

1. 서 론
구조실험과 관련된 여러 가지 정보를 체계적으로 정리하고 저장하여 컴퓨터 시스템으로 구현한 데이터 저장소는 구조공학자들이 실험정보를 편리하게 살펴볼 수 있는 큰 장점이 있다. 특정한 종류의 구조실험에 대한 소규모 데이터 저장소의 예로는 철골구조 접합부의 실험정보를 저장하고 있는 SAC Design Information (http://www.sacsteel.org/design)과 정방형과 나선형 철근콘크리트 기둥의 내진성능 실험정보를 저장하고 있는 PEER Structural Performance Database (http://nisee.berkeley.edu/spd) 등이 있으며 큰 규모의 데이터 저장소의 예로는 NEEShub Project Warehouse (https://nees.org)가 있는데 구조실험을 포함한 다양한 종류의 실험정보를 저장하고 있다.
국내에서는 국토교통부 지원으로 구축된 6개 대학의 대형실험시설을 네트워크로 연결하여 관리하는 건설연구인프라운영원(http://www.koced.net)에서 실험정보를 테스트별로 폴더에 구분하여 저장하고 실험체 및 계측기 정보를 별도의 파일로 저장하는 등의 기능을 수년전부터 개발하고 개선하고 있어서 NEEShub Project Warehouse와 같은 수준의 데이터 저장소가 되기 위한 노력을 계속하고 있다. 국내외 2,000여종의 토목공학 관련 연구문헌 1,800,000개의 DB를 구축하고 있는 CERIC(http://www.ceric.net)은 논문과 보고서 등의 자료이외에 실험정보를 저장할 수 있는 기능을 확충한다면 훨씬 유용한 데이터 저장소로 발전할 수 있는 가능성을 가지고 있다.
구조실험 정보를 위한 데이터 저장소를 개발하기 위해서는 범위로 정한 모든 데이터를 저장할 수 있는 충분한 용량, 저장과 탐색에 소요되는 시간, 데이터 손실방지 등의 유지 관리에 대한 점도 고려해야 하지만 실험정보의 구성이라는 관점에서 보면 정보 구성을 표현하는 데이터 모델부터 주의를 기울여야 한다(Lee, 2010a). 데이터 모델 및 데이터 저장소는 개발과정 중에 또는 개발이 완료된 후에 본래의 목적에 알맞도록 개발이 되었는지에 대한 평가가 필요한데 데이터 모델 및 데이터 저장소의 특성을 수치적으로 나타낼 수 있는 기본특성 평가요소(Lee, 2010b)와 레벨별 특성 평가요소(Lee, 2013)가 제안되었다.
데이터 저장소의 실험정보를 데이터 모델의 개발에 많이 사용하는 클래스(class)와 객체(object)의 개념을 이용하여 표현하면 데이터 저장소에 실재하는 하나의 단위 실험정보를 객체라고 하고 같은 종류의 객체를 생성할 수 있는 템플릿(template)을 클래스라고 할 수 있다. 하나의 실험 프로젝트는 여러 개의 객체를 포함하고 있고 이 객체들은 그에 해당하는 클래스들로부터 생성된 것이다. 다시 말하면 데이터 저장소가 적절한 클래스 구성을 만들어 놓으면 실제 실험 프로젝트의 정보는 객체들을 이용하여 표현이 된다. 데이터 저장소의 평가에 대한 기존 연구(Lee, 2010b; 2013)는 클래스의 구성과 클래스로부터 생성된 객체의 구성을 수치적으로 나타내어 비교하고 분석하는 것을 가능케 하였다. 본 논문에서는 기존연구에서 다루지 않았던 개개의 클래스와 객체의 내부가 어떻게 구성되어 있는가를 클래스와 객체가 가지고 있는 속성(attribute)을 이용하여 평가할 수 있는 수치적 평가요소를 제시하고자 한다.
