

1. 서 론
1.1 연구의 배경 및 목적
1.2 연구의 방법 및 범위
2. 선행연구 분석
2.1 지식그래프 기술 동향 분석
2.2 국내외 선행연구 동향 분석
3. GraphRAG 기반 BIM 데이터 자동 질의 알고리즘 개발
3.1 자동 질의 생성 알고리즘 개발 프레임워크
3.2 BIM 데이터 전처리 및 LPG 지식그래프 자동 구축
3.3 Few-shot Learning 기반 지식그래프 질의-답변 학습
4. 라멘교 대상 BIM 데이터 기반 질의 자동 생성 검증
4.1 Graph-ACQ 내 질의 시스템 구현 및 질의 생성 결과
4.2 자연어 질의 변환 정확도 및 성능 평가
4.3 LLM 모델별 자동 질의 생성 성능 비교
5. 결 론
1. 서 론
1.1 연구의 배경 및 목적
최근 Building Information Modeling(BIM)은 단순한 3D 모델링을 넘어 설계・시공・유지관리 전 과정에서 표준화된 고품질 데이터의 확보와 체계적 관리가 핵심 요구로 부각(Wang et al., 2024)되고 있다. 이에 따라 객체 속성과 객체 간 관계를 포함하는 복합 데이터 구조에 대한 접근과 활용의 중요성이 점차 강화되고 있다.
이에 인공지능 기술 확산과 함께 온톨로지 및 지식그래프 기반의 데이터 관리・추론 방식이 다양한 산업 분야로 확대되고 있다(Peng et al., 2024). 최근 지식그래프를 Large Language Model(LLM)과 결합하여 검색 및 추론 성능을 강화하는 Graph Retrieval Augmented Generation(GraphRAG)과 같은 접근이 주목받고 있다(Larson and Truitt, 2024). BIM 데이터 역시 부재 속성뿐 아니라 공간적, 구조적 관계로 정의할 수 있는 온톨로지의 지식그래프 기반 표현이 효과적인 대안이 될 수 있다.
현재 지식그래프 기반 데이터의 실무적 활용을 위해서는 Simple Protocol and RDF(Resource Description Framework) Query Language(SPARQL) 또는 Cypher와 같은 그래프 질의어 작성이 필수적이다. 따라서 사용자는 질의 맥락과 그래프 구조를 충분히 이해한 뒤 각 질의 문법에 맞춰 쿼리를 직접 작성해야 한다(Peng et al., 2024). 그러나 질의가 복잡할수록 쿼리 생성에 반복적인 디버깅과 수작업 수정이 요구된다. 이러한 문제는 교량 BIM 데이터 활용에서 더욱 두드러지는데, 교량 BIM 데이터는 교대-교각-상부구조 간의 공간적・구조적 관계와 재료・물량 정보가 복합적으로 연결된 구조를 갖기 때문이다. 실무에서는 “특정 교각과 연결된 상부구조 부재”나 “특정 재료의 수량”과 같은 관계 기반 질의가 빈번하다. 따라서, 이를 그래프 질의어로 작성하기 위해서는 높은 수준의 데이터 구조 이해와 질의 작성 역량이 요구된다.
이에 본 연구는 사용자가 질의어 문법을 직접 작성하지 않아도, 자연어 질문을 기반으로 BIM 데이터 검색 및 추론을 위한 그래프 질의를 손쉽게 자동 생성할 수 있는 GraphRAG 기반 질의 자동 생성 모델을 개발하는 것이 목적이다.
1.2 연구의 방법 및 범위
본 연구의 주요 범위는 시설측면에서 우선 기술적 가능성 확인을 위해 라멘교(Rigid-Frame Bridge, 국토교통부 「전국 교량 현황자료(2025)」에 수록된 국내 교량 40,006개 중 24%로 가장 높은 비율을 차지)를 대상으로 한다. 쿼리 언어는 SPARQL이 아닌 Labeled Property Graph(LPG)기반의 쿼리 자동 생성을 범위로 한다.
온톨로지(RDF) 기반 지식그래프는 의미론적 정합성과 표준화에 강점이 있으나, 엄격한 구조와 SPARQL 전문성 요구로 대규모 그래프 및 자연어 기반 질의 자동 생성에 한계가 있다. 반면 LPG 기반 지식그래프는 노드와 관계에 속성을 직접 부여하는 단순한 구조와 직관적인 Cypher 질의를 통해 안정적인 성능을 제공하며, 경량화된 데이터 구조로 대규모 처리에 유리하다(Francis et al., 2018). 이에 따라 교량과 같은 복잡한 인프라 BIM 데이터를 위한 질의 자동 생성 프레임워크에는 LPG 기반 지식그래프가 적합한 모델로 판단된다.
연구 수행 방법론(Fig. 1)은 총 4단계로 구성된다.
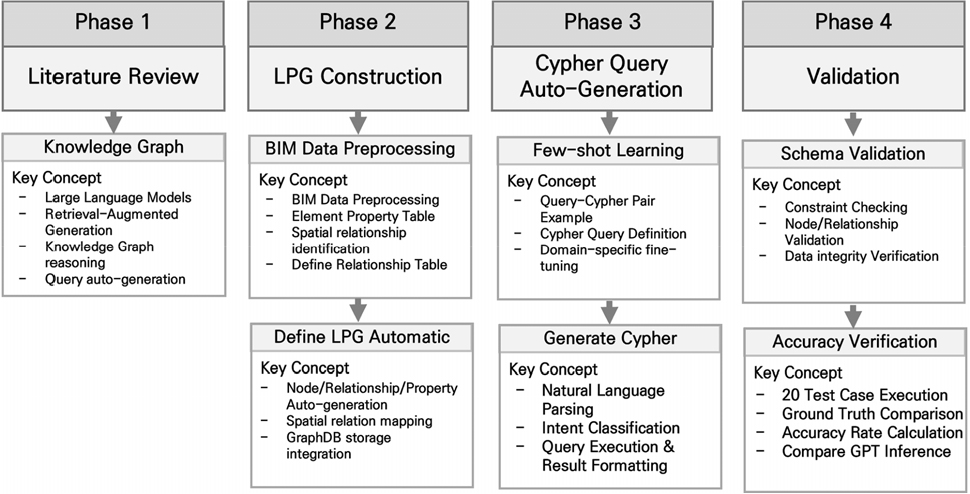
1단계에서는 자연어 기반 그래프 질의 자동 생성에 관한 국내외 선행연구를 분석하였다. 이를 통해 GraphRAG 기술의 건설 분야 적용 사례를 검토하여 기존 연구의 한계점과 본 연구의 차별성을 도출하였다.
2단계에서는 BIM 데이터로부터 LPG 기반 지식그래프를 자동 구축하는 알고리즘을 개발하였다. BIM 모델은 전처리 과정을 통해 부재의 속성 데이터와 객체 간 관계를 정의한 뒤 CSV 형식으로 추출되며, 각 부재는 노드로 변환되고 속성 정보는 노드 속성으로 저장된다. 또한 부재 유형 간 구조적 연결 규칙을 정의하여 동일 위치에 배치된 부재들 간의 관계를 자동 생성함으로써, 부재 속성과 구조적 관계가 함께 표현되는 LPG 스키마를 구성하였다. LPG는 노드와 관계에 속성을 직접 부여할 수 있어 교량 BIM 데이터의 특성을 효과적으로 표현할 수 있다. 이를 통해 교량 BIM 데이터를 그래프 구조로 자동 변환하는 CSV-to-LPG 파이프라인을 구현하였다.
3단계에서는 자연어 질문을 Cypher 질의로 변환하는 GraphRAG 기반 자동 질의 생성 모듈을 개발하였다. 이는 Few-shot-Learning 기법을 적용하여 자연어 질문과 대응하는 Cypher 질의문을 제공한다. Few-shot Learning은 대량의 학습 데이터 없이 소량의 예시만으로 모델이 새로운 작업을 수행할 수 있도록 하는 기법이다(Brown et al., 2020). 이러한 기법은 LLM을 활용하여 스키마 정보와 소량의 예시 쌍만으로 자연어 질문을 Cypher 쿼리로 변환한다.
