

1. 서 론
1.1 연구의 배경 및 목적
2. 기술환경 분석
2.1 머신러닝 기반 포트홀 인식의 현황 및 한계
2.2 알고리즘 기반 깊이 추정의 한계
2.3 Segment Anything Model 2(SAM2)의 개발 및 특징
2.4 대형 언어 모델(LLM)의 발전
2.5 인공지능 기술의 활용 가능성
3. PotholeSAM
3.1 프레임워크 설계
3.2 객체 인식 단계(YOLOv8)
3.3 영역 인식 단계(SAM2)
3.4 깊이 추정 단계(LLM)
4. 분석
4.1 실험 및 결과
4.2 영역 분할을 통한 정확도 향상
4.3 한계점 및 개선 방안
5. 결론 및 시사점
1. 서 론
1.1 연구의 배경 및 목적
포트홀은 아스팔트 도로 포장이 파손되어 노면 일부가 항아리 모양으로 움푹 패인 구멍을 의미하며, 이는 차량의 주행 효율성을 저하시킬 뿐만 아니라 운전자 안전을 위협하여 교통사고의 원인이 된다(Jo and Ryu, 2016). 이러한 이유로 포트홀은 “도로 위의 지뢰”라고도 불리며, 차량 파손을 유발하여 재산상의 피해를 초래하기도 한다.
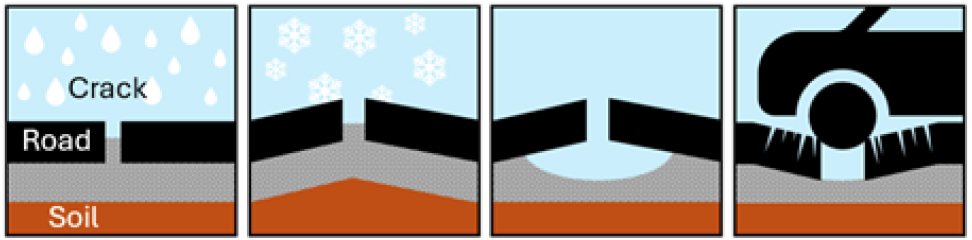
포트홀의 발생 원인은 주로 동절기나 장마철에 눈과 비로 인해 아스팔트 균열에 물이 스며들고, 반복된 차량 하중으로 포장의 일부가 파손되는 데 있다(Fig. 1). 아스팔트 균열은 도로의 노후화와 기상 조건뿐만 아니라 제설 목적으로 사용하는 염화칼슘에 의해서도 발생한다. 특히 최근 일부 지방자치단체에서 눈이 오기 전에 염화칼슘을 미리 도포하는 사례가 증가하면서, 도로 균열과 포트홀의 발생이 크게 증가하였다.
이러한 문제는 통계적으로도 확인된다. 최근 2년 2개월(2022년 1월~2024년 2월) 동안 국민권익위원회의 민간분석시스템으로 분석한 “포트홀” 관련 민원은 총 52,262건으로 집계되었으며, 특히 2024년 1월부터 민원이 급증하여 전년 동기간 대비 약 5.8배 증가하였다(Fig. 2). 그러나 포트홀의 발생이 지나치게 많아 지방자치단체에서 단기간 내에 보수하기에는 가용가능 인력 및 장비 측면에서 현실적인 한계가 존재한다(Kim et al., 2024).
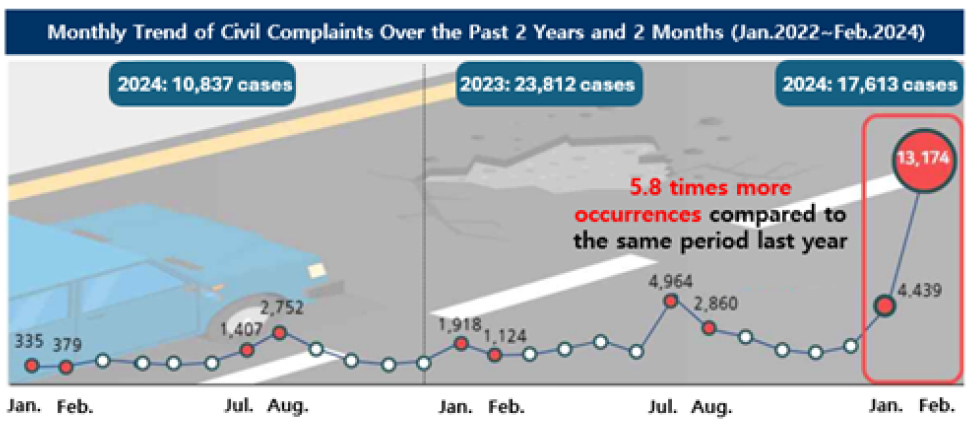
Fig. 2.