2. 데이터 저장소의 클래스와 객체의 속성구성 평가의 필요성과 범위
구조실험을 위한 데이터 저장소가 적절한 클래스 구성을 만들어 놓으면 실제 실험 프로젝트의 정보는 객체들을 이용하여 표현할 수 있으므로 클래스에 대한 평가는 데이터 저장소의 자체적인 구성에 대한 평가를 의미하며 객체에 대한 평가는 실제의 실험정보 구성(데이터 저장소의 활용)에 대한 평가를 의미한다.
본 논문에서 데이터 저장소의 클래스와 객체의 표현은 개체형 통합설계모델(Hong et al., 1994; Lee et al., 1998)의 표기법을 이용하였다. Fig. 1, Fig. 2, Fig. 3, Fig. 6에서 클래스는 사각형으로 객체는 타원으로 표시하였으며 속성은 사각형 또는 타원 아래에 수평선과 함께 나타내었다. Fig. 1에서는 단순한 표현을 위해서 속성의 종류 표시는 생략하였지만 다른 그림들에서는 단일 값을 갖는 속성(SVA; single- valued attribute)이면 수평선의 끝을 흰색 원으로 복수의 값을 갖는 속성(MVA, multi-valued attribute)이면 수평선의 끝을 검은색 원으로 표시하였다. 속성의 수평선 아래의 괄호에는 속성의 또 다른 종류 정보가 있는데 B는 기본속성(base attribute)을 DVA는 숫자, 문자, 파일 등을 값으로 갖는 속성(data-valued attribute)을 의미하며 OEVA는 다른 객체를 값으로 갖는 속성(object entity-valued attribute)을 의미한다.
임의의 데이터 저장소의 구성을 클래스로 나타내고 실험정보를 객체로 나타냈을 때 Fig. 1은 클래스와 객체의 일부를 나타내는 예이다. 전체의 클래스들은 n개 레벨에 걸쳐서 분포하며 각각의 클래스는 속성을 포함하고 있다. 예를 들면 클래스 i는 j개의 속성을 포함하고 있으며 클래스 p는 q개의 속성을 포함하고 있다. 이러한 구성의 데이터 저장소에 실제의 실험정보를 저장하면 세부 실험정보는 특정한 객체로 나타낼 수 있는데 객체 i1은 클래스 i로 부터 객체 p1과 p2는 클래스 p로부터 생성된 것이다. 객체의 속성들은 그 속성의 종류에 따라서 속성 값을 가질 수도 있고 가지지 않을 수도 있다.
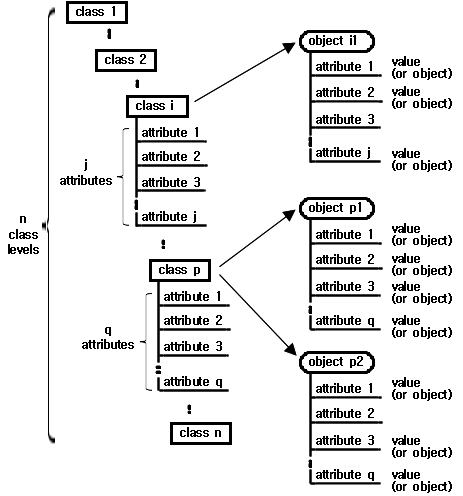
Fig. 1의 클래스들과 객체들의 구성에 대한 평가를 위하여 기존연구에서 개발된 기본특성 평가요소들로는 총 클래스수, 총 객체수, 클래스내 속성수, 클래스내 속성사용비율 등이 있으며 특정정보에 이르기까지의 경로를 나타내는 클래스와 객체 경로상의 선택수 등이 있다(Lee, 2010b). 레벨별 클래스 특성을 나타내는 평가요소들로는 레벨에서의 클래스수와 속성수, 하위레벨에서의 클래스수와 속성수 등이 있다(Lee, 2013). 기존연구들에서 개발된 평가요소들은 데이터 저장소의 전체적인 구성과 레벨별 구성을 파악하는데 반드시 필요한 것이었지만 개별적인 클래스와 객체의 내부적 구성 특성과 연계하는데 이르지는 못하였다. 본 논문에서는 개별적인 클래스와 객체의 특성을 속성의 종류에 근거하여 수치화하여 표현하는 평가요소를 정의하고 기존에 개발된 평가요소들과 결합함으로서 넓은 관점에서부터 좁은 관점에 이르기까지 클래스와 객체에 대한 평가요소를 확보하고자 한다.
