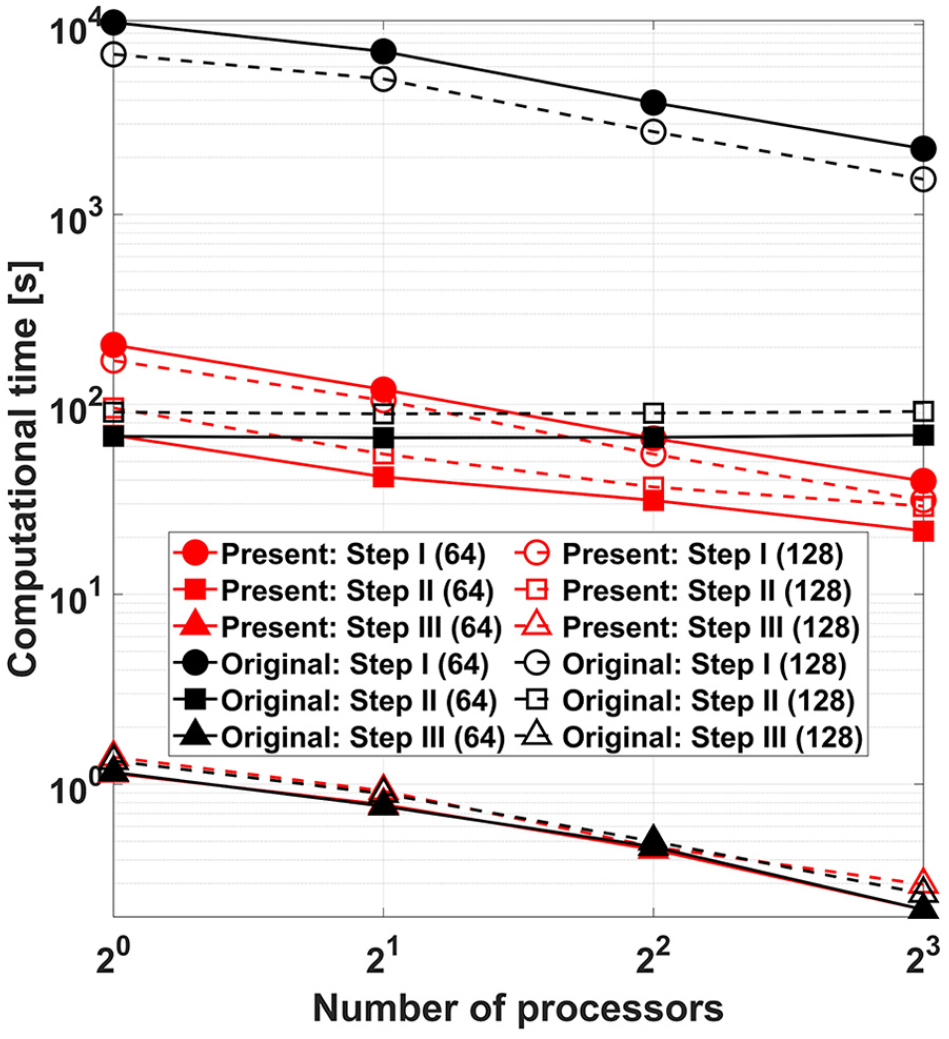
부영역 수에 따른 계산 시간의 경우, 부영역 수 증가에 따른 성긴 절점 변위 및 전역 경계 행렬식 (5)의 자유도 증가로 인해 Step II 계산 시간이 증가하였다. 반면 Step I은 부영역 수 증가에 따라 계산 시간이 감소하는 양상을 보였다. 이는 프로세서별 부영역 수 증가에 따른 계산 비용 증가보다 부영역별 역행렬 계산 비용 감소의 영향이 크다는 것을 의미한다.
계산 시간 감소에 이어 확장성의 개선 여부를 확인하였다. 확장성은 프로세서 수 증가에 따른 계산 시간의 감소 능력을 의미하며, 가속 지표(speed-up)을 통해 확인할 수 있다. 이때 가속 지표는 단일 프로세서 계산 시간과 병렬 프로세서 계산 시간 간의 비율로 정의된다. 사용자는 프로그램의 확장성을 통해 프로세서 추가 도입 시 계산 시간의 감소 정도를 예상할 수 있다.