4단계에서는 개발된 프레임워크의 검증을 수행하였다. 스키마 제약조건을 적용하여 필수 속성 존재 여부, 허용된 노드 라벨과 관계 유형, 중복 ID 및 단일 노드 여부를 확인함으로써 생성된 지식그래프의 구조적 유효성을 검증하였다. 또한 사전 정의된 정답 질의-응답 세트와 프레임워크의 결과를 비교하여 질의 합성 정확도를 평가하였다.
2. 선행연구 분석
2.1 지식그래프 기술 동향 분석
자연어 기반 그래프 질의 자동 생성 기술은 사용자가 자연어로 그래프 데이터에 접근하여 분석과 의사결정을 지원하는 기술로, 규칙 기반, 기계학습 기반 및 RAG 기반의 세 가지 접근방식으로 구분된다(Lan et al., 2022). 첫째, 규칙 기반(Rule-based) 방식은 사전 정의된 템플릿과 패턴 매칭을 통해 자연어를 그래프 질의로 변환한다(Unger et al., 2012). 이 방식은 구현이 비교적 단순하고 예측 가능한 결과를 제공하나, 다양한 문장 패턴에 대응하기 어렵다는 한계가 있다. 둘째, 기계학습 기반(Machine Learning-based) 방식은 의미 분석 모델을 활용하여 자연어와 그래프 질의 간의 매핑을 학습한다(Yih et al., 2015). 이 방식은 규칙 기반보다 유연하나, 대량의 학습 데이터가 필요하여 도메인 특화 적용에 한계가 있다. 셋째, RAG(Retrieval-Augmented Generation) 기반 방식은 LLM과 검색 기술을 결합하여 외부 지식을 참조한 응답을 생성한다(Du et al., 2024). RAG 기반 접근은 VectorRAG와 GraphRAG로 구분된다. VectorRAG는 문서를 청크(Chunk) 단위로 분할하여 벡터 임베딩으로 변환한 후, 유사도 검색을 통해 관련 정보를 검색한다. 건설 분야에서는 설계 문서 검색, 건축 법규 해석 등에 적용되어 효과성이 검증되었다(Du et al., 2024; Mokhov, 2024). 그러나 VectorRAG는 청킹 과정에서 문맥 정보가 손실되고, 개체 간 관계를 명시적으로 표현하지 못하여 다중 홉(Multi-hop) 관계 추론(다중 홉(Multi-hop): 단일 정보 소스가 아닌 여러 문서 또는 지식 노드를 순차적으로 탐색하여 최종 답변을 도출하는 추론 방식(Yang et al., 2018))이 요구되는 질의에는 한계가 있다(Edge et al., 2024).
이러한 한계를 극복하기 위해 GraphRAG 기술이 주목받고 있다. GraphRAG는 지식그래프의 노드와 엣지 구조를 활용하여 개체 간 관계를 명시적으로 표현하고, 경로 탐색을 통해 복잡한 관계 추론이 가능하다(Peng et al., 2024). BIM 데이터는 부재 간 공간적・구조적 연결 관계가 핵심 정보이므로, 단순 유사도 검색보다 그래프 기반 관계 추론이 적합하다. 그러나 건설 분야에서 GraphRAG 적용은 건축물 하자관리(Jeon and Lee, 2025), 유지보수(Shi et al., 2025) 등에 한정되어 있으며, 교량 도메인에 특화된 LPG 지식그래프와 Few-shot Learning 기반 질의 자동 생성에 관한 연구는 부족한 것으로 나타났다.
2.2 국내외 선행연구 동향 분석
본 절에서는 본 연구와 관련된 선행 연구 문헌을 Table 1과 같이 3가지 카테고리로 나누어 분석하였다.
Table 1.
Analysis of previous research
| No | Reference | Research Contents | Classification |
| 1 | Guo et al., 2020 | Automatic SPARQL generate based on RDF |
BIM Graph Query Auto-Generation |
| 2 | Chen et al., 2021 | QAWizard, entity & RDF identification | |
| 3 | Yin et al., 2023 | GSP4BIM, GNN-based multi-hop | |
| 4 | Kang and Park, 2024 | BIM knowledge expert Agent (RAG) | LLM/GraphRAG in Construction |
| 5 | Jeon and Lee, 2025 | GraphRAG based defect management | |
| 6 | Shi et al., 2025 | Thought generation for maintenance | |
| 7 | Xiong et al., 2025 | DR-RAG, aviation design with DT | |
| 8 | Yu et al., 2025 | GPT-4 evaluation on BIM expertise exam | |
| 9 | Beetz et al., 2009 | IFC-OWL mapping | BIM/OWL Knowledge Graph |
| 10 | Pauwels and Terkaj, 2016 | ifcOWL conversion rules establishment |
BIM 그래프 질의 자동 생성 관련 연구에서 Guo 등(2020)은 RDF 데이터베이스의 경로 질의 함수와 질의 키워드를 포함하는 규칙 함수를 이용하여 SPARQL 자동생성 방법을 제안하였다. Chen 등(2021)은 BIM 모델에 대해 RDF - SPARQL 기계학습 기반 자연어 질의 응답 시스템인 QAWizard 개발하여 엔티티 식별 86.74%, RDF 식별 98.73%의 정확도를 달성하였다. Yin 등(2023)은 GNN 기반 의미 분석 방법인 GSP4BIM을 제안하여 자연어 질의와 IFC 온톨로지 구조를 이질적 그래프로 융합함으로써 명칭 모호성과 다중 홉 관계 추론 문제를 해결하고자 하였다. 그러나 이러한 연구들은 규칙 기반 또는 지도학습 기반 알고리즘에 의존하여 대량의 학습 데이터가 필요하고, 새로운 도메인 적용 시 재학습이 요구된다는 한계가 있다.
LLM 및 GraphRAG 기반 건설 응용 연구에서 Kang과 Park(2024)은 제한된 GPU 자원 내에서 효과적인 검색 방법에 초점을 맞춘 RAG 기반 BIM 지식 전문가 에이전트를 제안하였다. Jeon과 Lee(2025)는 주거 하자관리를 위한 하이브리드 RAG와 GraphRAG 접근법의 비교 분석을 수행하여 GraphRAG가 81.6%의 정답률을 달성함을 입증하였다. Shi 등(2025)은 지식그래프 검색과 Chain-of-Thought 프롬프트를 결합한 유지관리 지침 문서의 단계적 생성 방법을 제안하였으며, Xiong 등(2025)은 항공 설계 분야에서 디지털 트윈과 RAG를 통합한 DR-RAG 프레임워크를 개발하였다. Yu 등(2025)은 한국 BIM 전문가 시험에서 GPT-4가 85%, RAG 적용 시 88.6%의 정확도를 달성함을 보고하였다. 그러나 이러한 연구들은 주로 건축물의 하자관리, 유지보수, 교육 분야에 집중되어 있으며, 교량 도메인에 특화된 지식그래프 질의 자동 생성에 관한 연구는 부재하였다.
BIM 지식그래프 구축 연구는 2000년대 후반부터 시작되어 BIM 데이터의 의미론적 활용 기반을 마련하였다. Beetz 등(2009)은 IFC 엔티티를 OWL 클래스로 매핑하는 방법론을 제안하였으며, Pauwels과 Terkaj(2016)는 ifcOWL 변환 규칙을 정립하여 IFC 스키마를 RDF 형식으로 표현할 수 있는 체계를 확립하였다. 그러나 기존 연구들은 그래프 데이터 구조 설계와 질의 처리를 주로 직접 구현하거나, 규칙 기반・기계학습 기반 접근을 통해 정적인 질의 자동화 수준에 머무르고 있다. 이러한 방식은 사전에 정의된 패턴 또는 학습된 매핑에 의존하기 때문에, 도메인 지식의 변화, 복합적 관계 탐색, 문맥 기반 추론과 같은 동적인 질의 생성에는 한계를 보였다.