3. 데이터 저장소의 클래스와 객체의 속성구성 평가요소
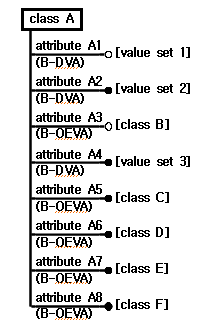
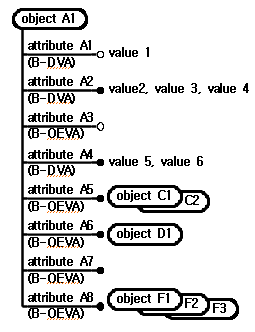
데이터 저장소의 클래스와 객체의 속성구성 평가요소는 Fig. 2와 Fig. 3에 나타난 클래스와 객체를 이용하여 설명하고자 한다. Fig. 2의 클래스 A와 Fig. 3의 객체 A1은 Fig. 1의 여러 레벨에 걸쳐서 있는 클래스와 객체 중에서 임의의 것이다. 클래스 A는 8개의 속성을 포함하고 있으며 객체 A1은 클래스 A1으로부터 생성된 것으로서 일부 속성들은 값을 가지고 있고 다른 속성들은 값을 가지고 있지 않다. 클래스 A를 이용하여 클래스 속성구성 평가요소를 설명하고 객체 A1을 이용하여 객체 속성구성 평가요소를 설명한다.
3.1 데이터 저장소의 클래스 속성구성 평가요소
데이터 저장소의 클래스 속성구성 평가요소는 Table 1에 나타나 있으며 Fig. 2의 클래스 A에 대하여 적용했을 때 평가요소의 수치도 함께 나타나 있다.
Table 1
Definition of evaluation criteria of attributes of class
Table 2
Relationships among evaluation criteria of attributes of class
Table 1에서 클래스내 속성수(number of attributes in class)는 클래스에 대한 기본정보로서 클래스가 포함하고 있는 모든 속성의 수를 의미한다. 속성의 종류에 대하여는 클래스 DVA수(number of class DVA's), 클래스 OEVA수(number of class OEVA's), 클래스 SVA수(number of class SVA's), 클래스 MVA수(number of class MVA's)가 있으며 이것들을 클래스내 속성수로 나누면 클래스 DVA 비율(ratio of class DVA's), 클래스 OEVA 비율(ratio of class OEVA's), 클래스 SVA 비율(ratio of class SVA's), 클래스 MVA 비율(ratio of class MVA's)이 된다.
Table 1에서 설명한 평가요소들을 살펴보면 평가요소의 정의에 따른 자연스런 관계가 Table 2와 같이 성립함을 알 수 있다. 클래스 속성은 DVA 또는 OEVA이므로 클래스 DVA수와 클래스 OEVA수를 더하면 클래스내 속성수가 된다. 클래스 속성은 SVA 또는 MVA이므로 클래스 SVA수와 클래스 MVA수를 더하면 클래스내 속성수가 된다. 또한 클래스 DVA 비율과 클래스 OEVA 비율을 더하면 1.0이 되고 클래스 SVA 비율과 클래스 MVA 비율을 더해도 1.0이 된다.
Table 1과 Table 2에 나타난 클래스 속성구성 평가요소와 평가요소간의 관계를 통하여 클래스 속성구성을 수치적인 방법을 이용하여 나타내고 설명할 수 있다. 클래스내 속성수가 크면 기본적으로 클래스의 구성이 복잡하고 속성수가 작으면 단순하다고 볼 수 있다. 클래스 DVA 비율이 높으면 단편적인 정보가 많이 있는 구성이고 클래스 OEVA 비율이 크면 하위레벨이 많이 있는 구성을 의미한다. 클래스 SVA 비율이 높으면 단일 값을 갖는 정보를 많이 저장하도록 되어 있고 클래스 MVA 비율이 높으면 복수의 값을 갖는 정보를 많이 저장하도록 되어 있는 구성이다.