Fig. 8은 가속 지표를 부영역 수 및 프로세서 수별로 정리한 것이다. 본 논문에서 개선한 FETI-local 알고리즘은 기존 대비 최대 23.8%의 가속 지표 상승을 달성함을 확인하였다. 부영역 수에 따른 유의미한 가속 지표의 변화는 확인되지 않았다. Table 2는 프로세서 수 증가에 따른 가속 지표 증가 양상을 정리한 것이다. 기존 알고리즘의 경우 프로세서 수 증가에 따른 가속 지표 증가 양상이 불규칙적인데 반하여, 본 논문에서 개선한 알고리즘은 비교적 안정적인 가속 지표 증가 양상을 보임을 확인하였다.
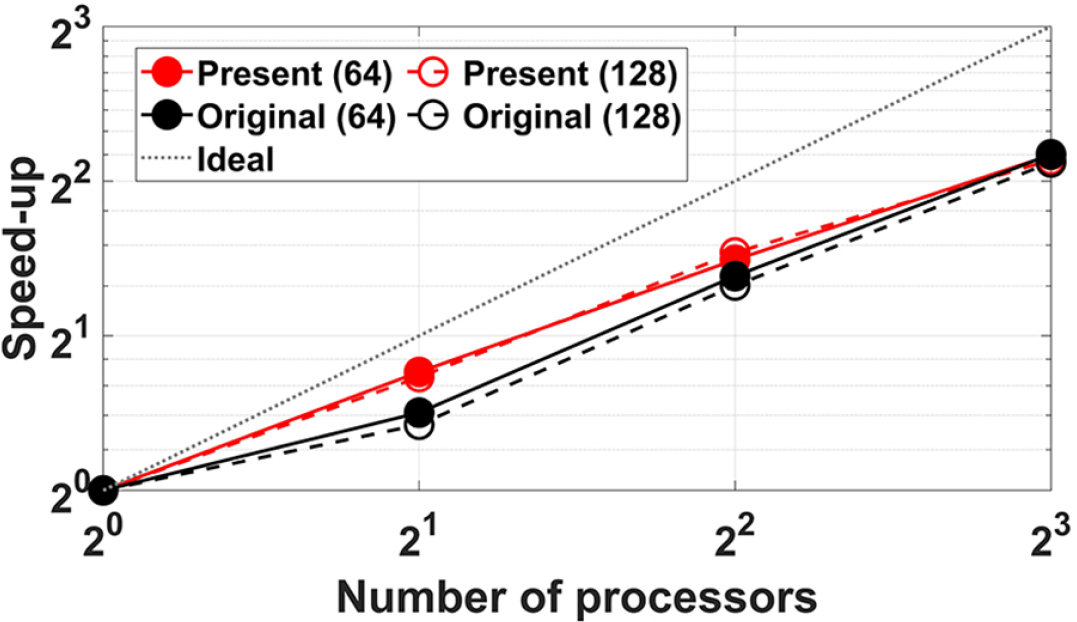
Table 2.
Carbon fiber/epoxy specimen: average speed-up and its increment in terms of the number of the processors
| Number of processors | Average speed-up (increment) | |
| Present | Original | |
| 1 | 1.00 | 1.00 |
| 2 | 1.68(68.1%) | 1.38(38.0%) |
| 4 | 2.86(70.0%) | 2.56(85.4%) |
| 8 | 4.45(55.6%) | 4.42(73.1%) |
본 논문 예제의 계산에 사용된 프로세서 수 내에선 Step I의 계산 시간이 Step II에 비교하여 많은 비중을 차지하였다. Fig. 7에서 확인할 수 있듯, 프로세서 수의 증가에 따라 Step II보다 Step I에서 많은 계산 시간 감소가 발생할 것을 기대할 수 있다. 따라서, 일정 수준 이상의 프로세서 수에선 Step II의 소요 시간이 Step I보다 많을 것이다. 또한, 부영역 수가 증가함에 따라 Step II의 계산 비용이 증가할 것이다. 이러한 점은 대량의 프로세서 및 부영역 해석에서 확장성 양상의 변화를 야기할 것이며, 추후 수십 개 이상의 프로세서를 지원하는 클러스터 컴퓨팅 환경에서 확인될 예정이다.
