

1. 서 론
2. 전이학습 기반 예측 시스템 개발
2.1 기존 딥러닝 기반 예측 시스템
2.2 전이학습 기반 예측 시스템
3. 철도교량 설계변경 예제
3.1 설계변경 시나리오
3.2 전이학습을 위한 데이터베이스 구축
3.3 전이학습 시나리오
3.4 전이학습 결과분석
4. 결 론
1. 서 론
철도교량의 설계는 일반적으로 건설공사에 맞추어 장기간에 걸쳐 수행되고 다양한 불확실성을 동반한다. 이에 따라 초기 계획 및 설계 단계에서 심도있는 검토를 수행하였더라도 이후 설계변경이 빈번하게 발생하는 실정이다. 국가철도공단의 설계변경 현황자료에 의하면 2009년부터 2014년까지 6년간 철도건설사업에서 설계변경은 총 11,512건이 발생한 것으로 집계된 바 있다(Kim et al., 2018). 철도건설사업에서 설계변경은 공사 중 빈번하게 발생되고 있으나, 설계변경을 위한 대안 검토단계에서 상당한 시간과 인력의 투입이 필요하게 되므로 비효율적이다.
철도교량은 활하중의 비중이 크며, 일정한 주기의 연행하중 작용에 의한 공진 발생 위험이 존재한다는 특징이 있다(Kim and Kwak, 2012). 특히 공진 등으로 인하여 발생할 수 있는 교량의 과도한 진동은 교량의 동적안전성뿐만 아니라 주행하는 열차의 안전성 및 승차감 확보에 큰 위협 요소가 될 수 있으므로 고속철도교량의 경우 설계 시 동적해석을 통하여 동적거동 검토를 수행하도록 하고 있다(KRNA, 2014). 동적거동 검토는 교량을 통과하는 모든 종별의 열차에 대하여 설계속도의 110%까지 10km/h 간격으로 동적해석을 수행하도록 하고 있으므로 다른 설계 단계에서 수행하는 수치해석에 비해서 월등히 많은 시간이 소요된다.
최근 Kim과 Choi(2022)은 동적 응답 검토 절차의 효율성을 향상하고자 딥러닝 기반의 철도교량의 주행안전성 및 승차감 예측 시스템을 개발한 바 있다. 개발된 시스템은 상용 유한요소해석 프로그램과 연동하여 철도교량에 대한 열차 속도별 자동해석기능과 함께 연직가속도, 연직처짐 등 주행안전성 및 승차감 검토에 필요한 동적 응답에 대한 자동출력기능을 제공한다. 산정된 결과들은 딥러닝 모델 구축을 위한 학습데이터로써 데이터베이스(Database) 형태로 축적되며, 이를 학습하여 딥러닝 기반 예측 모델을 구축할 수 있다. 구축된 예측 모델을 이용하면 별도의 동적해석을 수행할 필요없이 주행안전성 및 승차감 검토 결과를 예측할 수 있다.
그러나 Kim과 Choi(2022)이 제안한 예측 시스템과 같은 딥러닝 기반 모델들은 지도학습에 해당하므로 알고리즘이 답을 알 수 있도록 사전에 라벨링된 학습데이터를 준비해 줄 필요가 있다. 해당 시스템에서는 이러한 데이터 라벨링 작업을 자동 해석 기능 및 출력 기능을 통해 자동화하였지만, 보다 다양한 파라미터 고려를 위하여 파라미터의 범위가 증가할 경우, 기존과 동등한 수량의 학습데이터 재구축이 필요하며, 딥러닝 학습을 처음부터 다시 수행하여야 한다는 단점이 있다. 특히, 설계 시 고려하지 못한 실제 현장의 환경적 요인 및 불확실성으로 인하여 빈번하게 발생하는 설계변경으로 인한 재설계 시 설계파라미터에 대한 예측치 못한 추가, 변동 등으로 나타나기 때문에 상황 변화에 대한 대응 성능의 개선은 딥러닝 기반 예측 시스템이 당면한 가장 중요한 과제 중 하나이다.
전이학습(Transfer learning)은 사전에 학습이 완료된 모델의 계층구조, 가중치, 편향 등의 파라미터들을 새로운 데이터 학습 시 전이하여 활용하는 기법으로 특히 새로운 학습데이터를 충분히 확보하기 어려운 경우 활용성이 높은 기법이다. 이 알고리즘은 기존 데이터의 인과관계를 학습한 결과를 활용하므로 단순히 새로운 도메인(New domain)에서 학습데이터의 양이 불충분할 경우뿐만 아니라 기존 도메인(Existing domain)에서 고려하지 않았던 파라미터를 추가할 때에도 활용 가능하다는 장점이 존재하여 최근 딥러닝 분야에서 활발하게 연구되고 있다(Zhuang et al., 2020).
Chung 등(2020)은 새로운 장비에 대한 가상계측 모델 학습 시 발생하는 데이터 부족 문제를 해결하기 위해 전이학습을 적용한 바 있다. 가상계측은 최근 딥러닝의 발달과 함께 반도체 제조 분야에서 활발히 연구되고 있는 주제이며, 기본적으로 예측 모델이기 때문에 충분한 양의 학습데이터를 확보하는 것이 필수적이다. Chung 등(2020)은 기존 장비와 새로운 장비 간의 데이터 분포 차이에서 오는 한계점을 극복하기 위해 상관관계 정렬(CORAL: Correlation Alignment)을 적용하였고, 그 결과 전이학습의 정확도를 개선할 수 있었다.
Kim 등(2020)은 가공동력을 공정계획 단계에서 사전에 예측하기 위해 전이학습 기법을 가공동력 예측 모델 생성에 적용한 바 있다. 가공동력 에너지 최적화 분야는 딥러닝 기술의 발전과 더불어 이론적으로 직접 계산하거나 복잡한 시뮬레이션을 수행할 필요없이 제조 현장 데이터를 학습하는 것으로 예측 모델을 생성하는 기법들이 활발히 연구되고 있으나, 제조 현장 특성상 항상 충분한 데이터를 확보하는데 과도한 비용 및 시간이 소요되고 데이터 부재, 불량 및 손실이 빈번하게 발생하고 있다. Kim 등(2020)은 이러한 문제를 개선하기 위해 전이학습을 이용하여 적은 데이터로도 예측 모델 구성이 가능하게 하였고, 사전 고려하지 못한 파라미터가 추가되었다 할지라도 대응 가능한 기법을 제안하였다.
이 연구에서는 전이학습 기법을 적용하여 다양한 설계변경 및 설계파라미터 변화에 대해 대응할 수 있는 딥러닝 기반 예측 시스템을 개발하였다. 전이학습이 적용된 예측시스템의 적절성 검토를 위하여 두가지의 철도교량 설계변경 시나리오를 작성하였다. 각 시나리오에서는 전이학습 적용 전・후의 성능 비교를 위해 기본 도메인에서 기존 딥러닝 알고리즘으로 예측 모델을 작성한 뒤, 새로운 도메인에서 전이학습 알고리즘으로 예측 모델을 작성하여 그 결과를 비교・분석하였다.