Trend of pothole-related complaints over the past 2 years (January 2022~Feburary 2024) (Anti-Corruption and Civil Rights Commission, 2024)
포트홀은 대체로 처음부터 큰 형태로 발생하지 않고, 작은 균열을 중심으로 일부 지반이 침하되면서 시작된다(Siew et al., 2005). 따라서 포트홀 데이터를 주기적으로 수집하고 위험도에 따라 선제적으로 보수한다면, 피해를 크게 줄일 수 있을 것으로 예상된다. 그러나 현재의 포트홀 신고 방식은 운전자가 사진을 첨부하는 형태로, 통행이 이루어지는 도로에서 멈춰서 이미지를 확보하는 행위는 매우 위험하다.
또한 지방자치단체의 인력 부족은 고질적인 문제로, 주기적인 순찰과 포트홀 데이터의 수집 및 분류 업무의 자동화가 필요하다(David et al., 2023). 안전 측면에서도 운전자가 아닌 장비를 통해 데이터를 자동으로 수집하는 방안이 요구된다. 드론, 로봇, 트레일러 등 다양한 장비를 활용할 수 있으나, 장비 종류에 관계없이 포트홀 데이터를 효과적으로 수집하고 분류할 수 있는 공통의 방법론이 필요하다.
이에 본 연구에서는 포트홀 이미지 데이터를 기반으로 SAM2와 LLM을 활용하여 포트홀의 면적과 깊이를 추정하는 기술을 개발하고자 한다. 이를 통해 포트홀의 신속하고 정확한 탐지와 평가가 가능해져 효율적인 도로 유지보수와 안전한 주행 환경 조성에 기여할 것으로 판단된다.
2. 기술환경 분석
2.1 머신러닝 기반 포트홀 인식의 현황 및 한계
최근 포트홀 인식을 위해 머신러닝 기술을 적용하는 연구가 활발히 진행되고 있다. 다량의 학습 데이터를 활용하여 인공지능(AI) 모델을 학습시키면 도로 노면의 포트홀을 비교적 정확하게 인식할 수 있다. 그러나 이러한 접근 방식은 학습 데이터의 질과 양에 크게 의존하며, 다양한 형태와 조건의 포트홀 데이터를 충분히 수집하고 학습해야 모든 포트홀 상황에 대응할 수 있다. 현실적으로 모든 상황을 포괄하는 데이터를 수집하는 것은 어렵고 비용이 많이 들기 때문에 이 방식은 한계가 있다(Thompson et al., 2022).
또한 학습되지 않은 환경적 요인, 예를 들어 조명 변화, 날씨 조건, 주변 물체 등에 의해 현장에서 수집된 포트홀 이미지의 인식 정확도가 저하될 수 있다. 이는 머신러닝 기반 포트홀 인식의 실용화를 어렵게 만드는 주요 요인이다.
2.2 알고리즘 기반 깊이 추정의 한계
포트홀의 깊이를 정확하게 추정하기 위해 다양한 알고리즘이 제안되었다. 대표적인 방법으로는 다음과 같다.
1)스테레오 비전(Stereo Vision): 두 대의 카메라를 이용하여 동일한 장면을 촬영하고, 이들 사이의 시차(parallax)를 계산하여 깊이 정보를 추출하는 방법이다. 이 기술은 인간의 양안 시각 원리를 모방한 것으로, 비교적 단순한 장비로 3차원 정보를 얻을 수 있다는 장점이 있다. 그러나 두 카메라 간의 정밀한 정렬과 보정이 필수적이며, 미세한 오차도 깊이 추정의 정확도에 큰 영향을 미친다. 또한, 도로 표면과 같이 텍스처가 부족한 환경에서는 대응점 매칭이 어려워 정확도가 저하될 수 있다(Smolyanskiy et al., 2018).