2.5.2 대자유도 예제 적용
본 논문에서 제시한 알고리즘을 대자유도 해석 예제에 적용하였다. 대상으로 Fig. 9와 같은 형상 및 Table 3의 물성치를 지닌 평직 탄소 섬유 다발/에폭시 인장 시편 예제가 제작되었다. 이때, 는 각각 탄성/전단 계수 및 Poisson 비이며, 아래 첨자는 이방성 재료 방향을 의미한다. 는 각각 시편의 길이, 너비, 두께이다. 에폭시의 물성치 및 평직 섬유 다발의 기하 정보는 Abot 등(2011)이 기술한 내용에 기반하였다. 동일 참고문헌의 탄소 섬유 및 에폭시 정보를 기반으로 Gong 등(2022)이 대표 체적요소(representative volume element) 해석을 수행했던 바 있으며, 본 예제의 섬유 다발 물성치는 이를 참고하여 구성되었다.
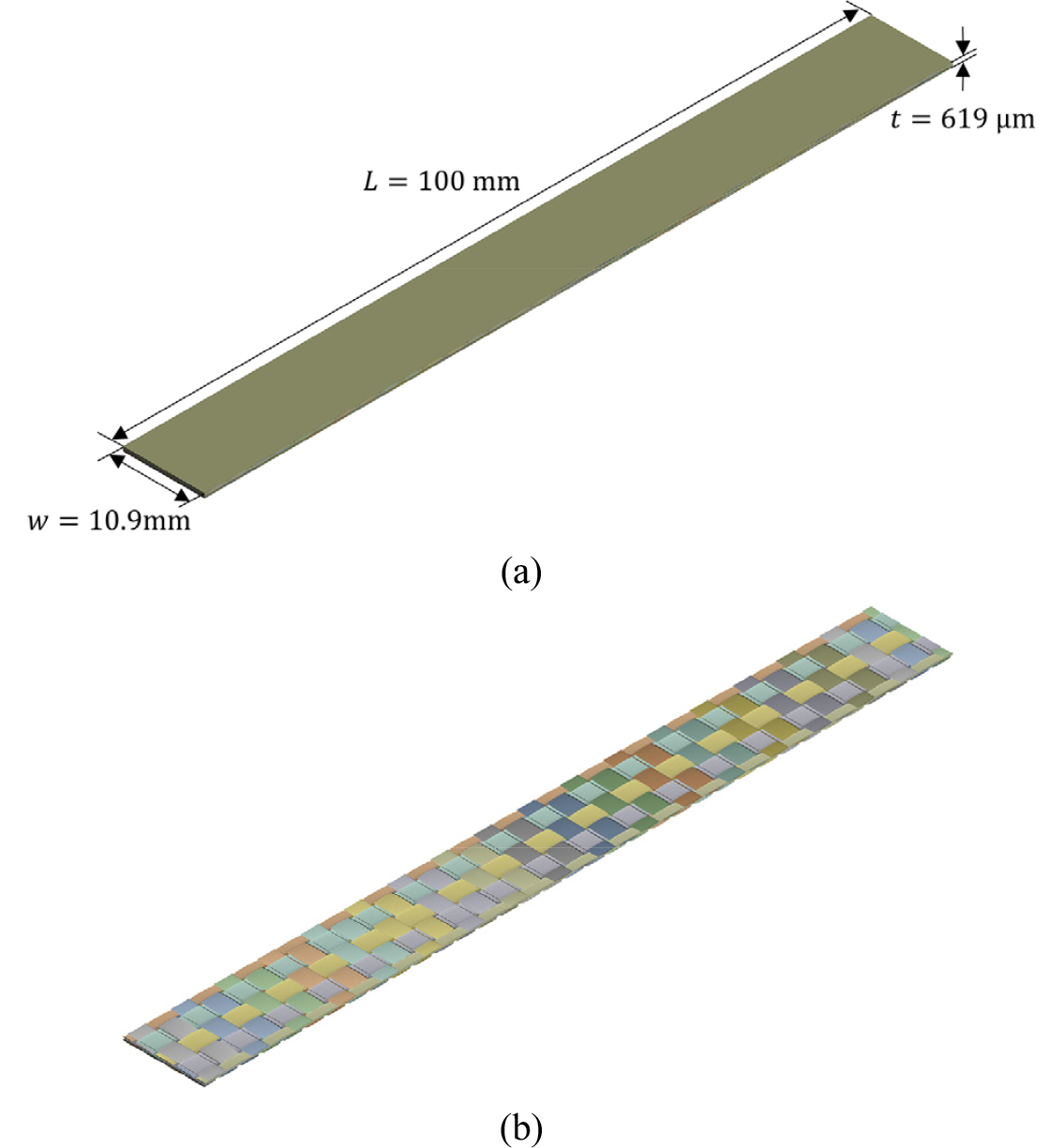
Table 3.