2. 전이학습 기반 예측 시스템 개발
2.1 기존 딥러닝 기반 예측 시스템
고속철도교량 설계 시 수행되는 주행안전성 및 승차감 검토는 교량을 통과하는 열차의 종류가 다수일 경우 1회 검토 시에도 수백 번의 해석을 수행하여야 하므로 부적절한 결과 등에 대한 피드백의 어려움이 있다. Kim과 Choi(2022)이 제안한 예측 시스템은 철도교량 설계 시 설계 파라미터와 주행안전성 및 승차감 검토 결과 간의 상관관계를 학습하고, 주행안전성 및 승차감 검토 결과를 사전 예측할 수 있으므로 수십 또는 수백회의 반복 해석이 필요한 기존의 주행안전성 및 승차감 검토 절차를 간소화할 수 있다는 장점이 있다.
Kim과 Choi(2022)이 제안한 딥러닝 기반 예측 시스템의 전체적인 프로세스는 Fig. 1과 같다. 예측시스템은 첫 번째로 주행안전성 및 승차감 해석 과정을 모듈화하여 자동화시킨 1단계, 이후 1단계에서 확보된 입력 및 출력데이터를 라벨링하여 학습데이터를 구축하는 2단계, 딥러닝 알고리즘을 학습하는 3단계, 마지막으로 구축이 완료된 딥러닝 예측 모델을 활용하여 동적응답을 예측하는 4단계를 포함한 총 4개의 단계로 구성되어 있다.
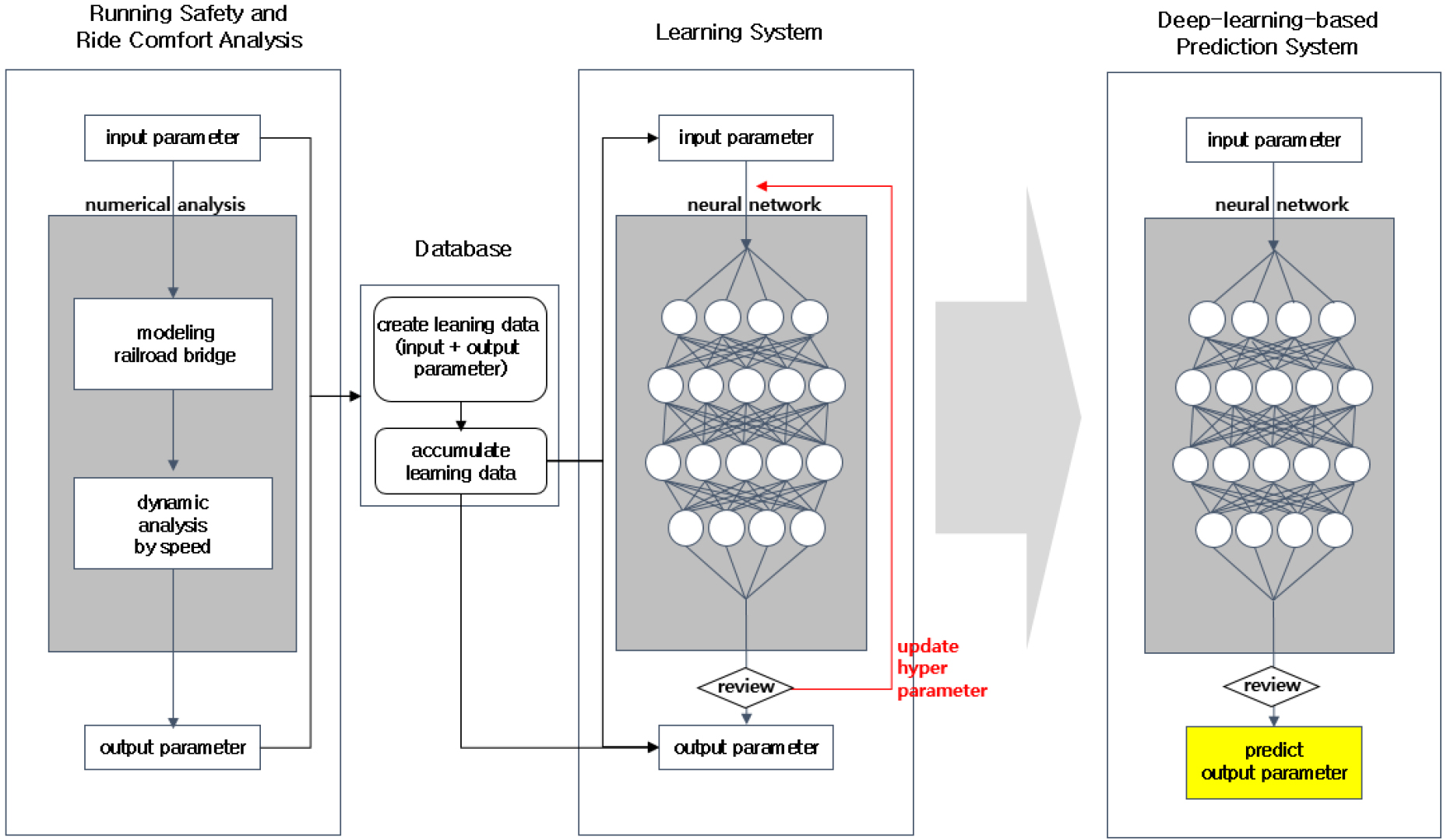
2.2 전이학습 기반 예측 시스템
전이학습은 기존 도메인과 새로운 도메인 간에 유사성이 존재할 경우, 기존 도메인 상의 데이터들의 인과관계를 학습한 딥러닝 모델을 새로운 도메인 상에서 활용하고자 할 때, 이미 구축한 모델의 가중치, 편향, 각 층의 노드 수, 연결 관계 등 인공신경망을 구성하는 각종 정보들을 상속받아 더 효율적인 학습을 진행하고자 하는 알고리즘이다. 특히, 대부분의 전이학습의 경우 이미지를 학습하기 위한 CNN(Convolutional Neural Networks) 구조에서 활발하게 활용되고 있는데 이는 이미지 데이터 특성상 2차원 혹은 3차원의 매우 커다란 크기의 입력파라미터로 인해 학습 속도의 개선이 필수적이기도 하며, 딥러닝 모델을 전이 시, 전・후 도메인 간에 데이터 형식 차이가 없거나 이미지 사이즈를 조절하는 등 비교적 단순한 전처리만으로도 비교적 용이하게 활용 가능하기 때문이다.
또한, 전이학습은 이미지 데이터뿐만 아니라 시뮬레이션 데이터, 시계열 분석자료 등 다양한 데이터에 적용 가능한 알고리즘이다. 이는 전・후 데이터 간에 특성 차이로 인한 데이터 분포 차이가 존재하거나 기존 도메인에서는 고려되지 않았던 새로운 파라미터가 추가되는 경우에도 적용 가능하며, 여러 분야에서 연구된 결과를 통해 확인이 가능하다(Zhuang et al., 2020). 특히 기존 도메인에서 나타나는 인과관계가 새로운 도메인에도 존재할 경우 전이학습을 수행하였을 때 효과를 크게 확인할 수 있으며, 이는 학습 시 수렴 속도 증가, 학습에 필요한 데이터 수의 절감 등의 효과를 얻을 수 있다. 이러한 이유로 불확실성이 많은 환경이나 학습 데이터를 충분히 확보하기 어려운 경우 전이학습을 이용한 딥러닝 모델 개선 연구가 최근 크게 주목받고 있다(Weiss et al., 2016). Table 1은 전이학습에 사용되는 주요 용어이다.