3.2 데이터 저장소의 객체 속성구성 평가요소
데이터 저장소의 객체 속성구성 평가요소는 Table 3에 나타나 있으며 Fig. 3의 객체 A1에 대하여 적용했을 때 평가요소의 수치도 함께 나타나 있다.
Table 3
Definition of evaluation criteria of attributes of object
Table 4
Relationships among evaluation criteria of attributes of object
Table 3에서 객체내 값있는 속성수(number of valued attributes in object)는 객체가 포함하고 있는 속성 중에서 속성 값을 가진 것들의 수를 의미하며 이 수를 클래스내 속성수로 나누면 객체내 값있는 속성 비율(ratio of valued attributes in object)이 된다. 객체 DVA수(number of object DVA's), 객체 OEVA수(number of object OEVA's), 객체 SVA수(number of object SVA's), 객체 MVA수(number of object MVA's)는 각각 값있는 DVA, OEVA, SVA, MVA의 수를 의미한다. 이것들을 객체내 값있는 속성수로 나누면 객체 DVA 비율(ratio of object DVA's), 객체 OEVA 비율(ratio of object OEVA's), 객체 SVA 비율(ratio of object SVA's), 객체 MVA 비율(ratio of object MVA's)이 된다. Table 3의 평가요소들을 살펴보면 평가요소의 정의에 따른 자연스런 관계가 Table 4와 같이 성립하는데 클래스의 경우와 유사하다.
Table 3과 Table 4에 나타난 객체 속성구성 평가요소와 평가요소간의 관계를 통하여 객체 속성구성을 수치적인 방법을 이용하여 나타내고 설명할 수 있다. 객체내 값있는 속성 비율이 높으면 속성의 활용도가 높은 것으로 비율이 낮으면 활용도가 낮은 것으로 볼 수 있다. 객체 DVA, OEVA, SVA, MVA 비율은 클래스의 경우와 유사하지만 실제정보에 대한 것이라는 게 다른 점이다.
4. 데이터 저장소의 클래스와 객체의 속성구성 평가요소의 적용
데이터 저장소의 자체적인 구성과 실제 실험정보 구성에 대한 평가를 위하여 본 논문에서 제시된 평가요소를 NEEShub Project Warehouse(https://nees.org)에 대하여 적용하여 그 실용성을 살펴보기로 한다.
4.1 NEEShub Project Warehouse 실험정보
NEEShub Project Warehouse는 미국 NSF의 지원에 의하여 미국 내 14개 대학의 실험실에서 수행중인 다양한 실험정보를 포함하고 있는 데이터 저장소이다. 실험정보는 NEEShub Project Warehouse에서 정한 구성에 따라서 저장하도록 되어 있는데 대략적인 구성이 Fig. 4에 나타나 있다. 하나의 실험 project는 여러 개의 experiment를 포함하고 하나의 experiment는 여러 개의 trial을 포함하고 하나의 trial은 여러 개의 repetition을 포함하는 구성으로 되어 있다. 각각의 레벨에 대하여 해석(analysis)과 문헌(documentation) 정보가 있을 수 있고 하위 레벨에서는 여러 가지 실험 데이터(unprocessed data, converted data, corrected data, derived data)를 저장할 수 있도록 되어 있다.