2)레이저 스캐닝(Laser Scanning): 레이저 빔을 대상 표면에 투사하고 반사되는 신호를 수신하여 거리를 측정하는 기술이다. 이 방식은 높은 정확도와 해상도를 제공하며, 복잡한 표면 형태도 정밀하게 측정할 수 있다. 그러나 레이저 스캐너 자체의 비용이 매우 높고, 장비의 운용과 유지보수를 위해 전문 인력이 필요하다. 또한, 대용량의 3차원 점군 데이터(Point Cloud)를 처리해야 하므로 데이터 처리에 많은 시간과 자원이 소요된다(Kersten and Lindstaedt, 2022).
3)구조화 광(Structured Light): 특정 패턴의 빛을 대상에 투사하고, 변형된 패턴을 카메라로 촬영하여 깊이 정보를 추출하는 방법이다. 이 기술은 실내 환경에서 물체의 형상을 정밀하게 측정하는 데 활용되며, 비교적 높은 정확도를 제공한다. 그러나 외부 조명 조건에 매우 민감하여 야외 환경에서는 적용이 어렵다. 강한 태양광이나 주변 광원이 패턴을 왜곡시켜 정확한 깊이 측정을 방해하기 때문이다(Xu et al., 2022).
이러한 알고리즘 기반의 깊이 추정 방법들은 이론적으로 높은 정확도를 제공할 수 있으나, 실제 도로 환경에서의 적용에는 여러 가지 한계가 존재한다. 첫째, 장비의 높은 비용과 복잡한 운용으로 인해 대규모로 도입하기 어렵다(Zhao et al., 2024). 예를 들어, 레이저 스캐닝 시스템은 초기 투자 비용이 크고, 유지보수에도 많은 비용이 소요된다. 둘째, 환경적인 제약이 크다. 구조화 광의 경우 야외에서의 적용이 어렵고(Xu et al., 2022), 스테레오 비전은 조명 변화나 날씨 등의 영향을 크게 받는다(Smolyanskiy et al., 2018). 셋째, 실시간 처리가 어렵다는 문제가 있다(Kersten and Lindstaedt, 2022). 대용량의 데이터를 처리하기 위해서는 고성능의 컴퓨팅 자원이 필요하며, 이는 시스템의 효율성을 저하시킨다.
2.3 Segment Anything Model 2(SAM2)의 개발 및 특징
Segment Anything Model 2(SAM2)는 메타(Meta)에서 개발한 최신 객체 분할 모델로서, 어떠한 이미지에서도 모든 객체를 정확하게 분할할 수 있는 인공지능 모델이다. SAM2는 방대한 규모의 데이터셋으로 사전 학습되어 새로운 객체나 장면에 대한 일반화 능력이 뛰어나며, 추가적인 학습 없이도 다양한 환경에서 높은 성능을 발휘한다(Ravi et al., 2024). 이러한 일반화 능력은 형태와 크기가 다양하고 주변 환경에 따라 변화하는 포트홀과 같은 객체를 인식하는 데 특히 유용하다.
SAM2의 주요 특징은 향상된 모델 아키텍처와 실시간 처리 능력에 있다. 딥러닝 기반의 최신 기술을 적용하여 다중 스케일의 특징을 효과적으로 추출하고, 주의(attention) 메커니즘을 활용하여 작은 객체나 복잡한 배경에서도 정확한 분할이 가능하다. 또한 최적화된 연산 구조와 경량화된 모델 설계를 통해 실시간에 가까운 속도로 객체 분할이 가능하여, 차량에 장착된 카메라나 드론 등의 장비로부터 입력되는 영상에서 빠르게 포트홀을 탐지하고 분할할 수 있다.
SAM2는 범용성이 뛰어나 추가적인 데이터나 모델 수정 없이도 다양한 종류의 객체 분할에 적용될 수 있다. 이는 계절이나 지역에 따른 도로 조건 변화에도 유연하게 대응할 수 있음을 의미하며, 다양한 환경에서의 포트홀 인식에 효과적이다. 본 연구에서는 이러한 SAM2의 강력한 객체 분할 능력을 활용하여 포트홀의 면적과 깊이를 정확하게 추정하는 방법을 개발하였다.
2.4 대형 언어 모델(LLM)의 발전
대형 언어 모델(LLM)은 방대한 양의 텍스트 데이터를 학습하여 자연어 처리 능력을 극대화한 인공지능 기술로, 인간과 유사한 수준의 이해력과 판단력을 보여준다. 이러한 모델들은 언어의 문법적 구조뿐만 아니라 의미적 맥락까지 이해하여 복잡한 질문에 대한 답변, 번역, 요약 등 다양한 언어 기반 작업을 수행할 수 있다. 특히 GPT-4, Claude 3, PaLM 2와 같은 최신 모델들은 수천억 개의 파라미터를 통해 높은 수준의 언어 이해와 생성 능력을 갖추고 있다(Achiam et al., 2023).