Table 1.
Transfer learning terms
전이학습을 위해 주로 사용되는 기법으로는 미세조정(Fine- tuning) 기법과 고정특징추출(Fixed feature extractor) 기법이 있다.
미세조정 기법은 기존 도메인에서 학습된 인공신경망 구조를 그대로 새로운 도메인으로 전이한 후 하이퍼 파라미터만을 새로 갱신하는 방법이다(Fig. 2(a)). 하이퍼 파라미터는 가중치, 편향 등 인공신경망 구조를 형성하는 파라미터가 아닌 매 학습 시퀸스마다 갱신되며 인공신경망 구조를 최적화시키는 파라미터를 가리킨다. 미세조정 기법은 전이한 후 기존 도메인에서 마지막으로 결정된 하이퍼 파라미터를 초기 파라미터로 활용하여 기존 도메인과 새로운 도메인 간에 파라미터의 구성 및 연결구조가 유사할수록 높은 정확도를 기대할 수 있다. 또한 상위층일수록 데이터의 특성을 정확하게 표현하는 경향이 있으므로(Yosinski et al., 2014) 전이학습 시 보통 상위 몇 개의 층에 대해서 미세조정을 실시한다.
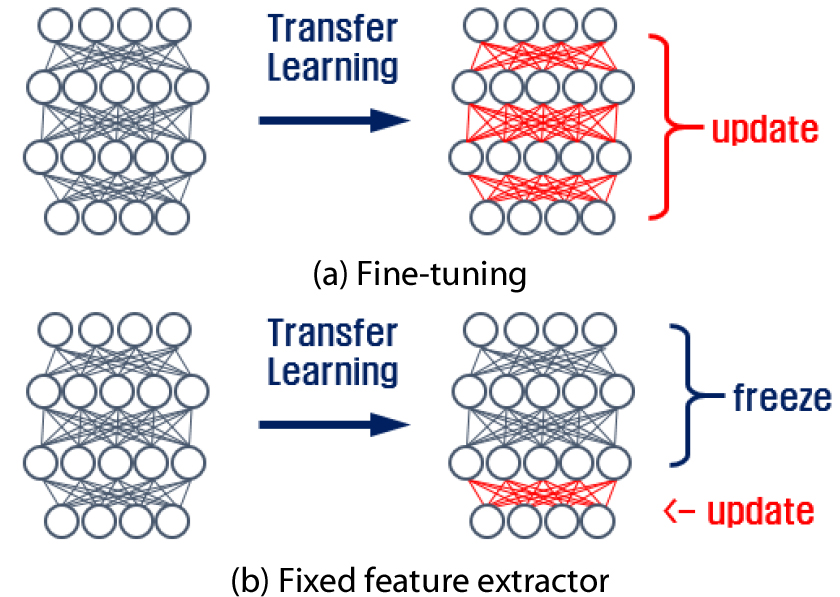
고정특징추출기법은 기존 도메인에서 새로운 도메인으로 인공신경망을 전이할 때 마지막 층을 제외한 모든 층을 그대로 사용하는 기법이다(Fig. 2(b)). 이는 기존 도메인과 새로운 도메인 간의 상관성이 높을 경우 기학습된 하이퍼 파라미터를 그대로 활용하는 기법이다. 따라서 기존 도메인과 새로운 도메인이 파라미터들 간 연결 관계 등에 있어 구조적으로 상관성이 높고, 전후 학습데이터가 중복되는 부분이 일정 비율 존재하거나 기학습된 하이퍼 파라미터 값 중 일부가 새로운 도메인에서도 필요한 값이어서 사전에 기존 도메인에서 산정하는 것이 의미가 있을 경우 효과적이다. 고정특징추출기법은 기학습된 신경망에서 거의 갱신이 이루어지지 않으므로 국소 최적해(Local optimum)를 출력하는 경우가 나타날 수 있으나, 새로운 데이터가 매우 적을 경우에도 적용 가능하다는 장점이 있고 단일 계층만을 갱신하므로 1회 반복 당 계산 횟수가 적어 데이터의 유사성이 높은 경우에는 수렴 속도가 빠르다는 특징이 있다.
이 연구에서는 Kim과 Choi(2022)이 제안한 딥러닝 기반 예측 모델에 미세조정 기법과 고정특징추출기법을 각각 적용하여 새로운 도메인으로 전이하고 각 기법 적용 시의 효과를 비교하였다. 미세조정 기법은 앞서 설명한 바와 같이 전이된 초기 하이퍼 파라미터는 그대로 사용하되 전체적인 값들의 갱신을 수행하였고, 고정특징추출기법은 기존 딥러닝 모델을 그대로 사용하되 마지막 계층만을 초기화하여 갱신을 수행하였다.
3. 철도교량 설계변경 예제
3.1 설계변경 시나리오
철도교량 설계변경 시 딥러닝 기반 예측 시스템을 다시 구축하는 과정에서 전이학습을 도입하였을 때의 적용성을 검토하기 위해 2가지 경우의 설계변경 시나리오를 작성하였다. 2가지 시나리오에서는 공통적으로 Kim과 Choi(2022)이 구축한 학습 데이터베이스를 그대로 활용하여 무궁화호의 실 열차 하중이 단선 재하되는 경우를 기본 모델로 설정하였다. 참고로 무궁화호 열차하중은 KTX 등 고속열차 차량 주행 시에 비해 상대적으로 큰 교량의 응답을 얻을 수 있으며 열차 길이가 203m로 388m인 KTX열차에 비해 짧고 최대 운행 속도가 200km/h 이하로 검토 요구 속도의 가짓수가 절반가량이기 때문에 학습데이터를 경량화하여 시스템 개발 시 초기테스트의 수행에 있어 보다 효율적이고 신속한 검토가 가능하다. 시나리오 구성을 위해 먼저 각 Case를 설정하였다. Case 1~3은 각각 열차하중이 100% 크기로 단선 재하되는 경우, 열차하중이 75% 크기로 단선 재하되는 경우 및 열차하중이 100% 크기로 복선 재하되는 경우이다. 첫 번째 시나리오는 열차하중이 75%로 감소하는 경우(Case 1 to Case 2)를 모사하였고, 두 번째 시나리오는 복선 재하로 변경되는 경우(Case 1 to Case 3)를 모사하였다(Fig. 3).