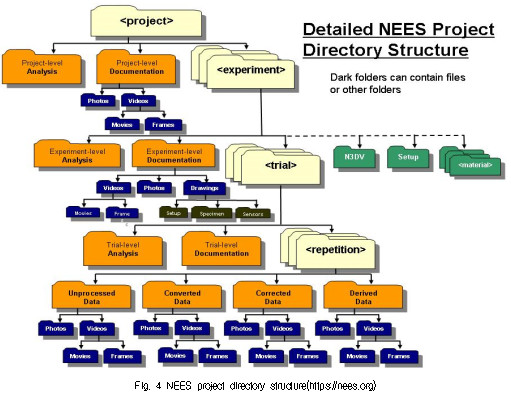
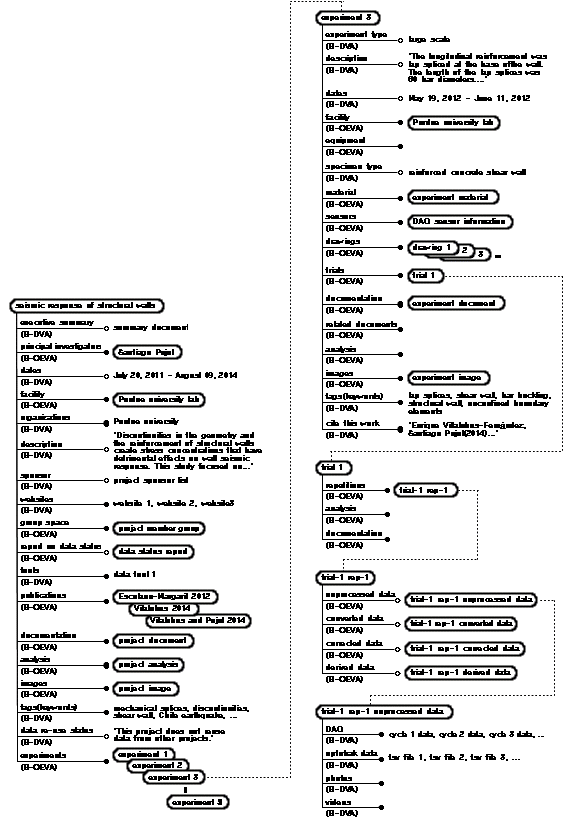
NEEShub Project Warehouse에 있는 실험 중에서 실험정보가 잘 갖추어진 프로젝트를 별도의 그룹(enhanced projects)으로 만들어 놓았는데 여기에서 하나의 예로 선택한 것이 최근 4년간 Purdue 대학교에서 수행한 내력벽의 내진성능 실험으로서 실험체의 사진중의 하나가 Fig. 5에 나타나 있다. 이 실험 프로젝트에 대한 많은 분량의 실험정보가 있는데 그중 일부를 발췌하여 개체형 통합설계모델(Hong et al., 1994; Lee et al., 1998)의 표기법에 의하여 표현한 것이 Fig. 6에 나타나 있다.
Fig. 4와 Fig. 6을 비교하면 Fig. 4에서 project에 해당하는 것이 Fig. 6에서 seismic response of structural walls 객체로서 상당히 많은 수의 속성과 속성값을 포함하고 있다. Fig. 4에서 experiment에 해당하는 것이 Fig. 6에서 experiment 1 객체부터 experiment 8 객체까지이며 이중에서 experiment 3 객체에 대하여 그 속성이 나타나 있다. Fig. 4에서 trial과 repetition에 해당하는 것은 Fig. 6에서 trial 1 객체와 trial-1 rep-1 객체이다. Fig. 4에서 최하위 레벨에 있는 unprocessed data에 해당하는 것은 Fig. 6에서 trial-1 rep-1 unprocessed data 객체로서 실험 데이터 파일들을 포함하고 있다. Fig. 6에 나타난 객체들과 이 객체들에 해당하는 클래스들(객체들로부터 유추할 수 있다)에 대하여 속성구성을 평가하도록 한다.

4.2 NEEShub Project Warehouse에 대한 클래스 속성구성 평가요소의 적용
Fig. 6에 나타난 객체들에 해당하는 클래스들은 앞에서 언급한대로 Fig. 4와의 비교로부터 유추할 수 있다. 예를 들면, Fig. 6에서 seismic response of structural walls 객체는 project 클래스로부터 생성된 것이고 experiment 3 객체는 experiment 클래스로부터 생성된 것이다. trial 1 객체, trial-1 rep-1 객체, trial-1 rep-1 unprocessed data 객체는 각각 trial 클래스, repetition 클래스, unprocessed data 클래스로부터 생성된 것이다. 이 5개의 클래스들에 대하여 속성구성 평가요소를 적용한 결과가 Table 5에 나타나 있다.