최근에는 LLM의 활용 범위를 언어 처리에서 더 나아가 멀티모달(Multi-modal) 데이터 처리로 확대하려는 연구가 활발히 진행되고 있다. 멀티모달 접근은 텍스트뿐만 아니라 이미지, 영상, 음성 등 다양한 형태의 데이터를 통합적으로 처리하여 복합적인 이해와 추론을 가능하게 한다. 예를 들어, 이미지의 내용을 설명하거나, 텍스트와 이미지를 결합하여 새로운 정보를 생성하는 등, 단일 모달리티로는 불가능했던 작업들이 가능해지고 있다.
이러한 발전은 이미지 분석과 텍스트 기반 추론을 결합한 응용 분야에서 새로운 가능성을 열어주고 있다. 포트홀과 같은 객체의 이미지를 분석하여 그 특성을 파악하고, 이를 기반으로 유지보수 계획을 수립하는 데 LLM을 활용할 수 있다. 특히 LLM은 복잡한 데이터 패턴을 이해하고 일반화하는 능력이 뛰어나므로, 다양한 환경에서 수집된 포트홀 데이터를 효과적으로 처리하고, SAM2와의 연계를 통해 정확한 면적 및 깊이 추정에 활용될 수 있다.
2.5 인공지능 기술의 활용 가능성
인공지능 기술의 발전은 포트홀 인식과 관리 분야에 혁신적인 가능성을 열어주고 있다. 특히, 이미지 분석과 텍스트 기반 추론을 결합한 멀티모달 접근법을 통해 포트홀의 면적과 깊이를 정확하게 추정하고, 이를 기반으로 효율적인 유지보수 전략을 수립할 수 있게 되었다. 이러한 인공지능 기술의 활용은 기존의 한계를 극복하고 앞서 언급한 포트홀 자동관리 관련 제한사항들을 극복하는 데 중요한 역할을 할 것으로 판단된다.
3. PotholeSAM
3.1 프레임워크 설계
포트홀 현장 이미지 데이터 수집의 핵심은 포트홀의 위치를 신속하게 인식하고, 정확한 영역을 식별한 다음, 깊이를 정확하게 추정하는 것이다. 이를 위해 본 연구에서는 Fig. 3에 제시된 바와 같이 PotholeSAM의 프레임워크를 설계하였다.
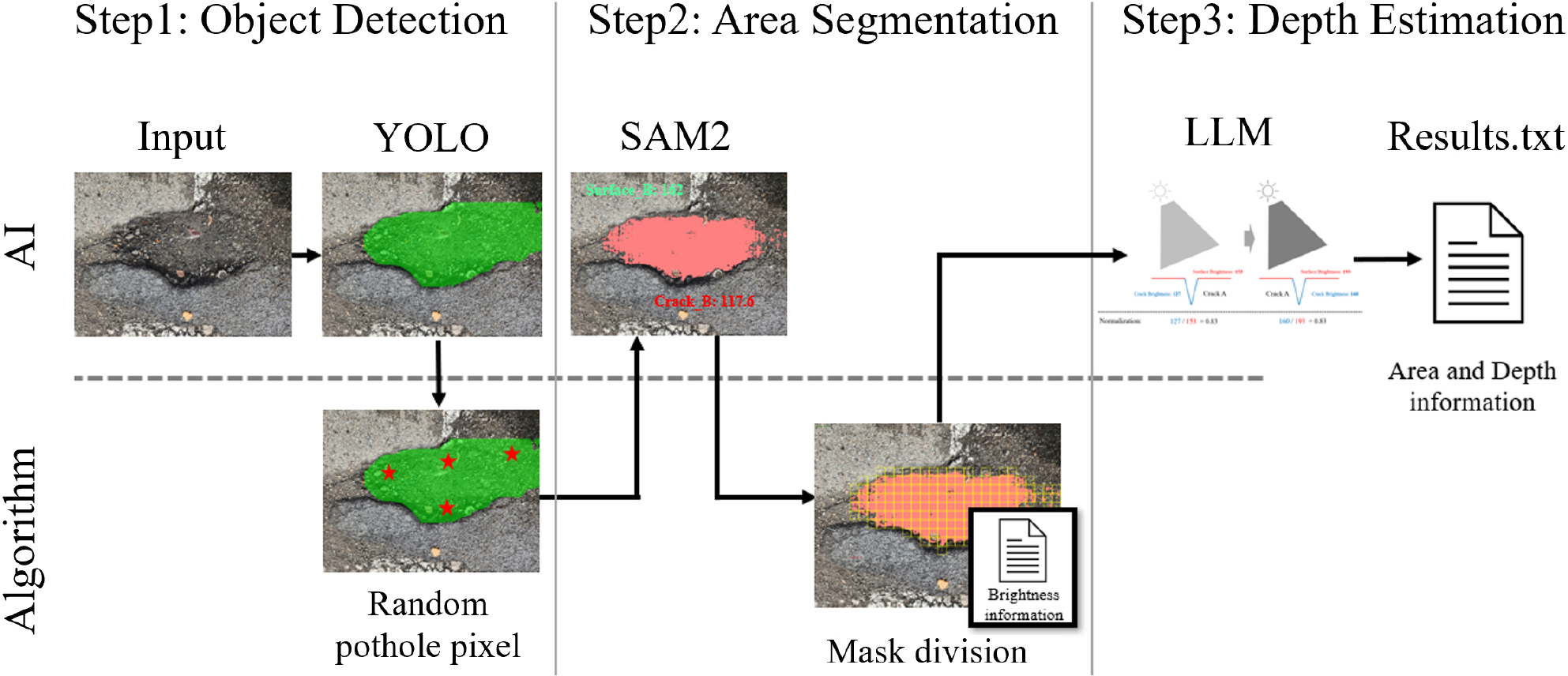
PotholeSAM은 세 가지 주요 단계로 구성된다.