Material properties for the tensile specimen of the plain woven fabric
| Material | Property | Value |
|
Fiber bundle (Gong et al., 2022) | 200GPa | |
| 46.5GPa | ||
| 22.5GPa | ||
| 20.5GPa | ||
| 0.294 | ||
| 0.355 | ||
|
Epoxy matrix (Abot et al., 2011) | 2.9GPa | |
| 0.37 |
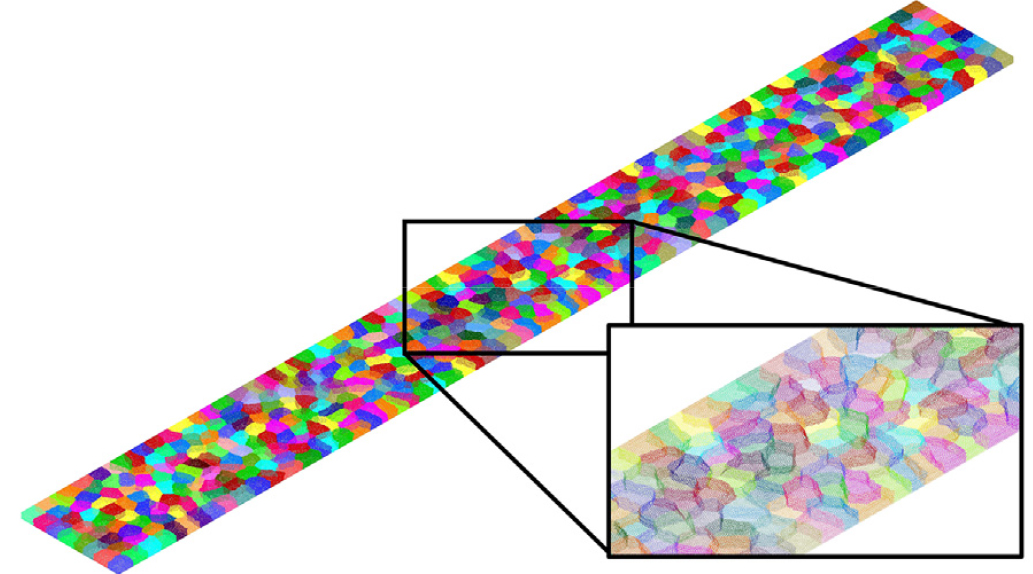
인장 시편의 한쪽 끝은 고정단이며, 반대쪽엔 인장 변위 경계조건이 가해졌다. 유한요소 이산화는 약 432만 개의 변위 자유도 및 약 784만 개의 사면체 솔리드 요소로 구성되었다. 유한요소망은 Fig. 10과 같이 512개 부영역으로 분할되었으며. 부영역 간 경계는 약 54만 자유도의 성긴 절점으로 구성되었다. 앞선 예제와 마찬가지로 사용 프로세서 수가 1개부터 8개까지인 경우에 대해 계산 성능을 확인하였다.
또한, 동일한 예제의 해석이 상용 프로그램인 ANSYS Mechanical 2021 R1(Anonymous, 2021)을 통해 진행되었다. 이 경우 ANSYS 내 분산 메모리 병렬 연산 및 희박행렬 직접해법 기능이 사용되었으며, FETI-local 알고리즘 해석과 동일한 장비 상에서 계산이 수행되었다.