특히 교량 BIM과 같이 구조적 관계가 지속적으로 반영되어야 하는 분야에서는 패턴 기반 질의나 문서 검색 중심 접근만으로는 충분하지 않다. 또한 기존 GraphRAG 기반 건설 응용 연구 역시 특정 시나리오에 국한되어 교량 BIM의 부재 속성과 구조적 관계를 대상으로 한 질의 자동 생성 연구는 부족하다.
이에 본 연구는 교량 BIM 데이터를 LPG 기반 지식그래프로 구조화하고, 그래프 스키마 정보를 검색 증강 컨텍스트로 활용하는 GraphRAG 기반 질의 자동 생성 프레임워크를 제안한다. 이를 통해 도메인 특화 학습 데이터 없이도 자연어 입력으로부터 교량 부재의 속성 및 구조적 관계 질의를 자동 생성 가능하다.
3. GraphRAG 기반 BIM 데이터 자동 질의 알고리즘 개발
3.1 자동 질의 생성 알고리즘 개발 프레임워크
GraphRAG 기반 자동 질의 생성 프레임워크는 크게 세 단계(Fig. 2)로 나누어 구현하였다.
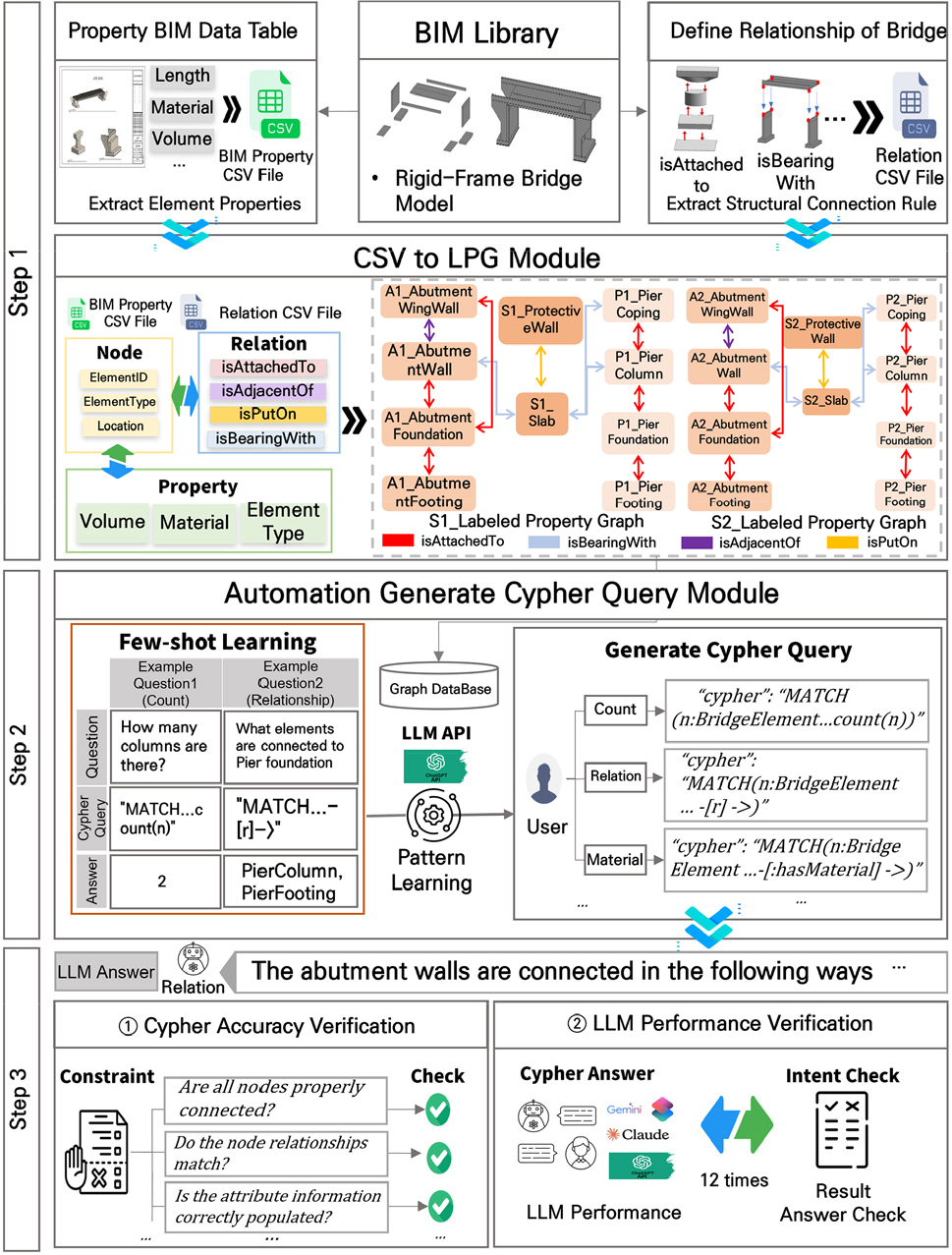
1단계에서는 BIM 데이터 전처리 및 LPG 지식그래프 자동 구축을 수행하였다. 이는 Autodesk Revit 내 생성된 모델에서 교량 부재의 요소 ID, 유형, 위치, 재료, 치수 등의 속성 정보를 추출하고 이를 csv 기반 테이블 구조로 정규화하였다. 또한, 부재 간 구조적 연결 관계를 정의하는 관계 정의 테이블은 별도로 구성하였다. 이후 전처리된 데이터를 기반으로 교량 부재를 노드로 변환하고, 부재의 재료 및 위치 정보를 별도의 속성 노드로 분리하여 연결하였다. 또한 관계 정의 테이블을 참조하여 부재 간 연결관계를 자동으로 생성하여 그래프 데이터베이스에 적재하였다. 2단계에서는 Few-shot Learning 기반의 자연어 질의 합성을 구현하였다. 이는 LPG의 스키마 정보를 정의하고, 다양한 질문 유형별 예시와 답을 학습하여 LLM의 추론에 도움을 주도록 설계하였다. 3단계에서는 프레임워크의 유효성 검증을 수행하였다. 검증은 크게 두 가지 측면에서 진행되었다. 우선 스키마 제약 기반 구조적 유효성 검증을 통해 생성된 LPG가 설계된 스키마를 준수하는지 확인하였다. 두 번째로, Cypher 자동 생성에 대한 정확도 검증을 통해 다양한 질문 유형에 대한 쿼리 생성 정확도를 측정하였다. 검증은 정답과의 비교, VectorRAG 기법과의 성능 비교를 통해 측정하였다.