첫째, 객체 인식 단계에서는 사전 학습된 객체 인식 인공지능(AI) 모델을 활용하여 이미지 내에서 포트홀의 위치를 파악한다. 이 단계에서는 포트홀이 존재할 가능성이 높은 영역을 신속하게 탐지하여 이후 처리의 효율성을 높인다.
둘째, 영역 분할 단계에서는 앞서 파악된 포트홀의 위치 정보를 기반으로 SAM2를 적용하여 포트홀의 정확한 경계를 분할한다. SAM2의 강력한 일반화 능력과 높은 분할 정확도를 통해 포트홀의 형태와 면적을 정밀하게 추출할 수 있다.
셋째, 깊이 추정 단계에서는 이전 단계에서 확보한 포트홀의 정밀한 영역 정보를 대형 언어 모델(LLM)에 제공하여, 이미지의 명도 정보를 기반으로 포트홀의 깊이를 추정한다.
3.2 객체 인식 단계(YOLOv8)
SAM2는 객체의 정확한 영역 분할에 뛰어난 성능을 보이지만, 객체의 분류(Classification)은 수행하지 않는다. 따라서 포트홀의 위치와 대략적인 영역을 파악하기 위해 먼저 객체 탐지 모델인 YOLOv8을 활용하였다. YOLOv8은 최신 버전의 You Only Look Once(YOLO) 시리즈로서, 정확도와 속도 면에서 뛰어난 성능을 보여주는 실시간 객체 탐지에 적합한 모델이다(Varghese and Sambath M., 2024).
YOLOv8의 경우, 학습을 위해 연구자들이 수집한 100장의 포트홀 이미지 데이터셋을 사용하였다. 이 데이터셋은 도로 균열과 포트홀을 포함한 다양한 도로 손상 이미지를 포함하고 있어, 모델이 도로 환경에서 발생하는 다양한 손상을 학습하는 데 유용하다. 학습 과정에서는 원본 이미지를 바탕으로 Blur 노이즈 추가 및 색상 반전과 같은 데이터 증강(Data Augmentation) 기법을 통해 추가로 300장의 학습 데이터를 구성하여 모델의 일반화 능력을 향상시켰다. 더하여, 모델 학습 시 교차검증을 위한 20장의 포트홀 이미지를 별도로 준비하여 학습 데이터와 검증 데이터셋의 비율을 10대 2로 하였다. 이를 통해 주간 조명 변화, 카메라 화질, 날씨 조건과 같은 다양한 환경적 요인에 의한 노이즈의 영향을 감소시켰다.