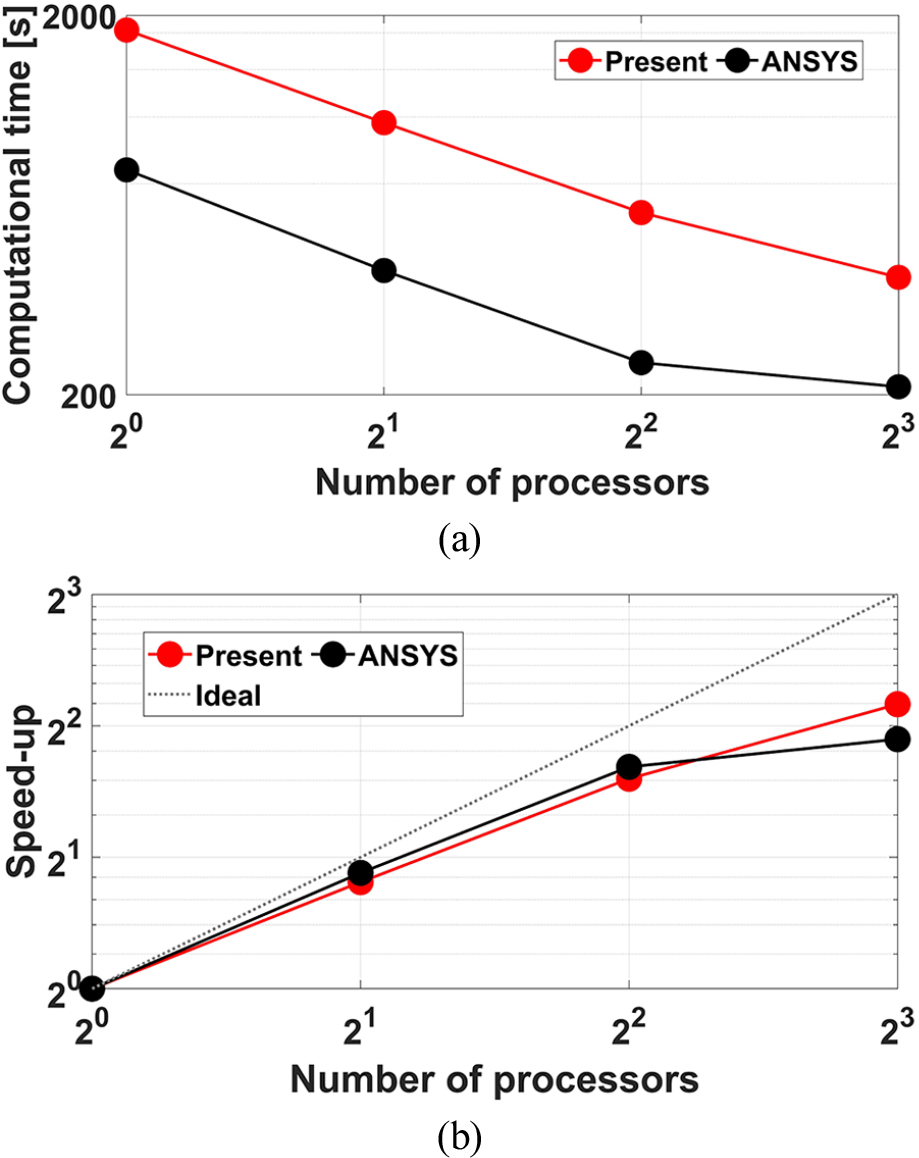
Fig. 11은 본 논문의 알고리즘 및 ANSYS를 통한 해석의 계산 성능을 비교한 것이다. 본 논문에서 제시된 내용을 통해 FETI-local 알고리즘의 계산 속도 개선이 상당히 이루어졌으나, ANSYS의 계산 속도엔 미치지 못하는 것으로 확인되었다. 사용된 프로세서 수를 기준으로, ANSYS가 약 1.9에서 2.5배 신속한 계산을 수행함을 확인하였다. 이는 상용 프로그램인 ANSYS가 사용하는 희박행렬 라이브러리와 무료 라이브러리인 MUMPS의 성능 차이에 기인할 수 있다. 그러나 프로세서 수가 4개에서 8개로 증가할 경우, ANSYS의 가속 지표 증가율은 16.8%로 현저히 낮은 것으로 확인되었다. 반면 본 논문의 FETI-local 알고리즘의 경우, 동일 프로세서 기준 48.1%의 가속 성능 증가율이 확인되었다. 이는 수십 개 이상의 다중 프로세서 연산에서 본 논문의 FETI-local 알고리즘이 ANSYS에 비해 뛰어난 계산 속도를 발현할 것임을 기대할 수 있는 근거이며, 추후 클러스터 컴퓨팅 환경에서 확인될 예정이다.