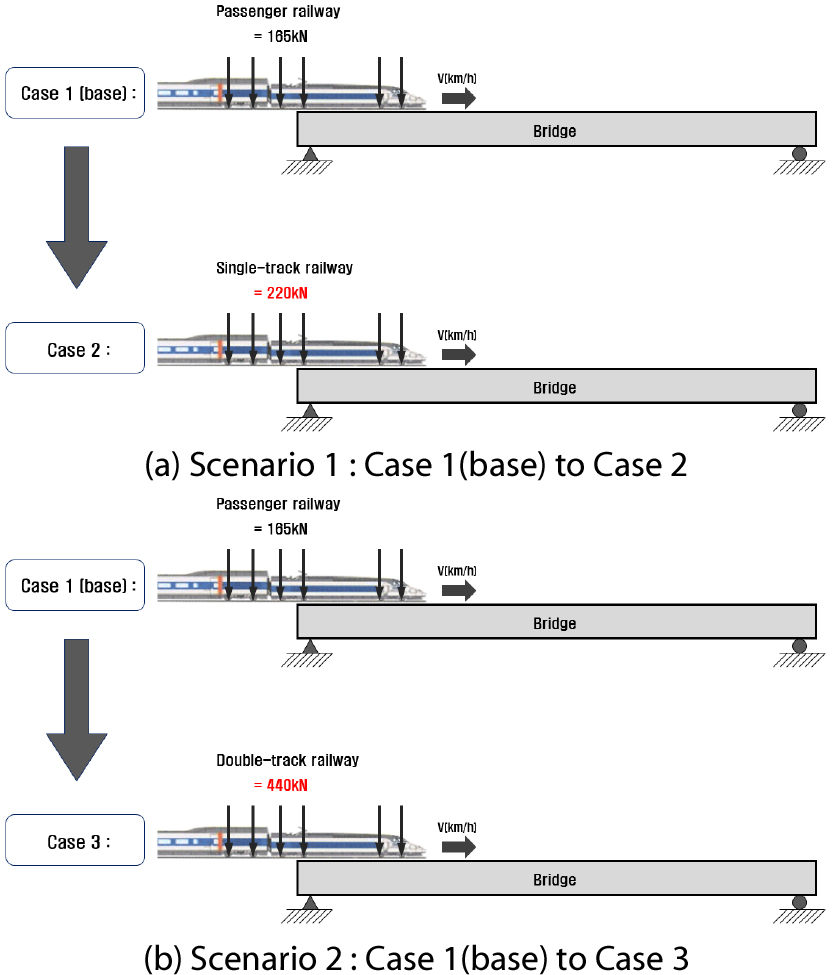
3.2 전이학습을 위한 데이터베이스 구축
전이학습을 위해 각 시나리오별로 전이 전 도메인(Case 1)에서 학습데이터 10,000개, 전이 후 도메인들(Case 2, 3)에서 학습데이터 1,745개씩을 생성하였다. 전이 전 도메인에서는 인공신경망의 훈련에 8,000개의 데이터, 완성된 신경망의 테스트에 2,000개의 데이터를 할당하였고, 전이 후 도메인에서는 인공신경망의 훈련에 1,000개의 데이터, 완성된 신경망의 테스트에 745개의 데이터를 할당하였다. 학습데이터는 입력파라미터-출력파라미터 형식의 라벨링 데이터로 구성된다. 입력파라미터는 운행 열차의 속도(Train velocity), 교량 재료의 밀도(Bridge density), 교량 탄성계수(Bridge elasticity), 교량 폭(Bridge width), 교량 상판 높이(Bridge deck height) 및 교량 길이(Bridge length)로 구성된 데이터 세트이며, 출력파라미터는 교량의 연직 변위(Vertical deflection), 연직 가속도(Vertical acceleration)의 구성된 데이터 세트이다.
시나리오를 구성하는 각 Case들의 입력파라미터들은 동일한 조건 하에서 생성되었다. 그러나 각 Case들은 열차하중 조건이 변경됨에 따라 주행안전성 및 승차감 검토 결과 산정되는 출력파라미터의 양상은 차이를 보이고 있다(Figs. 4, 5).
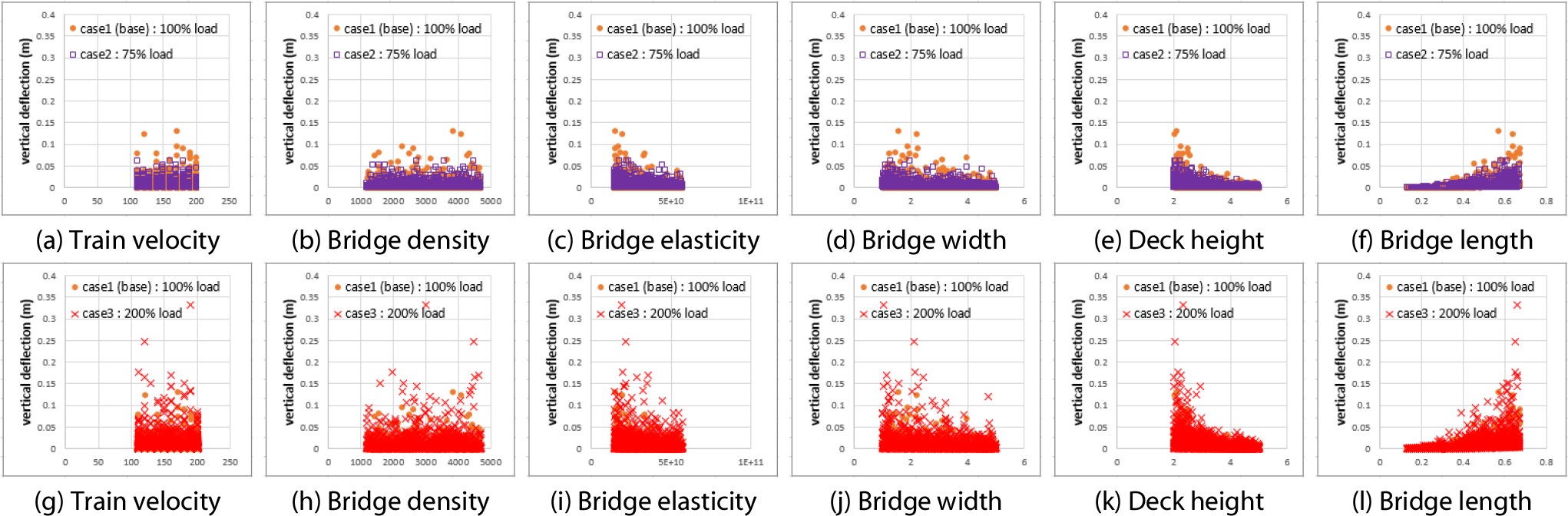
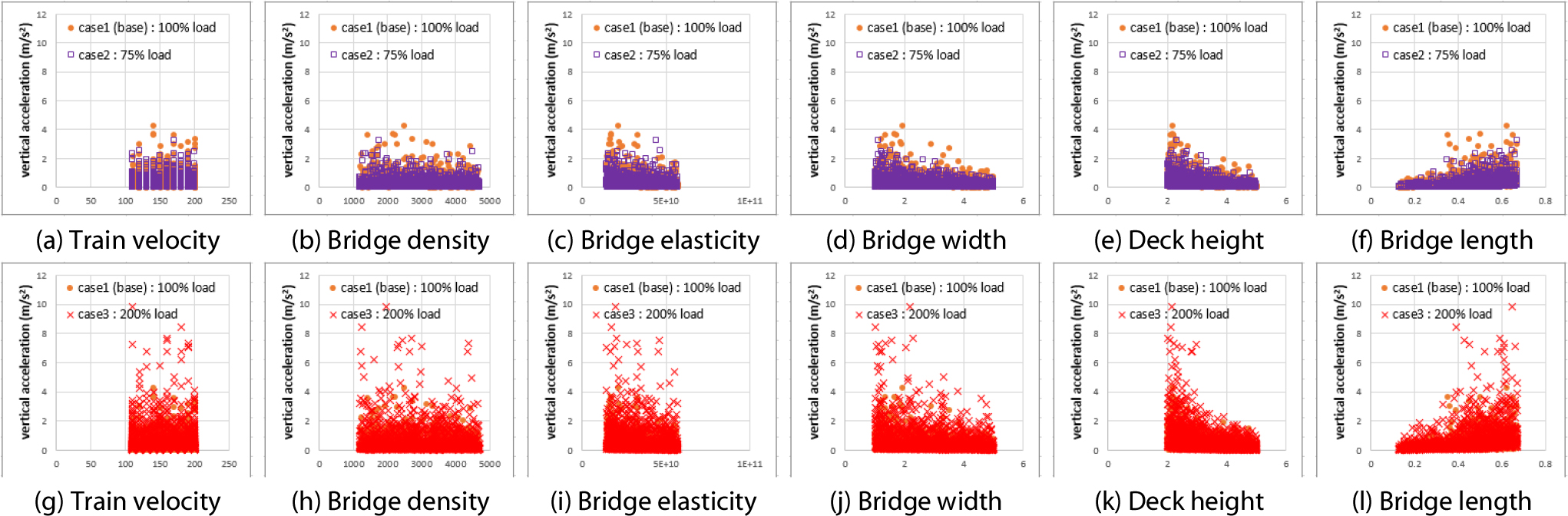
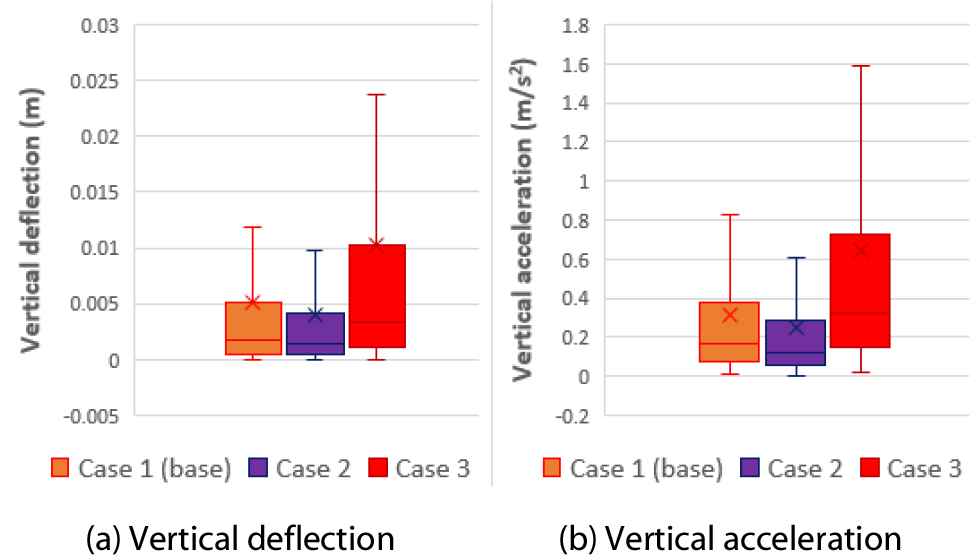