3.2 BIM 데이터 전처리 및 LPG 지식그래프 자동 구축
3.2.1 BIM 데이터 구조 분석 및 전처리 과정
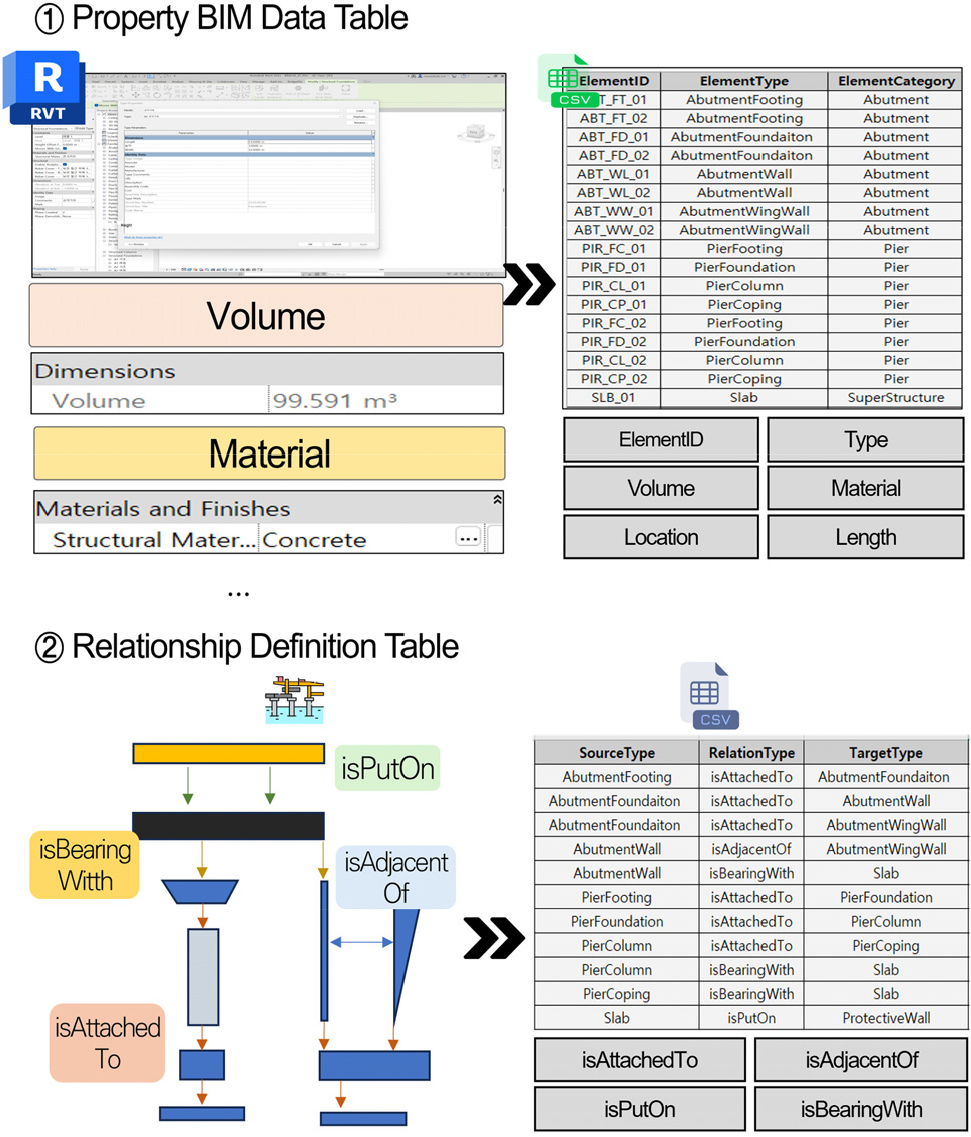
BIM 라이브러리의 각 부재는 식별 정보, 분류 정보, 위치 정보, 물성 정보 등을 포함한다. 교량 BIM 모델링 시, 설계자는 모델에 포함된 부재 속성을 체계적으로 관리하기 위해 해당 정보를 정형화된 데이터 형태로 추출한다. 이는 LPG 그래프 변환에 활용하기 위해 모델 내 부재 정보를 전처리 단계에서 정형화된 데이터 구조로 재구성하였다.
전처리 과정은 교량 BIM 모델에 포함된 부재 속성을 부재 단위의 정형 테이블 구조로 재구성하여, 각 부재의 식별자, 유형, 위치. 재료, 물량 정보가 고정된 컬럼 형식으로 표현되도록 정규화하였다. 이를 위해 라멘교 모델을 대상으로 Table 2와 같은 데이터 구조를 설계하였다.
Table 2.
Property BIM data table
예를 들어 ‘ABT_FD_01’은 Abutment Foundation의 첫 번째 요소를 의미하며 ElementID, Category, Location 등 주요 속성으로 구분된다. 추가적으로, 교량 BIM 데이터는 객체와 객체간의 관계를 명확하게 정의하기 위해 Table 3과 같은 관계 정의 테이블을 구성하였다.
Table 3.
Relationship definition table
이 테이블은 요소 유형 간의 물리적 연결 및 인접 관계를 사전에 정의하여, LPG 구축 시 자동으로 관계를 생성하는 데 활용된다. 관계 유형은 isAttachedTo(수직 결합), isAdjacentOf(인접), isPutOn(힌지 결합), isBearingWith(탄성 결합)으로 구분하였다. BIM 데이터 속성 테이블과 관계 테이블 과정은 Fig. 3과 같다.
3.2.2 LPG 자동 변환 알고리즘
LPG는 노드와 관계에 라벨과 속성을 부여할 수 있는 그래프 모델로 직관적인 스키마 설계와 효율적인 질의 처리가 가능하다. 본 연구에서 구현한 알고리즘은 전처리된 BIM 속성 테이블과 관계 정의 테이블을 입력으로 받아, 교량 부재의 속성과 구조적 관계를 동시에 표현하는 LPG 지식그래프를 자동으로 구축한다. LPG 스키마와 전체 변환 절차는 Fig. 4와 같다.
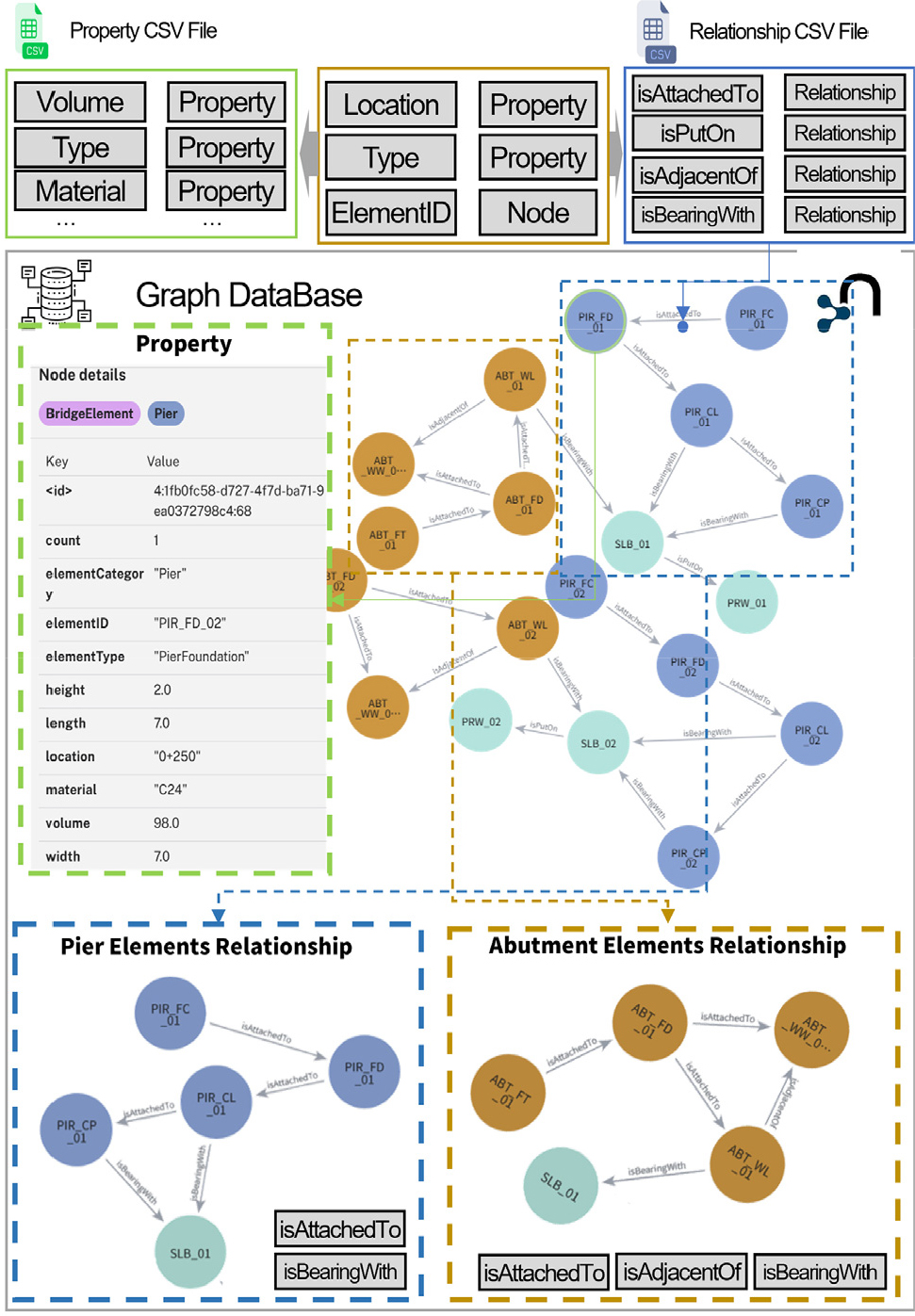
LPG 자동 변환 알고리즘은 노드 생성 단계와 관계 생성 단계의 두 단계로 구성된다.