Table 5의 속성구성 평가요소는 클래스에 대한 것으로 클래스의 속성은 Fig. 6에서 객체의 속성을 살펴보면 된다. Table 5에서 project 클래스(Fig. 6의 seismic response of structural wall 객체에 해당하는 클래스)는 클래스내 속성수가 18이라는 큰 수이므로 클래스의 구성이 복잡하다는 것을 의미한다. 클래스 DVA수와 클래스 OEVA수는 모두 9로서 단편적인 정보와 하위레벨로 지정한 정보가 동일한 비율이다. 클래스 SVA수와 클래스 MVA수는 각각 6과 12로서 클래스 MVA수가 훨씬 크기 때문에 복수의 값을 갖는 정보를 더 많이 저장하도록 구성하였다. experiment 클래스(Fig. 6의 experiment 3 객체에 해당하는 클래스)는 클래스내 속성수가 16으로 project 클래스에 버금가는 복잡한 구성을 가지고 있다. 클래스 DVA수와 클래스 OEVA수는 각각 6과 10이고 클래스 SVA수와 클래스 MVA수는 각각 4와 12이므로 하위레벨을 많이 가진 복수의 값을 갖는 정보를 많이 저장하는 클래스라는 것을 알 수 있다. trial 클래스, repetition 클래스, unprocessed data 클래스(Fig. 6의 trial, trial-1 rep-1, trial-1 rep-1 unprocessed data 객체에 해당하는 클래스)는 클래스내 속성수가 작은 단순한 구성을 가지고 있다. 클래스 DVA수 또는 클래스 OEVA수 중에서 어느 한 쪽이 전체를 차지하며 클래스 SVA수와 클래스 MVA수의 경우도 마찬가지로서 클래스 성격에 따라서 하나의 통일된 구성을 가지고 있음을 나타낸다.
Table 5
Evaluation criteria of attributes of classes for experiment of seismic response of structural walls
Table 5의 클래스들은 레벨별로 분포되어 있기 때문에 클래스들을 속성구성별로 비교하면 레벨별 클래스의 속성구성특성을 파악할 수 있다. 클래스내 속성수는 하위레벨로 갈수록 줄어드는데 하위레벨로 갈수록 더 구체적이고 세분화된 실험정보를 저장하도록 구성한 것이다. 클래스 DVA수와 클래스 OEVA수를 살펴보면 상위레벨에서 하위레벨로 갈수록 어느 한쪽으로 몰리게 되는 것은 하위레벨로 갈수록 한 가지 종류의 정리된 실험정보를 저장하도록 구성한 것을 의미한다. 클래스 SVA수와 클래스 MVA수의 경우에도 비슷한 경향을 나타내는데 하위레벨로 갈수록 저장하는 정보의 분량이 명확해지는 것을 나타낸다. 클래스 DVA 비율, 클래스 OEVA 비율, 클래스 SVA 비율, 클래스 MVA 비율은 클래스내 속성수가 큰 상위레벨에서 더 중요한 의미를 지니는데 클래스 OEVA 비율과 클래스 MVA 비율이 높으므로 하위 레벨에서 더 많은 다양한 분량의 구체적인 정보를 저장하도록 구성한 것을 의미하는 것으로 이는 자연스런 현상이라고 할 수 있다. 클래스 내에서 어느 정도의 비율을 하위레벨에 저장하도록 구성할지는 데이터 저장소의 성격에 따라서 달라진다.
4.3 NEEShub Project Warehouse에 대한 객체 속성구성 평가요소의 적용
실제적인 실험정보를 포함하는 Fig. 6의 객체들 중에서 속성이 나타나 있는 5개의 객체(seismic response of structural walls, experiment 3, trial-1, trial-1 rep-1, trial-1 rep-1 unprocessed data)에 대하여 속성구성 평가요소를 적용한 결과가 Table 6에 나타나 있다.