Fig. 4는 각 입력파라미터별 연직처짐 산정 결과이다. Fig. 4(a)~4(f)는 각 입력파라미터별로 Case 1과 Case 2의 학습데이터를 비교한 결과이며, Fig. 4(g)~(l)은 Case 1과 Case 3을 비교한 결과이다. Fig. 5는 각 입력파라미터별 연직가속도 산정 결과이다. Fig. 5(a)~5(f)는 Case 1과 Case 2를 비교한 결과이며, Fig. 5(g)~(l)은 Case1과 Case 3을 비교한 결과이다. Fig. 4 및 Fig. 5에서 각 데이터들은 전체적인 분포양상에 차이가 있음을 확인할 수 있다. Fig. 4에 제시된 Case 1과 Case 2의 비교 결과를 통해 Case 2의 연직처짐 결과가 더 작은 값에 분포함을 확인할 수 있고, Case 1과 Case 3의 비교 결과를 통해 Case 3의 연직처짐 결과가 더 큰 값에 분포함을 확인할 수 있다. Fig. 5의 경우에도 Fig.4와 마찬가지로 연직가속도의 크기는 Case 3, Case 1, Case 2 순으로 크게 분포하였다. 이는 각 Case별 데이터의 통계적인 특성을 요약한 Fig. 6에서도 확인 가능하며, 각 열차하중에 대해 출력파라미터들이 어느 정도 비례관계를 가진다고 판단할 수 있다.
이와 같은 높은 상관성은 출력데이터들이 계산되는 과정들이 일정한 규칙에 의해 표현될 수 있다고 판단할 수 있는 근거가 된다. 한편, 각 파라미터들은 단순히 비례관계를 가지는 것이 아닌, 다소 불규칙한 상관관계를 보이는 것을 Fig. 4 및 Fig. 5의 데이터 분포양상에서 확인할 수 있다. 학습데이터들의 이러한 비선형적인 분포양상은 주행안전성 및 승차감 검토 절차 수행 시 산정되는 동적 응답들이 구조모델이 가지는 비선형성과 더불어 구조물의 동적특성 및 동적 응답 증폭 현상 등이 교량의 응답이 반영되어 나타난 것으로 판단된다. 이 때문에 복잡한 상관관계의 모사가 가능한 예측 모델을 적용할 필요가 있으며, 딥러닝 기반 모델은 이러한 비선형성을 모사하는데 매우 적합한 모델 중 하나이다. 또한, 앞서 언급한 전・후 데이터 간의 높은 상관성은 전이학습 시 적은 데이터만을 사용할 수 있는 근거가 된다.
3.3 전이학습 시나리오
각 Case별로 구축한 데이터베이스를 활용하여 각 시나리오별 전이학습을 수행하였고 전체적인 흐름은 Fig. 7과 같다.