첫 번째 단계에서는 각 레코드를 기반으로 교량 부재를 BridgeElement 노드로 생성한다. 이때 ElementID, Type, Category, Location, Material 정보는 노드의 속성으로 저장된다. 그리고 부재가 교대, 교각, 상부구조 중 어디에 해당하는지를 구분하기 위해 Abutment, Pier, Superstructure와 같은 구조 구분 라벨을 함께 부여한다. 이를 통해 교량 부재의 속성이 그래프 구조 내에서 명확하게 표현된다. 두 번째 단계에서는 관계 정의 테이블(Table 3)을 참조하여 부재 간 구조적 관계를 자동으로 생성한다. 관계 생성은 부재 유형(Type)과 ElementID에 포함된 일련 번호를 기준으로 수행된다. 즉, 관계 정의 테이블의 SourceType과 TargetType이 BIM 속성 테이블의 Type 값과 일치하는 부재 쌍을 1차적으로 도출한 후, ElementID에 포함된 번호가 동일한 경우에만 실제 결합 대상으로 확정한다. 예를 들어 PierColumn과 PierFoundation 유형이면서 ElementID 번호가 동일한 경우, 두 부재는 자동으로 isAttachedTo 관계로 연결된다.
이와 같은 규칙 기반 매핑 방식에서 Type 정보는 관계의 의미론적 조건을 정의하고, ElementID 번호는 결합 단위를 식별하는 기준으로 작용한다. 이를 통해 불필요한 관계 생성을 방지하면서도, 실제 교량 구조의 조립 논리를 반영하여 일관된 LPG 지식그래프를 자동으로 구축할 수 있다. 최종적으로 생성된 LPG 그래프는 이후 자연어 기반 질의 자동 생성 모듈의 입력 데이터로 활용된다.
3.3 Few-shot Learning 기반 지식그래프 질의-답변 학습
본 절에서는 구축된 LPG 지식그래프를 대상으로, 사용자의 자연어 질문을 Cypher 질의로 자동 변환하는 GraphRAG 기반 질의 자동 생성 모듈의 구축 과정을 설명한다. 제안 모듈은 교량 BIM 도메인에 특화된 그래프 스키마 정보를 검색 증강 정보로 활용하고, Few-shot Learning 기반 프롬프트 설계를 통해 질의 자동 생성을 수행한다. 이는 사용자가 Cypher 문법을 직접 작성하지 않아도 그래프 데이터를 조회할 수 있도록 Text-to-Cypher 모듈을 구축하였다.
일반적인 RAG는 문서를 잘게 나눈 뒤 관련 문장을 검색하여 LLM에 제공한다. 그러나 그래프 질의 생성의 경우, 문장 단위 의미 검색보다는 그래프에서 사용 가능한 라벨, 관계, 속성의 범위를 명확히 제시하는 것이 더 중요하다. 따라서 현재 질의 자동 생성 모듈은 문서를 나누지 않고, 그래프 질의에 필요한 정보를 스키마 단위로 정리하여 LLM에 제공하였다. LLM은 이 스키마 범위 안에서만 Cypher를 생성하도록 제한된다.
스키마 컨텍스트는 Table 4와 같이 노드 라벨, 부재 유형, 관계 유형, 속성 목록으로 구성된다. 이 정보는 매번 질의 생성 시 동일하게 프롬프트에 포함된다. 질의 생성 방식으로는 파인튜닝을 수행하지 않고 Few-shot Learning 기반 프롬프트 튜닝을 적용하였다. 이는 예시를 몇 개 제공해 카테고리에 따라 패턴을 학습시키는 방법으로 적용하였다. 이러한 과정은 자주 발생하는 질문 유형을 중심으로 예시를 구성하고, LLM이 예시 패턴을 따라 Cypher를 작성하도록 유도한다. 이러한 자동 질의 생성 절차와 전체 흐름은 Fig. 5에서 구성하였다. 본 연구에서는 교량 BIM 데이터에 대한 다양한 질의 유형을 분석하여 Table 5와 같이 6가지 카테고리로 분류하고, 카테고리별로 대표적인 예시 쌍을 설계하였다.
Table 4.
Graph schema context for query generation
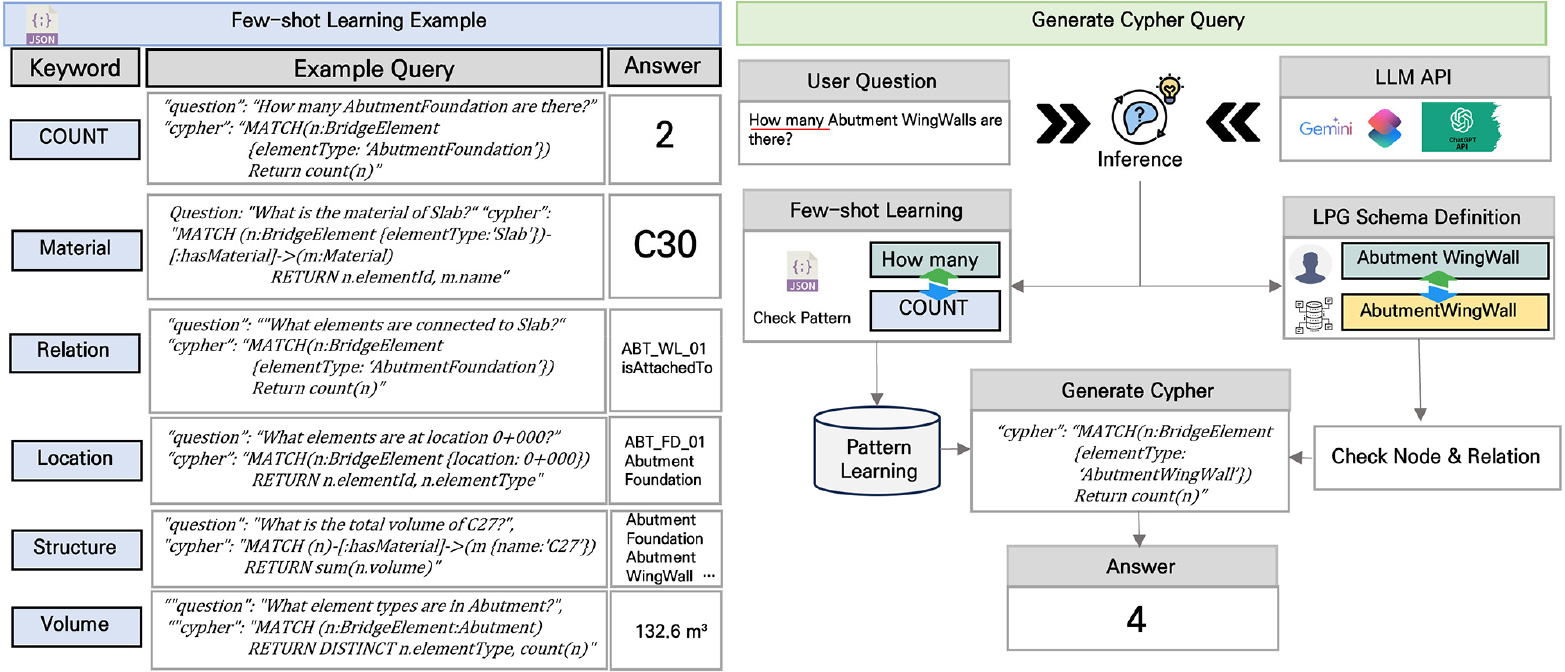
Table 5.