학습된 YOLOv8 모델을 사용하여 실제 도로 이미지에서 포트홀의 위치를 탐지한 결과, Fig. 4와 같이 포트홀의 대략적인 영역을 정확하게 인식할 수 있었다. 상단의 실제 포트홀 이미지와 하단의 YOLOv8 인식 결과를 비교하면, 모델이 포트홀의 위치와 크기를 효과적으로 파악함을 알 수 있다.

이러한 객체 인식 단계는 이후의 영역 분할 단계에서 SAM2가 정확한 포트홀 경계를 추출하는 데 필요한 초기 위치 정보를 제공한다.
3.3 영역 인식 단계(SAM2)
앞 단계에서 YOLO를 활용하여 포트홀의 대략적인 위치와 크기를 파악하였다. 그러나 포트홀과 표면의 경계선은 때로 YOLO 모델이 구분할 수 없을 정도로 모호한 경우가 존재한다. 따라서 객체인식 인공지능만으로는 정확한 포트홀 경계선 및 영역 인식에 한계가 있다. 이에 본 단계에서는 YOLO가 인식한 포트홀의 대략적인 영역을 기반으로 Segment Anything Model 2(SAM2)를 적용하여 포트홀의 정확한 영역 분할(segmentation)을 수행하였다.
SAM2는 주어진 좌표나 이미지 전체에서 객체를 자동으로 분할할 수 있는 최신 객체 분할 모델로서, 다양한 환경에서 높은 일반화 능력과 정확도를 보인다. 특히, SAM2는 추가적인 학습 없이도 다양한 객체와 장면에 적용될 수 있어, 형태와 크기가 다양하고 주변 환경에 따라 변화하는 포트홀과 같은 객체의 분할에 유리하다.
이런 SAM2를 적용하기 앞서, 본 연구에서는 YOLOv8이 인식한 포트홀 영역이 실제 포트홀 영역일 가능성을 높이기 위해 생성된 마스크(mask) 중에서 면적이 큰 상위 4개의 정보를 추출하였다. 이후 선택된 각 포트홀 영역에서 임의의 좌표 정보를 SAM2에 입력 값으로 제공하였다. SAM2는 이 좌표 정보를 기반으로 포트홀의 정확한 경계를 추출하였으며, 그 결과 Fig. 5와 같이 포트홀의 정확한 영역 분할에 성공하였다.

SAM2를 통해 얻은 포트홀의 마스크 정보는 이후 깊이 추정 단계에서 대형 언어 모델(LLM)에 제공되어, 포트홀의 깊이를 더욱 정확하게 추정하는 데 기여한다. 또한, SAM2의 자동화된 처리 능력은 대량의 이미지 데이터를 효율적으로 처리할 수 있어, 실시간 또는 준 실시간 응용에서도 적용 가능하다.
본 단계에서 SAM2의 적용은 포트홀의 복잡한 형태와 주변 환경의 변동에도 불구하고 높은 정확도의 영역 분할을 가능하게 하였다. 이는 기존의 객체 인식 인공지능의 한계를 극복하고, 포트홀 관리에 필요한 정밀한 정보를 제공하는 데 중요한 역할을 한다.
3.4 깊이 추정 단계(LLM)
깊이 추정 단계에서는 원본 이미지와 SAM2로 분할된 포트홀의 정확한 영역 정보를 활용하여 포트홀의 깊이를 추정한다. 이 단계는 포트홀의 심각도를 평가하는 데 핵심적인 역할을 한다. 구체적인 프로세스는 다음과 같다.
첫째, 명도 계산을 위해 SAM2를 통해 얻은 포트홀 영역과 주변 도로 표면 영역을 구분한다. 각 영역에서 이미지의 픽셀 명도 값을 분석하여 평균 명도를 계산한다. 이는 포트홀 내부와 도로 표면 간의 밝기 차이를 정량화하는 데 사용된다.
둘째, 정규화 단계에서는 계산된 포트홀 영역의 평균 명도를 주변 도로 표면의 평균 명도로 나누어 정규화한다. 이를 통해 조명 조건이나 카메라 설정에 따른 절대적인 밝기 변화의 영향을 최소화하고, 포트홀 영역의 명도가 주변 대비 어느 정도 어두운지를 비율로 표현할 수 있다.
셋째, 이렇게 얻어진 정규화된 밝기 비율, 원본 이미지, 그리고 포트홀의 정확한 영역 정보를 대형 언어 모델에 전달한다. LLM은 사전에 학습된 지식을 바탕으로 이러한 입력 정보를 해석하여 포트홀의 깊이를 추정한다.