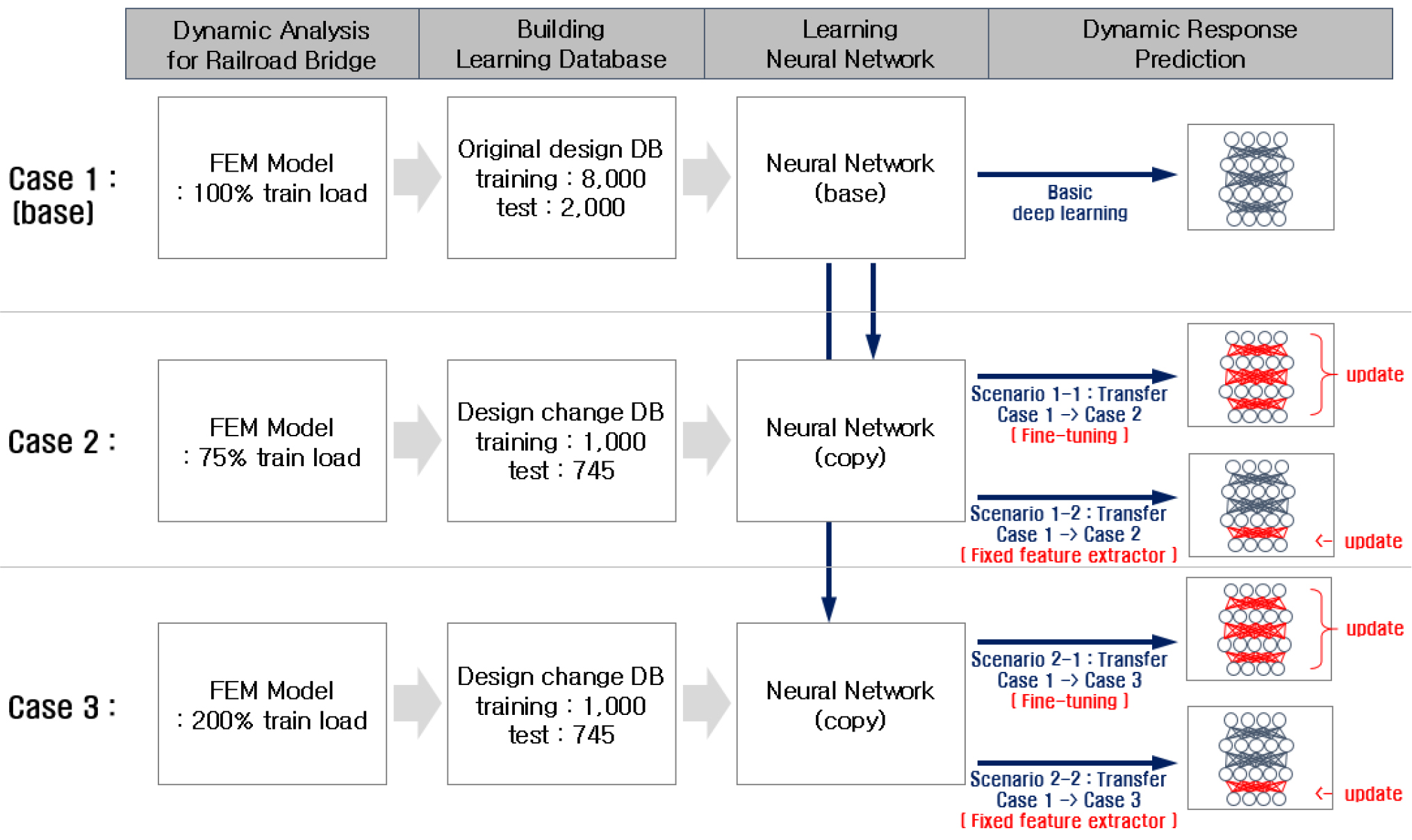
모든 시나리오는 공통적으로 기존 도메인인 Case 1에서 기본적인 딥러닝 학습을 통해 예측 모델을 구축한다. 이후에는 전이학습 시나리오별로 과정에 차이가 있으며, 시나리오 1-1의 경우 Case 1에서 구축된 예측 모델이 Case 2로 전이되며 미세조정기법을 통한 전이학습을 수행한다. 시나리오 1-2의 경우 Case 3으로 전이되고 고정특징추출기법을 통한 전이학습을 수행한다. 시나리오 2-1은 Case 3으로 전이되어 미세조정기법을 통한 전이학습을 수행하고, 시나리오 2-2는 Case 3으로 전이되어 고정특징추출기법을 통한 전이학습을 수행한다. 또한 전이 후 기본적인 딥러닝 학습을 그대로 수행하는 것은 기법의 특성상 미세조정기법에 비해 낮은 성능을 초래하므로 별도의 비교 Case를 마련하지 않았다.
학습데이터의 경우 Case 1에서 기본적인 딥러닝 학습을 통해 예측 모델을 구축할 때에는 기존 설계 데이터베이스에서 8,000개를 이용하였다. 반면, Case 2, 3에서 전이학습을 통해 예측 모델을 학습할 때에는 각 Case 내의 설계변경 데이터베이스에서 1,000개씩만을 이용하였다.
3.4 전이학습 결과분석
각 학습에 대한 신경망의 예측성능은 출력파라미터인 교량 연직처짐 및 교량 연직가속도에 대한 예측정확도(Prediction accuracy)을 통해 확인하였다. 예측은 주행안전성 및 승차감 검토 절차 수행 결과 해석된 구조모델의 최대 동적응답이 기준치를 만족하는지 여부를 판단하는 것을 신경망이 대체하는 것을 가리킨다. 신경망이 상기 과정을 대신 수행하여 기준치 만족 여부를 판단하였을 때, 서로의 결과가 일치한다면 옳게 판단한 결과(TP: True Positive; TN: True Negative)이고 서로의 결과가 일치하지 않는다면 틀리게 판단한 결과(FP: False Positive; FN: False Negative)에 해당한다. 예측정확도는 이를 종합하여 식 (1)과 같이 산정된다.
Figs. 8, 9, 10, 11는 연직처짐에 대한 각 시나리오별 검토 결과이다. Fig. 8은 시나리오 1-1에서 각 학습에 의한 신경망의 구축 시 반복 횟수(Iter.: Iteration)에 따른 해당 시점에서의 연직변위에 대한 예측정확도 산정 그래프이다(X-axis: iteration, Y-axis: prediction accuracy). Fig. 9는 시나리오 1-2에서 연직 변위에 대한 각 학습 간의 비교이고, Fig. 10은 시나리오 2-1, Fig. 11은 시나리오 2-2에 대한 비교이다. Fig. 8, 9, 10, 11의 (a)에 해당하는 기본적인 딥러닝 학습일 경우 모든 시나리오에서 공통적으로 수렴 시점에 도달하는데 소요되는 반복 횟수가 더 많은 것으로 나타났다. Fig. 8, 9, 10, 11의 (b)에 해당하는 전이학습의 경우 상대적으로 적은 반복 횟수 안에 수렴하였고, 전이학습 시 미세조정기법을 적용한 Fig. 8과 Fig. 10에 비해 고정특징추출기법을 적용한 Fig. 9와 Fig. 11이 초기 예측정확도가 낮게 산정되는 것을 확인할 수 있다.