Few-shot Learning example categories
개수 질문은 특정 부재의 수량을 집계하는 질의로, count() 함수를 활용한 Cypher 패턴으로 구성된다. 재료 질문은 Material 노드를 탐색하며, 관계 질문은 부재 간 연결 관계를 탐색하기 위해 관계 타입을 조회하는 type(Relation) 함수와 다양한 관계를 동시에 탐색하는 패턴을 포함한다. 위치 질문과 구조 질문은 각각 location 속성 기반 필터링과 다중 라벨을 활용한 카테고리별 조회 패턴으로 구성된다. 물량 질문은 sum(), avg() 등 집계 함수를 활용하여 체적이나 면적의 합계나 평균을 산출한다. 또한 각 카테고리별로 존댓말, 약어 등 다양한 질문 표현을 포함하여 LLM이 자연어의 다양한 표현 방식을 처리할 수 있도록 하였다.
이러한 방식을 통해 사용자의 질문을 LLM에 전달하고 Few-shot Learning 내에 학습된 답변을 기반으로 Cypher 쿼리를 생성한다. 본 연구에서는 Few-shot Learning 기반 Cypher 질의 생성을 위해 OpenAI의 GPT-4o-mini 모델을 활용하였다. GPT-4o-mini는 별도의 파인튜닝 없이도 제한된 예시 질의와 스키마 제약 정보를 바탕으로 그래프 질의 구조를 추론할 수 있어, 스키마 이탈이나 문법 오류를 최소화하는 데 적합한 특성을 가진다(OpenAI, 2024). 또한 질의 자동 생성이 반복적으로 수행되는 시스템 특성을 고려할 때, 응답 속도와 API 호출 비용 측면에서 효율적인 운영이 가능하다는 점을 종합적으로 고려하여 질의 자동 생성 모델로 선정하였다. 다른 LLM 모델과의 정량적인 성능 비교 및 비용 분석은 4.3장에서 상세히 다룬다. 생성된 Cypher 쿼리를 Neo4j 그래프 데이터베이스에서 실행하고 결과를 반환한다. 이러한 Few-shot Learning 기반 접근법은 새로운 스키마나 도메인에 대해 별도의 모델 학습 없이 같은 키워드의 스키마를 추론하여 결과를 얻을 수 있다.
4. 라멘교 대상 BIM 데이터 기반 질의 자동 생성 검증
4.1 Graph-ACQ 내 질의 시스템 구현 및 질의 생성 결과
제안된 GraphRAG 기반 자동 질의 프레임워크의 적용 가능성을 검증하기 위해, 라멘교 BIM 데이터를 대상으로 웹 기반 프로토타입 시스템인 “Graph-ACQ(GraphRAG-based Automated Cypher Query Generation System)” 을 구현하였다. 본 시스템은 FastAPI와 Gradio 프레임워크를 기반으로 구축되었다. Fig. 6과 같이 csv 업로드, LPG 생성, 그래프 시각화, 자연어 질의 변환의 네 가지 핵심 모듈로 구성된다.
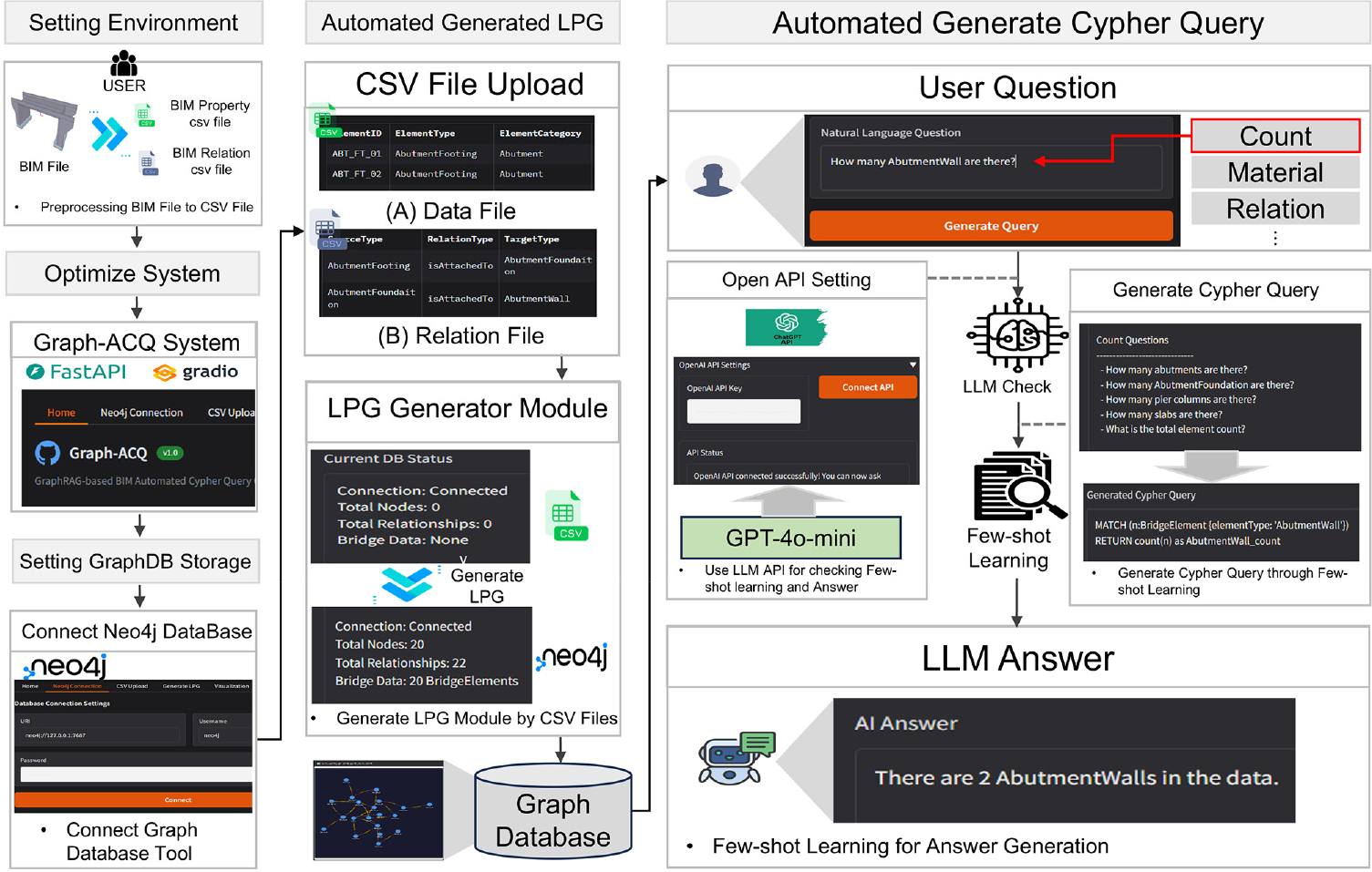
BIM 데이터 입력 모듈은 전처리된 교량 부재 속성 데이터와 관계 정의 데이터를 업로드하고 미리 확인할 수 있는 기능을 제공한다. LPG 생성 모듈은 3.2절에서 제안한 자동 변환 알고리즘을 실행하여, 입력된 BIM 데이터를 Neo4j 그래프 데이터베이스 상의 LPG 지식그래프로 변환한다. 그래프 시각화 모듈은 pyvis 라이브러리를 활용하여 생성된 LPG를 시각적으로 표현함으로써, 부재 간 관계가 의도한 구조로 형성되었는지를 사용자가 직관적으로 확인할 수 있도록 한다. 자연어 질의 모듈은 3.3절에서 제안한 Few-shot Learning 기반 Text-to-Cypher 방식을 적용하여, 사용자의 자연어 입력을 Cypher 질의로 자동 변환한다. 질의 프레임워크의 실제 적용 결과를 확인하기 위해, 라멘교 BIM 모델로부터 전처리된 교량 부재 데이터를 입력으로 사용하여 LPG 자동 생성 및 질의 실험을 수행하였다. LPG 쿼리 생성결과는 Table 6과 같다.