또한, 본 논문의 알고리즘과 ANSYS는 동일한 구조 거동을 도출함이 확인되었다. 그중, 시편의 길이 방향 탄성 계수()가 Abot 등(2011)의 인장 실험 결과와 비교되었다. 이때 유한요소 해석의 탄성 계수는 고정단의 길이 방향 반력(reaction force) 계산 결과 , 인장 경계조건의 변위 를 토대로 식 (9)와 같이 계산되었다.
Table 4에서 확인할 수 있듯, 유한요소 해석의 탄성 계수 계산 결과는 실험 대비 10.3%의 차이를 보였다. 이는 제시된 FETI-local 알고리즘이 복합재료 실험을 보완 및 대체하여 실험 비용을 절감할 수 있음을 보인다. 이처럼 FETI-local 알고리즘은 대자유도를 취급하는 복합재료 상세 다중 스케일(multi- scale) 해석 분야에서 활용 가능할 것으로 전망된다.
Table 4.
Plain woven fabric specimen: uniaxial elastic modulus
| Finite element analysis |
Experiment (Abot et al., 2011) | Discrepancy | |
| Present | ANSYS | ||
| 70.7GPa | 70.7GPa | 64.1GPa | 10.3% |
3. 결 론
본 논문은 직접해법 기반 FETI-local 알고리즘의 개선 방안을 제시하였다. 직접해법 기반 FETI-local 알고리즘은 부영역별 경계 강성행렬 및 하중벡터 계산 단계(Step I), 전역 경계 행렬식 계산 단계(Step II), 부영역별 변위 계산 단계(Step III)로 구성되었다. 이 중 Step I에서 요구하는 역행렬 계산 과정을 선택적 역행렬 성분 계산을 도입하여 개선하였다. 또한, 기존 단일 프로세서 연산으로 수행되었던 Step II를 다중 프론탈 기법 기반 병렬 프로세서 연산으로 대체하였다. 해당 기법들은 직접해법 기반 희박행렬 연산 라이브러리인 MUMPS를 통해 구현되었다.
제시된 FETI-local 알고리즘의 계산 성능 개선 여부는 3차원 이방성 탄소 섬유/에폭시 시편 수치 예제를 통해 검증되었다. 제시된 알고리즘을 도입할 경우 기존 대비 최대 97.8%의 계산 시간 절감이 달성됨을 확인하였다. 계산 단계별 소요 시간을 확인한 결과, Step I의 계산 시간이 확연하게 감소하였다. 기존 알고리즘에서 프로세서 수와 관계없이 일정한 계산 시간을 보인 Step II는 개선된 알고리즘의 병렬화에 따라 계산 시간 절감이 달성되었다. 확장성의 경우, 제시된 알고리즘은 기존 대비 최대 23.8%가 상승한 가속 지표를 보였다. 또한, 프로세서 수에 따라 안정적인 가속 지표 증가 양상을 확인하였다.
또한, 평직 탄소 섬유 다발/에폭시 인장 시편 수치 예제를 통해 대자유도 계산 성능을 ANSYS와 비교하였다. 사용 프로세서 수가 1개부터 8개까지일 때 계산 속도는 ANSYS가 본 논문의 FETI-local 알고리즘보다 우수하였다. 그러나 본 논문의 알고리즘은 프로세서 증가에 따른 가속 성능 증가율 측면에서 우수하여, 향후 클러스터 컴퓨팅 환경에서의 계산 시 유리할 것이 예상되었다. 시편 길이 방향 탄성 계수 해석 결과는 본 논문의 알고리즘과 ANSYS의 결과가 동일하였으며, 실험 결과와는 10% 이내의 차이가 발생하였다.
본 논문의 계산 알고리즘 검증은 데스크톱 사양 컴퓨터상에서 수행되었으며, 향후 수십 개 이상의 프로세서를 지원하는 클러스터 컴퓨팅 환경에서의 검증이 진행될 예정이다. 또한, 제시된 직접해법 기반 FETI-local 알고리즘의 개선기법은 향후 반복해법 기반 FETI-local 알고리즘의 고도화에 사용될 예정이다.