Fig. 6은 포트홀의 영역 정보와 명도 정보가 표시된 이미지를 보여준다.

4. 분석
4.1 실험 및 결과
본 연구에서는 SAM2를 통해 얻은 포트홀의 정확한 면적과 LLM을 통해 추정한 깊이 값을 활용하여 포트홀의 부피를 계산하였다. 구체적으로 포트홀의 면적에 깊이를 곱하여 부피를 산출하였으며, 이렇게 계산된 부피를 실제 현장에서 측정한 포트홀의 부피와 비교하였다.
실험 결과, PotholeSAM을 통해 추정된 포트홀의 부피는 실제 부피의 평균 75.9%에 해당하였다(Table 1). 이는 PotholeSAM이 포트홀의 부피를 비교적 정확하게 예측할 수 있음을 보여준다. 그러나 평균적으로 24.1%의 오차가 존재하였고, 모든 테스트 케이스에서 추정 값이 실제 값보다 낮게 나타나는 경향을 보였다. 이러한 일관된 과소 추정은 시스템적인 편향의 가능성을 시사한다. 따라서 추후 데이터 분석을 통해 이러한 편향의 원인을 파악하고 오차를 보정하는 공식을 도출한다면, 오차율을 더욱 감소시킬 수 있을 것으로 판단된다.
Table 1.
Test Results
4.2 영역 분할을 통한 정확도 향상
포트홀은 내부 구조가 복잡하고 깊이가 균일하지 않은 경우가 많아, 단일한 깊이 값으로 전체 부피를 추정하면 오차가 발생할 수 있다. 이러한 문제를 해결하기 위해 Fig. 7과 같이 SAM2에서 인식한 포트홀 영역을 40 × 40 픽셀의 작은 그리드로 세분화하였다.
각 분할된 그리드마다 동일한 방법으로 깊이를 개별적으로 추정하여 해당 영역의 부피를 계산하였다. 이후 모든 그리드의 부피를 합산하여 전체 포트홀의 부피를 산출하였다(Fig. 8). 이 방법은 포트홀 내부의 깊이를 구역별로 세밀하게 반영하여 부피 추정의 정확도를 높일 수 있다.

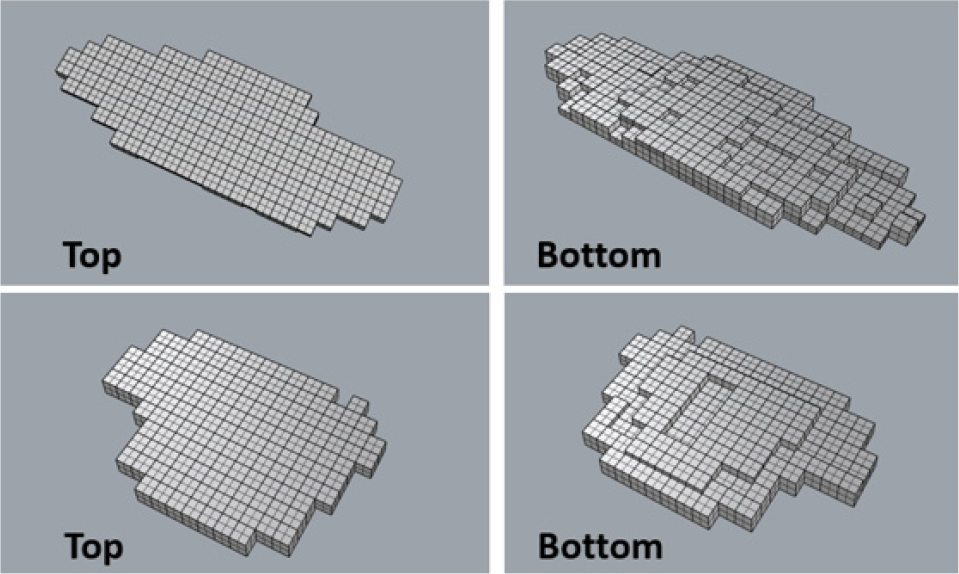
이러한 세분화 기법을 테스트 케이스1에 적용한 결과, PotholeSAM으로 추정된 포트홀의 부피는 실제 부피 대비 오차율이 평균 9.65%로 감소하였다(Table 2). 이는 영역 분할을 통한 깊이 추정이 포트홀 부피의 정확한 산정에 효과적임을 나타낸다.
Table 2.