Table 6.
LPG generation results for Rigid-Frame Bridge
| Component | Type | Count |
| Node | BridgeElement | 16 |
| Material | 4 | |
| Location | 5 | |
| Relationship | isAttachedTo | 12 |
| isAdjacentOf | 4 | |
| isPutOn | 2 | |
| isBearingWith | 2 |
라멘교에 대해 생성된 LPG는 총 25개의 노드로 구성되며, 이 중 교량 부재를 나타내는 BridgeElement 노드 16개, 재료 노드 4개, 위치 노드 5개가 포함된다. 또한 구조적 관계인 isAttachedTo, isAdjacentOf, isPutOn, isBearingWith가 자동으로 생성되어 교량 구조의 공간적・구조적 특성이 그래프 형태로 표현되었다.
생성된 LPG를 기반으로 자연어 질의에 대한 Cypher 쿼리 자동 생성을 수행하였다. Fig. 6의 세부 화면은 질의 자동 생성 과정을 나타낸다. 사용자가 “교대기초의 개수는 몇 개인가요?”라는 자연어 질문을 입력하면, 시스템은 LPG 스키마 정보와 Few-shot 예시를 조합하여 프롬프트를 구성한다. 구성된 프롬프트는 LLM(GPT-4o-mini)에 전달되어 Cypher 쿼리를 자동 생성하고, 생성된 쿼리는 Neo4j에서 실행되어 최종 결과를 반환한다. Table 7은 다양한 질문 유형에 대한 Cypher 쿼리 자동 생성 결과를 나타낸다. 개수, 재료, 관계, 위치 등 6가지 카테고리의 질문에 대해 적절한 Cypher 쿼리가 자동 생성되었다.
Table 7.
Automated query generation results by category
4.2 자연어 질의 변환 정확도 및 성능 평가
생성된 LPG와 Graph-ACQ 기반 질의 자동 생성 모듈의 신뢰성을 검증하기 위해, 본 연구에서는 그래프 구조의 타당성 과 자연어 질의 변환 정확도 검증의 두 단계로 평가를 수행하였다.
먼저, 생성된 LPG의 구조적 타당성 검증을 수행하였다. 이를 위해 Neo4j에 적재된 그래프를 직접 조회하여, 교량 부재가 중복 없이 하나의 노드로만 생성되었는지를 확인하였다. 또한 그래프에 포함된 노드 유형과 관계 유형을 전체 목록으로 확인하고, 사전에 정의된 스키마에 포함되지 않은 노드나 관계가 있는지 점검하였다. 이후 각 교량 부재 노드를 대상으로 관계 연결 여부를 확인하였으며, 재료 및 위치와 같이 참조되는 정보가 실제로 그래프 내에 존재하는 노드와 연결되어 있는지 검증하였다. 이러한 검증 과정을 통해 그래프 구조가 설계된 스키마를 충실히 따르는지 판단하였으며, 각 항목에서 문제가 발견되지 않을 경우 Pass로 판정하였다.
다음으로, 질의 변환 정확도는 Neo4j에서 직접 작성한 수작업 Cypher 쿼리를 정답 기준으로 선정하고, 동일 질문에 대해 자동 생성된 Cypher 쿼리문의 실행 결과와 비교하여 판정하였다. 총 6개의 카테고리로 12개 테스트 질문을 구성하였으며 동일한 질의에 대해 실행하여 결과 일치 여부 판정의 절차로 수행하였다. 실행 가능하며 수작업 결과와 동일한 결과를 반환하면 Pass로, 문법 오류, 스키마 이탈, 결과 불일치의 경우에는 Fail로 정의하였다. 생성된 LPG가 설계된 구조를 올바르게 따르는지 검증하기 위해서는 중복 오류, 노드, 관계, 속성 확인, 전체 엔티티 일치 확인의 5가지 검사 항목을 정의하고 평가를 수행하였다. Table 8은 스키마 유효성 검증 결과를 나타낸다.
Table 8.
Results of LPG schema validation
제약조건 검사는 동일한 ID를 가진 노드가 중복 생성되지 않도록 하는 규칙이 설정되어 있는지 확인하였다. 또한 데이터 무결성 검사는 참조하는 데이터가 실제로 존재하는지 확인하며, 추가 노드 검사는 어떤 관계도 없이 고립된 노드가 있는지 확인한다. 마지막으로 정의된 노드 타입과 관계 연결, 필수 속성의 존재 여부를 검증하여 전체 평균 100%의 유효성 점수를 달성하였다.
Few-shot Learning 기반 Cypher 쿼리 생성의 정확도를 검증하기 위해 6개 카테고리에서 총 12개의 테스트 질문을 설계하였다. 검증의 핵심은 Few-shot Learning의 일반화 능력을 평가하는 것으로, 학습 예시에 포함되지 않은 부재 타입과 속성값을 대상으로 테스트를 수행하였다. 각 질문에 대한 결과는 생성된 AI 답변의 정확성과 Neo4j Cypher 쿼리문을 직접 작성하는 것을 비교하며 Graph-ACQ의 정확도와 소요 시간을 측정하였다. Graph-ACQ와 Neo4j Cypher 쿼리와의 비교는 Fig. 7과 같다. Table 9는 카테고리별 테스트 결과를 나타낸다.

Table 9.
Accuracy of Cypher query generation for each category
검증 결과, 12개 테스트 모두에서 수작업 쿼리와 자동 생성 쿼리의 결과가 완전히 일치하여 100%의 정확도를 달성하였다. 개수, 재료, 관계, 위치, 구조, 물량 질문 모두에서 100% 정확도를 보였다. 또한 각 카테고리별 평균 응답 시간을 측정한 결과 모든 질의가 평균 7.1초에 처리됨을 확인하였다.
4.3 LLM 모델별 자동 질의 생성 성능 비교
제안된 Few-shot Learning 기반 질의 생성 방식의 범용성을 추가 검증하기 위해, 6개의 주요 LLM 모델에 대한 성능 비교를 수행하였다. 비교 대상은 OpenAI의 GPT-4o, GPT-4o-mini, Anthropic의 Claude 3.5 Sonnet 및 Claude 3.5 Haiku, Google의 Gemini 1.5 pro 및 Gemini 1.5 Flash이다. 각 모델에 대해 동일한 12개 테스트 질문을 실행하고, 생성된 쿼리의 정확도, 평균 응답 시간, API 호출 비용을 측정하였다. Table 10은 이러한 LLM 모델에 대한 성능 비교 결과를 나타낸다.
Table 10.
Performance comparison across LLM models
검증 결과를 종합하면, 대부분의 상위 LLM 모델은 교량 BIM 도메인에 특화된 Few-shot Learning 기반 질의 생성에서 높은 정확도를 보였다. GPT-4o, GPT-4o-mini, Claude 3.5 Sonnet, Gemini 1.5 Pro는 모든 테스트 질문에 대해 100%의 정확도를 달성하였으며, 이는 제안된 GraphRAG 기반 프롬프트 구조가 모델에 관계없이 안정적인 질의 생성을 유도함을 의미한다. 그러나 실제 시스템 적용 관점에서는 정확도뿐만 아니라 응답 시간과 API 비용을 함께 고려할 필요가 있다. Table 10과 Fig. 8에서 제시된 결과에서 확인할 수 있듯이, GPT-4o-mini는 GPT-4o 및 Claude 3.5 Sonnet과 동일한 100%의 정확도를 유지하면서도 평균 응답 시간이 7.1초로 더 짧았으며, 입력 및 출력 토큰 단가가 $0.00015, $0.0006 수준으로 낮은 비용 구조를 보였다. 반면, Gemini 1.5 Flash와 Claude 3.5 Haiku는 응답 속도, 비용 측면에서는 우수하였으나, 일부 질의에서 정확도 저하가 발생하였다.