Table 6에서 seismic response of structural walls 객체는 값있는 속성수가 18로서 클래스내 속성수와 동일하므로 객체 DVA수, 객체 OEVA수, 객체 SVA수, 객체 MVA수 등은 클래스에 대한 것들과 동일하다. experiment 3 객체는 값있는 속성수가 13으로서 객체내 값있는 속성 비율이 0.81이 된다. 객체 DVA수와 객체 OEVA수를 살펴보면 클래스의 경우에 비하여 객체 OEVA수가 감소하였는데 이는 하위레벨에 저장하는 실험정보가 데이터 저장소에서 정한 것보다 적다는 것을 의미한다. 객체 SVA수와 객체 MVA수는 클래스의 경우에 비하여 객체 MVA수가 감소하였는데 다양한 분량의 저장을 하는 속성들에 대한 실험정보가 데이터 저장소에서 정한 것보다 적다는 것을 의미한다. trial 1 객체, trial-1 rep-1 객체, trial-1 rep-1 unprocessed data 객체를 살펴보면 trial-1 rep-1 객체는 객체내 값있는 속성 비율이 1.0이지만 다른 두 객체는 0.33과 0.50으로 낮았다. 해당 실험에 대한 정보를 충실하게 저장했다고 가정하면 객체내 값있는 속성 비율이 낮다는 것은 데이터 저장소에서 요구하는 구성이 해당 실험에 알맞지 않은 것으로 볼 수 있다. 최하위레벨에 있는 trial-1 rep-1 unprocessed data 객체의 경우는 최하위레벨에서는 구체적인 실험정보를 저장한다는 점을 감안하면 실험정보의 저장이 제대로 이루어지지 않았거나 또는 데이터 저장소에서 중복되는 장소에 실험정보를 저장하도록 하는 비효율이 있었기에 해당 실험정보를 저장하지 않은 것으로도 추정할 수 있다.
Table 6의 객체들은 레벨별로 분포되어 있기 때문에 속성구성 평가요소에 대하여 객체들을 비교하면 실제 저장된 실험정보의 레벨별 특성을 파악할 수 있다. 객체내 값있는 속성 비율은 상위레벨(1.0, 0.81)에서는 높은데 하위레벨(0.33, 1.0, 0.5)에서는 그렇지 않다. 객체 DVA수, 객체 OEVA수, 객체 SVA수, 객체 MVA수도 전체적으로 상위레벨과 하위레벨에서 큰 차이가 있는 것으로 나타났다. 실험정보의 일반적인 내용을 저장하는 상위레벨에서는 거의 모든 내용이 충실하게 저장이 되어 있고 구체적이고 특정한 실험 데이터를 저장하는 하위레벨에서는 일부 내용만이 저장되어 있다는 의미이다. 그러나 Table 6에서는 레벨별 객체들이 하나씩만 있기 때문에 동일 레벨에 있는 다른 모든 객체들(예를 들면, Fig. 6에서 experiment 1부터 experiment 8까지의 객체)을 고려하면 정확한 평가가 가능할 것이다.
Table 6
Evaluation criteria of attributes of objects for experiment of seismic response of structural walls
데이터 저장소의 상위레벨에서의 실제 실험정보가 충실하고 하위레벨에서는 그렇지 못하는 것을 실험정보의 저장이 제대로 이루어지지 않았다는 것으로 볼 수도 있지만 또 다른 관점에서 본다면 여러 가지 종류의 실험정보를 저장하기 위하여 필요한 모든 구성을 갖추어 놓고 실험 종류별로 필요한 부분에만 저장하도록 했다는 의미로도 해석할 수 있다. 데이터 저장소를 제한된 범위의 실험종류에 대하여 거의 모든 정보를 빠짐없이 저장하도록 구성할 수도 있고 또는 다양한 종류의 실험에 대하여 해당 실험정보만을 선택하여 저장하도록 구성할 수도 있다.