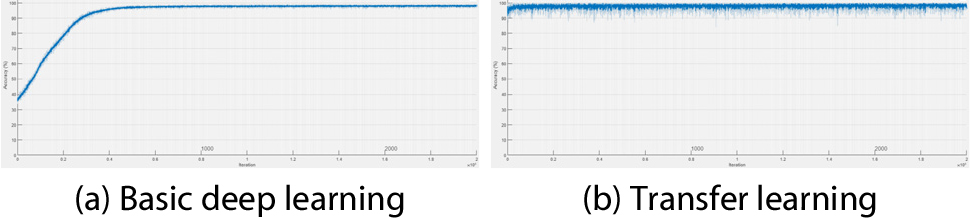
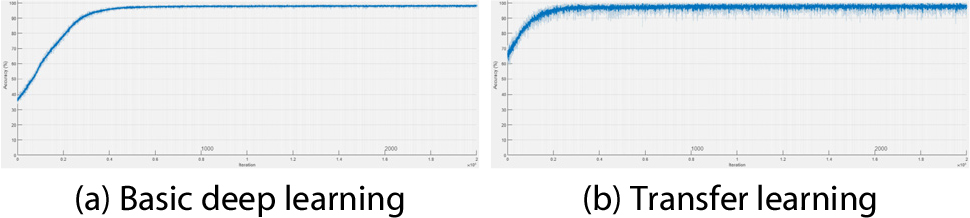
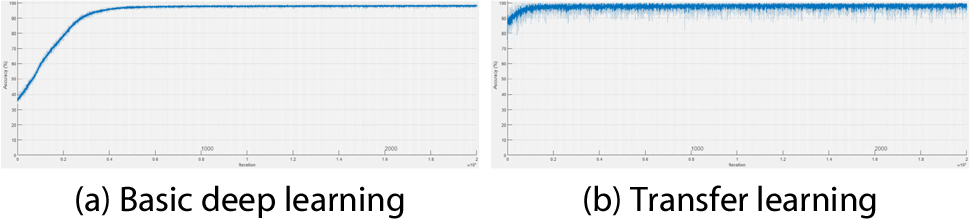
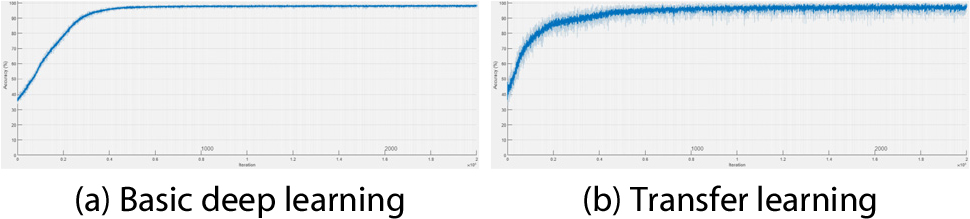
Fig. 12, 13, 14, 15는 연직가속도에 대한 각 시나리오별 검토 결과이다. Fig. 12는 시나리오 1-1에서의 각 학습에 의한 신경망 구축 시 반복 횟수에 따른 해당 시점에서의 예측정확도 산정 결과이다. Fig. 9는 시나리오 1-2에서의 각 학습 간 비교 결과이고, Fig. 10은 시나리오 2-1, Fig. 11은 시나리오 2-2에 대한 비교 결과이다. 학습양상은 연직처짐일 때와 유사하였다. 단 Fig. 13(b)의 경우 초기 예측정확도가 낮게 산정되었다.
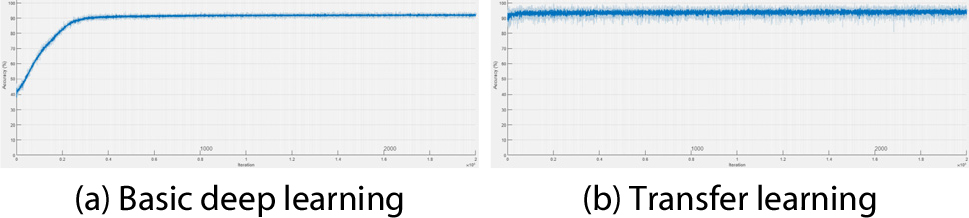
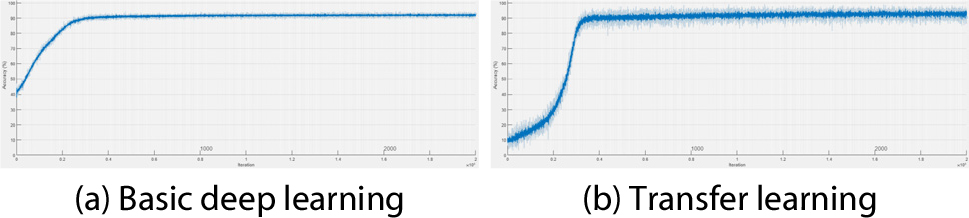
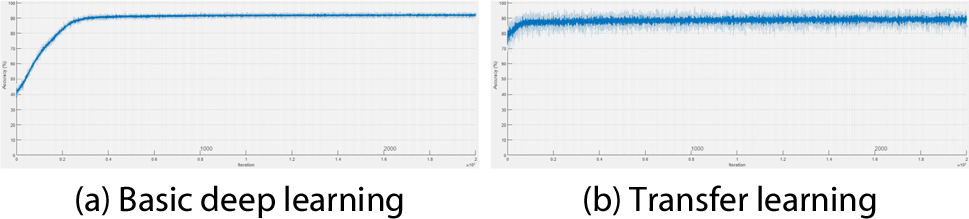
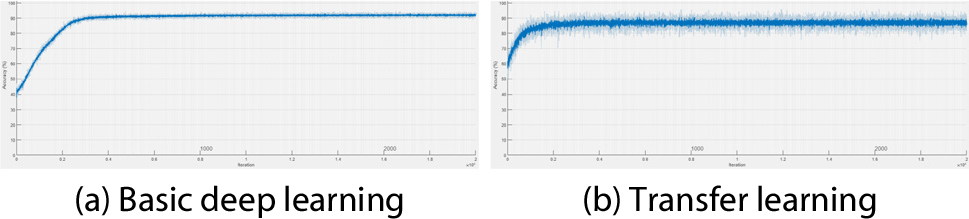
Table 2, 3은 각 시나리오별 학습조건에 따라 예측성능을 비교한 결과이다. Table 2는 연직처짐, Table 3은 연직가속도에 대한 결과이며 시나리오별 예측 결과는 학습조건에 따라 크게 3가지 경우로 구분하였다(Case A~Case C). Case A는 기본적인 딥러닝 학습에 의한 신경망 구축 후 기존 설계 데이터베이스의 테스트데이터에 대한 예측을 수행하는 경우이다. Case B는 Case A에서 구축된 신경망을 그대로 사용하여 각 설계변경 데이터베이스의 테스트데이터에 대한 예측을 수행하는 경우이다. Case C는 각 전이학습 기법에 의해 재구축된 신경망을 사용하여 설계변경 데이터베이스의 테스트데이터에 대한 예측을 수행하는 경우이다.
예측성능은 식 (1)의 예측정확도와 수렴 시간(Convergence time)을 통해 확인하였다. 참고로 수렴 시간은 신경망 학습 시 수렴에 도달하기까지 소요된 반복 횟수를 의미하며, 별도의 규정이 존재하지 않기 때문에 본 연구에서는 수렴 여부의 판단조건을 식 (2)와 같이 산정하였다.
여기서, 는 수렴 여부 판정 시 전이학습 전・후 간 학습데이터 수가 달라 발생하는 노이즈 차를 보정을 위한 시점의 이동평균으로 식 (3)를 이용하여 산정한다. 는 수렴 여부를 판단하는 기준치로 이 연구에서는 전체 결과들의 양상들을 비교하여 5.0×10-4 미만일 경우 해당 시점에서 예측값이 수렴하였다고 판단하였다.
Table 2의 연직처짐에 관한 예측성능 검토 결과 기본적인 딥러닝 모델의 예측정확도는 기존 설계 데이터베이스에 대해 97.84%로 산정되었지만, 설계변경 데이터베이스에 적용 시 시나리오 1의 경우 94.36%, 시나리오 2의 경우 85.10%로 낮아지는 것으로 나타났다. 한편, 전이학습 모델의 예측정확도는 설계변경 데이터베이스에 적용 시 시나리오 1-1에서는 97.58%, 시나리오 1-2에서는 98.39%, 시나리오 2-1에서는 98.26%, 시나리오 2-2에서는 98.12%로 기본적인 딥러닝 모델과 비교하였을 때 대부분 높게 산정되었다. 수렴 시간의 경우 전이학습 기법 간 차이가 있는 것으로 나타났다. 시나리오 1-1과 2-1의 미세조정기법의 경우 559회의 계산과 2,863회의 계산만으로 수렴조건을 만족시켜 기본적인 딥러닝 모델에서의 9,390회 대비 빠른 시간에 수렴함을 확인할 수 있었다. 한편, 시나리오 1-2와 2-2의 고정특징추출기법의 경우 8,083회와 12,319회의 반복 횟수에서 수렴하여 기본적인 딥러닝 모델의 9,390회 대비 우월성을 확인할 수 없었다.