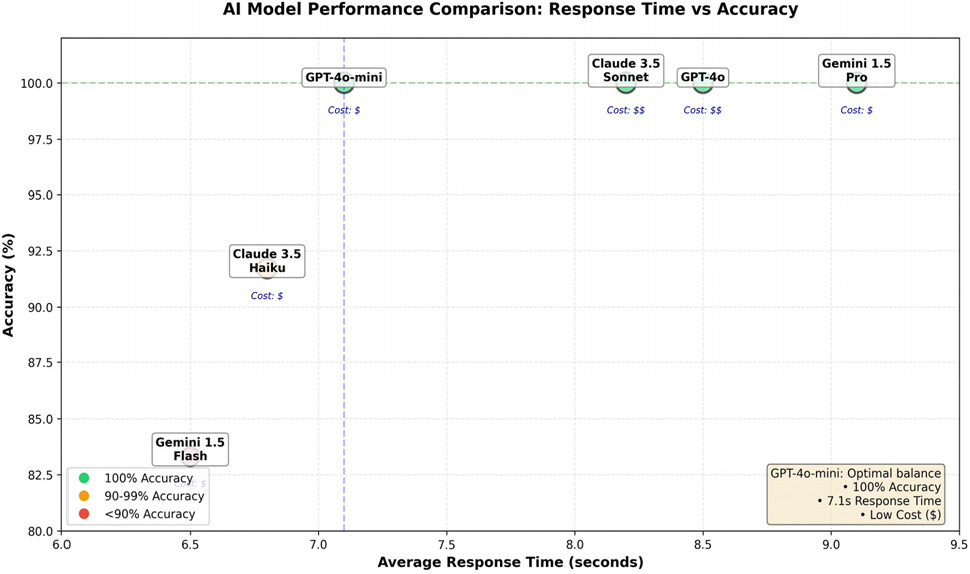
이러한 결과는 최고 성능 모델보다 질의 생성 정확도와 평균 응답 시간, API 호출 비용을 종합적으로 고려하는 것이 중요함을 시사한다. 본 연구에서는 모델 선택 기준을 (1) 모든 테스트 질의에 대한 정확도, (2) 평균 응답 시간의 안정성, (3) API 비용 효율성으로 정의하였다. 이 기준에 따라 비교한 결과, GPT-4o-mini가 높은 정확도를 유지하면서 평균 응답 시간이 짧고, 토큰 단가가 현저히 낮아 가장 합리적인 선택지로 판단하였다.
본 연구의 성능 평가는 라멘교 1개 사례와 6개 질의 유형에 대해 총 12개의 테스트 질문을 대상으로 수행되었다. 이는 4가지의 관계 설정으로 진행되어 복잡한 구조물에 반영하기 위해서는 추가적인 역학 관계 설정과 위계구조 설정에 대한 연구가 필요하다.
5. 결 론
본 연구에서는 BIM 데이터와 지식그래프의 실무적 활용성을 향상시키기 위해 GraphRAG 기반 질의 자동 생성 프레임워크를 제안하였다. 현재 BIM 모델의 공간적 요소와 데이터 관리의 중요성이 강조되고 AI 산업이 발전함에 따라, 지식그래프의 활용도가 점차적으로 늘어나고 있다. 하지만 BIM 데이터는 객체와 속성정보만 포함되어 있을 뿐 공간적 관계가 정의되어 있지 않으며 이를 활용하기 위해서는 여전히 쿼리문을 문법에 맞춰서 작성해야 하는 한계가 있다. 이를 위해 BIM 데이터로부터 부재의 속성과 구조적 관계를 함께 표현할 수 있는 LPG 기반 지식그래프를 정의하고, GraphRAG 기반 자동 질의 생성 모듈을 구현하였다.
연구 과정에서는 먼저 자연어 기반 그래프 질의 자동 생성에 관한 국내외 선행연구를 분석하여, 규칙 기반・기계학습 기반・RAG 기반 접근법의 특성을 비교하고 GraphRAG의 적용 필요성을 도출하였다. 이후 BIM 데이터의 부재 속성 테이블과 관계 정의 테이블을 분리하고, 부재 유형과 Element ID 번호 기반 규칙을 통해 지식그래프 구축 과정의 일관성과 재현성을 확보하였다. 이를 통해 교량 BIM 데이터의 속성 정보와 구조적 관계가 동시에 표현되는 LPG 지식 그래프를 자동으로 생성할 수 있음을 확인하였다. 또한 자연어 질의 자동 생성을 위해 문서 청킹 기반 검색 방식이 아닌 그래프 스키마 중심의 컨텍스트 제공 전략을 적용하였다. 노드, 관계, 속성을 스키마 단위로 정리하여 LLM에 제공하고, Few-shot Learning 내 프롬프트 튜닝을 통해 Cypher 질의를 생성한다.
프레임워크의 검증을 위해 라멘교 BIM 데이터를 대상으로 수행한 실험 결과, 제안된 Graph-ACQ 시스템은 개수, 재료, 관계, 위치, 구조, 물량에 대해 다양한 질의 유형에 대해 100%의 질의 변환 정확도를 달성하였으며, 모든 질의가 평균 7.1초에 처리되어 실시간 질의 응답 환경에서도 적용 가능함을 확인하였다. 또한 다수의 LLM 모델을 대상으로 한 비교 실험 결과, GPT-4o-mini는 최고 성능 모델과 동일한 질의 변환 정확도를 유지하면서도 평균 응답 시간이 짧고 API 호출 비용이 현저히 낮은 특성을 보였다. 이러한 결과는 질의 자동 생성 시스템의 실제 적용을 위해서는 단순 정확도뿐만 아니라 처리 속도와 비용 효율성을 함께 고려하는 것이 중요함을 시사한다. 본 연구에서는 (1) 모든 테스트 질의에 대한 정확도, (2) 평균 응답 시간의 안정성, (3) API 비용 효율성을 모델 선택 기준으로 설정하였으며, 이에 따라 GPT-4o-mini를 Graph-ACQ 시스템의 기본 질의 생성 모델로 채택하였다.
제안된 Graph-ACQ 프레임워크는 교량 BIM 데이터에 포함된 부재의 속성 정보와 구조적 관계 정보를 자연어 기반으로 질의할 수 있도록 함으로써, 기존의 그래프 질의어 작성이나 데이터 구조 이해에 의존하던 정보 탐색 과정을 단순화할 수 있다. 이를 통해 설계자 및 엔지니어는 Cypher와 같은 그래프 질의 문법이나 내부 스키마 구조에 대한 전문 지식 없이도, 교량 BIM 데이터에 대한 관계 기반 정보를 직관적으로 조회할 수 있으며, 이는 지식그래프 기반 BIM 데이터 활용의 접근성을 실질적으로 향상시키는 효과를 가진다. 특히 본 연구에서 제안한 스키마 중심 GraphRAG 기반 질의 생성 방식은 부재 간 공간적・구조적 관계를 명시적으로 활용할 수 있다. 해당 관계 정의는 교량의 역학적 구조를 기반으로 한 관계 설정과 온톨로지 내 클래스 위계 구조를 확장함으로써, 라멘교뿐만 아니라 거더교, 현수교, 사장교 등 보다 복잡한 구조 형식으로의 확장이 가능하다. 또한 Few-shot Learning 기반 접근을 적용함으로써 별도의 도메인 특화 학습 데이터나 추가적인 모델 재학습 없이도 질의 자동 생성이 가능할 것으로 기대한다.