데이터 저장소를 어떻게 구성하여 운영할 것인가는 데이터 저장소의 성격과 규모 그리고 데이터 저장소를 사용하는 사용자들의 범위에 따라서 결정하여야 한다. 일반적으로 소규모 데이터 저장소의 경우는 특정한 범위의 실험을 대상으로 하므로 객체내 값있는 속성비율을 높게 유지하고 하위레벨에 가더라도 비율이 감소하지 않으며 레벨수는 많지 않도록 하는 것이 필요하다. NEEShub Project Warehouse와 같은 대규모 저장소는 큰 실험 프로젝트를 저장할 수 있도록 되어 있고 이 경우에 객체 수가 많으므로 객체내 값있는 속성비율을 전체 레벨에 걸쳐서 높게 유지할 수는 없지만 일정 수준을 유지하도록 속성을 구성할 필요가 있다.
5. 결 론
본 연구는 데이터 저장소의 자체적인 구성 특성과 데이터 저장소의 활용에 대한 평가를 위한 것으로서 데이터 저장소의 자체적인 구성은 클래스로 나타낼 수 있고 실제의 실험정보는 객체로 나타낼 수 있으므로 클래스와 객체가 포함하는 속성구성에 대한 평가요소를 제안하였고 이를 실제로 사용하는 데이터 저장소에 대하여 적용하여 실용성을 검토하였다.
데이터 저장소의 클래스에 대한 평가요소에 대하여는 클래스내 속성수가 크면 클래스 구성의 복잡한 것으로 예상할 수 있다. 클래스 DVA수와 클래스 OEVA수에 대하여는 클래스 OEVA 비율이 높을수록 실험정보를 하위레벨에 많이 분포하도록 구성하였다는 의미이고 클래스 SVA수와 클래스 MVA수에 대하여는 클래스 MVA 비율이 높을수록 단일 값보다는 복수의 값을 갖는 정보가 많다는 것을 의미한다. 레벨별로 클래스 속성구성 평가요소를 비교하면 하위레벨로 갈수록 한 가지 종류의 정리되고 분량이 명확한 실험정보를 저장하도록 데이터 저장소가 구성되는 것으로 파악되었다.
데이터 저장소의 객체에 대한 평가요소에 대하여는 객체내 값있는 속성수와 그 비율이 높을수록 실제 실험정보가 정해진 구성 내에 많이 저장되어 있다는 의미이다. 객체 DVA수, 객체 OEVA수, 객체 SVA수, 객체 MVA수를 클래스의 경우와 비교하여 차이가 많이 날수록 해당 종류의 실험정보 저장 정도가 낮다는 것을 의미한다. 레벨별로 객체 속성구성 평가요소를 비교하면 상위레벨부터 하위레벨에 이르기까지 실제 실험정보의 분포를 이해할 수 있는데 객체내 값있는 속성비율이 상위레벨에서 높고 하위레벨에서 낮으면 일반적인 내용을 저장하는 상위레벨에서는 실험정보가 충실하게 저장이 되어 있고 구체적인 실험정보를 저장하는 하위레벨에서는 일부 실험정보만 저장되어 있다는 의미로서 이는 데이터 저장소의 구성을 어떻게 만드는 가와 밀접하게 관련이 되어 있다.
본 연구에서 제안한 데이터 저장소의 클래스와 객체의 속성구성을 위한 평가요소는 데이터 저장소의 단위 정보의 구성과 저장 상태를 수치적으로 나타내어 비교 분석할 수 있다는 점에 큰 의의가 있다고 할 수 있다. 여러 개의 레벨에 걸쳐 있는 클래스와 객체에 대한 평가요소를 비교함으로서 데이터 저장소의 실험정보 구성과 그 실제 분포를 수치적으로 기술하여 분석하는 것도 가능하였다. 본 논문에서 제안한 클래스와 객체에 대한 평가요소를 실제의 데이터 저장소의 개발과정에 이용하고 개발된 데이터 저장소의 평가에 이용한다면 구조실험 정보를 위한 데이터 저장소의 효율을 높이는데 기여할 것으로 기대된다.