Table 2.
Accuracy and iteration of scenarios(Vertical deflection)
Table 3의 연직가속도에 관한 예측성능 검토 결과 기본적인 딥러닝 모델의 예측정확도는 기존 설계 데이터베이스에 대해 91.53%로 산정되었지만, 설계변경 데이터베이스에 적용 시 시나리오 1의 경우 89.26%, 시나리오 2의 경우 75.44%로 낮아지는 것으로 나타났다. 한편 전이학습 모델의 예측정확도는 설계변경 데이터베이스에 적용 시 시나리오 1-1에서는 91.14%, 시나리오 1-2에서는 90.47%, 시나리오 2-1에서는 87.38%, 시나리오 2-2에서는 88.46%로 기본적인 딥러닝 모델과 거의 비슷하거나 다소 낮게 산정되었다. 수렴 시간의 경우 각 시나리오별로 차이가 존재하였다. 시나리오 1-1, 1-2, 2-1 및 2-2에서 각각 2,813회, 14,771회, 12,834회 및 3,665회의 수렴 시간이 산정되었다. 분석 결과 연직가속도 응답에서는 두 전이학습 기법 간 수렴 시간의 차이를 확인할 수 없으나, 전체적인 그래프 양상을 통해 시나리오 1-2의 Case C를 제외하고는(Fig. 13(b)) 기본적인 딥러닝 모델을 적용한 경우들(Fig. 12(a), Fig. 13(a), Fig. 14(a) 및 Fig. 15(a))에 비해 80% 이상의 예측정확도에 적은 반복 횟수 만에 도달하여 설정한 수렴 기준치를 만족하지는 못하였지만 전이학습 Case들이 대체로 빠른 초기 수렴 속도를 보이는 것을 확인할 수 있었다.
Table 3.
Accuracy and iteration of scenarios (Vertical acceleration)
4. 결 론
본 연구에서는 전이학습을 활용하여 기존 철도교량 동적응답 예측 시스템의 딥러닝 모델 구축성능을 향상시키기 위한 연구를 수행하였다. 전이학습 기법 중 미세조정 기법과 고정특징추출 기법의 적용성을 검토하기 위해 열차하중 조건 변경에 따른 설계변경 시나리오들을 작성하여 전이학습 전후의 동적응답 예측성능을 비교・검토하였으며, 다음과 같은 결론을 얻을 수 있었다.
딥러닝 기법 기반 예측 시스템이 충분한 성능을 발휘하기 위해서는 딥러닝 모델이 사전에 학습하기 위한 충분한 양의 데이터를 준비할 필요가 있고, 기존 연구에서는 주행안전성 및 승차감 해석 과정의 자동화 프로그램을 개발하여 이를 해결하였으나 대량의 학습데이터 생성 시 많은 시간이 소요되었다. 이 연구에서는 전이학습 기법 적용 시 기존 8,000개의 학습데이터 대비 전이 후 1,000개의 학습데이터만을 이용하여 기존과 동등한 예측정확도에 도달하는 것을 확인하였으며, 전이학습 적용 시 적은 데이터만으로도 학습이 가능함을 실증하였다. 또한 시나리오별 차이는 존재하였지만 전이학습 적용 시 대체로 적은 횟수만으로도 빠르게 수렴구간에 도달하는 것을 확인할 수 있었다.
동적응답별 검토 시 연직변위에 비해 연직가속도에 대한 전이학습을 수행할 때 비교적 불안정한 학습 결과가 나타났다. 연직가속도의 경우 기존 연구(Kim and Choi, 2022)를 통하여 구축된 딥러닝 모델에서 예측정확도가 상대적으로 낮은 응답이었으며, 전이학습은 기구축된 딥러닝 모델의 하이퍼파라미터와 신경망 구조를 활용한다는 특징이 있으므로 이러한 부분이 전이학습 성능에 영향을 미친 것으로 판단된다. 기구축된 딥러닝 모델의 예측성능이 낮아 야기되는 전이학습 성능 저하는 Table 2와 Table 3 간의 비교를 통해 수렴 시간이 증가하는 것을 통해 확인할 수 있다. 참고로 전이학습 전후 간에 예측정확도에 미치는 영향은 확인할 수 없었다.
전이학습 적용 시 효과를 뚜렷하게 확인할 수 있도록 설계변경 시나리오의 변경 폭을 의도적으로 조정하였다. 도메인 간 상관성을 유지하기 위해 기존 도메인과 새로운 도메인 간에는 열차하중 조건 변경에 따른 동적응답 결과 차이와 전체 데이터 수의 차이만이 존재하게끔 하였다. 각 도메인 간 변경 폭이 작을지라도 기구축된 딥러닝 모델을 그대로 사용할 경우 예측정확도가 91.53~97.84%에서 75.44%~94.36%로 낮아진다는 것을 확인할 수 있었고, 전이학습을 활용하여 예측정확도를 87.38~98.39%까지 복구 가능함을 실증하였다.
Case A와 Case B의 결과는 설계변경 시 딥러닝 모델을 그대로 사용할 수 없고 재구축이 필요함을 시사한다. 이는 하중이 변경됨에 따라 알고리즘 학습 측면에서는 설계 변경 전・후가 서로 다른 특성을 지닌 집단이 되었기 때문이다. 재구축의 경우 기본적인 딥러닝 모델을 통해서도 가능하지만, 매번 재구축 시마다 대량의 학습데이터를 재생성하는 것은 매우 비효율적이다. Case C의 결과는 설계변경 시 전이학습이 기본적인 딥러닝 학습을 대체할 수 있음을 시사한다. 1/8의 데이터만으로도 기존과 동등한 성능을 발휘할 수 있음을 실증하였고 학습 속도에 이익이 있음을 확인하였다. 전이학습에 의한 성능향상을 확인할 수 있었던 것은 알고리즘 개념상 전・후 도메인 간에 일정한 상관성이 있었기 때문인 것으로 유추할 수 있다. 이 연구에서는 전이학습 기법의 적용 가능성 검토를 수행하였으며, 전이학습의 성능과 상관성에 대한 관계는 검토하지 않았으나, 추후 연구에서는 전이학습이 전이 전후 도메인 간의 상관성 차이를 얼마나 허용하는지에 대해서도 면밀한 검토를 수행하여 이를 정량화하는 연구를 수행할 계획이다.
또한 예상치 못한 변수를 최대한 배제한 상태에서 알고리즘을 보다 정확히 제어하기 위해서 열차하중의 변화만을 제어한 한계가 존재한다. 실제 설계 변경 사례의 모사를 위해서는 변화된 재료, 단면의 변화 등의 경우들도 고려되어야 하므로 추후 연구에서는 다양한 종류의 파라미터에 대한 전이학습의 성능검토를 수행하여 실제 설계 시의 활용성을 높일 수 있도록 적용 범위를 확장할 계획이다.