Test Results
4.3 한계점 및 개선 방안
본 연구에서 제안한 PotholeSAM은 포트홀의 위치 인식부터 정확한 영역 분할, 깊이 추정에 이르기까지 일련의 과정을 자동화하여 포트홀 관리의 효율성을 높였다. 그러나 몇 가지 한계점이 존재하며, 이를 개선하기 위한 방안이 필요하다.
첫째, 조명 조건의 영향이다. 본 시스템은 이미지의 명도 정보를 기반으로 깊이를 추정하기 때문에, 인위적인 광원이 추가되거나 자연광이 부족한 경우 추정 정확도가 떨어질 수 있다. 예를 들어, 야간 촬영이나 강한 그림자가 드리워진 환경에서는 명도 값이 왜곡되어 포트홀의 실제 깊이를 정확하게 반영하지 못할 수 있다. 이를 해결하기 위해 조명 조건을 보정하는 알고리즘의 개발이 필요하다. 예를 들어, 이미지 전처리 단계에서 조명 균일화(Histogram Equalization)나 감마 보정(Gamma Correction) 기법을 적용하여 조명 조건의 변화를 보정할 수 있다(Chang et al., 2018). 또한, 다양한 조명 환경에서의 데이터를 추가로 학습하여 모델의 조명 변화에 대한 강인성을 향상시킬 수 있다.
둘째, 복잡한 포트홀 형태와 주변 환경의 영향이다. 매우 복잡한 형태의 포트홀이나 주변 환경이 복잡한 경우, SAM2를 통한 영역 분할과 LLM을 통한 깊이 추정의 정확도가 낮아질 수 있다. 예를 들어, 포트홀 내부에 이물질이 있거나, 주변에 유사한 명도를 가진 객체(예: 물웅덩이, 그림자)가 존재하는 경우 인식 오류가 발생할 수 있다. 이를 개선하기 위해 추가적인 데이터 학습이 필요하다. 다양한 형태와 환경에서 수집된 포트홀 이미지를 모델에 학습시켜 일반화 능력을 향상시킬 수 있다. 또한, 후처리 알고리즘을 도입하여 인식 결과를 보정하는 방법도 고려할 수 있다. 예를 들어, 기하학적 특성 분석을 통해 비정상적인 영역을 필터링하거나, 주변 맥락 정보를 활용하여 포트홀 여부를 재판단하는 기법을 적용할 수 있다.
향후 연구에서는 이러한 한계점을 보완하기 위해 조명 조건 변화에 강인한 이미지 처리 기술과 복잡한 환경에서도 높은 정확도를 유지할 수 있는 모델의 개선이 필요하다.
5. 결론 및 시사점
본 연구에서는 최신 객체 분할 모델인 SAM2와 대형 언어 모델인 LLM을 결합하여 포트홀의 위치, 면적, 깊이를 정확하게 추정하는 PotholeSAM을 개발하였다. 이 프레임워크는 YOLOv8을 활용한 객체 탐지, SAM2를 통한 정밀한 영역 분할, LLM을 이용한 깊이 추정의 세 단계로 구성된다. 이를 통해 포트홀의 핵심 정보를 자동으로 수집하고 분석하여 도로 관리에 필요한 데이터를 효율적으로 확보할 수 있었다.
실험 결과, PotholeSAM은 실제 측정값 대비 27.3% 이내의 오차로 포트홀의 부피를 추정할 수 있었다. 더하여 포트홀 영역을 세분화하여 깊이를 구역별적으로 추정함으로써 내부의 깊이 변화를 8%의 오차로 세밀하게 반영할 수 있었다. 이는 기존의 단순 깊이 추정 방법에 비해 정확도가 향상되었으며, 도로 유지보수 작업의 우선순위를 결정하고 자원을 효율적으로 배분하는 데 유용한 정보를 제공한다.
이번 연구를 통해 지방자치단체의 인력 부족 문제를 완화하고, 운전자에게 위험한 포트홀을 조기에 발견하여 선제적으로 대응할 수 있는 가능성을 확인하였다. 추후 다양한 도로 환경에서의 적용을 위해 조명 조건 등 환경적인 요인에 대한 보정 알고리즘 개발과 실시간 처리 성능 향상을 위한 최적화 과정이 필요하다. 이를 통해 PotholeSAM의 실용성을 강화하여, 도로 포트홀 모니터링 및 관리 자동화에 이바지할 수 있을 것으로 판단된다.
