

1. 서 론
2. BIM-유한요소해석 연계 해석을 위한 데이터 전처리
2.1 BIM 활용 필요성 및 IFC 표준
2.2 ABAQUS 및 Python API
2.3 거대언어모델 입출력 특성
3. BIM-유한요소해석 자동화 파이프라인 구축
3.1 IFC 기하 정보 추출 및 STP 변환 자동화
3.2 Python API를 활용한 ABAQUS 구조해석 자동화
3.3 자동화 알고리즘 검증을 위한 구조해석 결과
3.4 ODB 결과 데이터의 LLM 학습용 데이터 변환
4. 데이터 형식별 LLM 인식 성능 평가 및 분석
4.1 성능 평가 항목 및 테스트 설계
4.2 인식 성능 비교 분석
4.3 최적 조합 도출 및 결과 고찰
5. 결 론
1. 서 론
최근 AI 기술이 급격하게 발전함에 따라 공학 전반에서의 활용 가능성이 세계적으로 주목받고 있다. 로보틱스, 제조, 의학 등의 과학기술 분야에서는 AI 기술의 활용 가능성이 널리 입증되었지만, 건설 산업의 고도화와 그에 따른 현대 프로젝트의 규모 증대로 인해 구조공학 분야에서의 AI 기술은 아직 충분히 활용되지 못하고 있다(Tapeh and Naser, 2023). 실무에서 다루는 구조시스템은 형상과 종류가 매우 다양하고 고려해야 할 조건과 변수들이 복잡하게 얽혀 있기 때문에 이러한 특성을 AI 모델이 스스로 반영하고 처리하기에는 한계가 있다. 설계 검증, 손상 진단, 성능 예측 등 다양한 시나리오에서 AI를 활용하기 위해서는 AI가 학습 가능한 대규모 고품질 구조 응답 데이터가 필요하다. 이때, 구조 응답 데이터로서 구조실험 결과 데이터를 활용하는 것은 물리적 신뢰성이 높다는 장점이 있으나, 비용과 시간의 제약으로 인해 데이터 규모를 확장하기 어렵다는 점에서 비효율적이다. 이에 따라 유한요소해석과 같은 수치해석 기법으로부터 체계적으로 생성된 대규모 구조해석 결과를 AI 학습 데이터로 사용하는 경우가 많으며, 이러한 구조해석 도구 중 하나로서 유한요소해석 기반 구조해석 소프트웨어인 ABAQUS가 널리 활용되고 있다. 최근 유한요소해석 워크플로우 내에 생성형 AI 모델을 통합함으로써 광범위한 전문 지식없이 구조해석을 자동으로 수행할 수 있는 가능성이 제시되고 있다(Wei, 2024). 또한 대규모 언어 모델(Large Language Model, LLM)을 활용한 유한요소해석 자동화에 대한 접근법이 최근에 제시된 바 있다(Tian and Zhang, 2024).
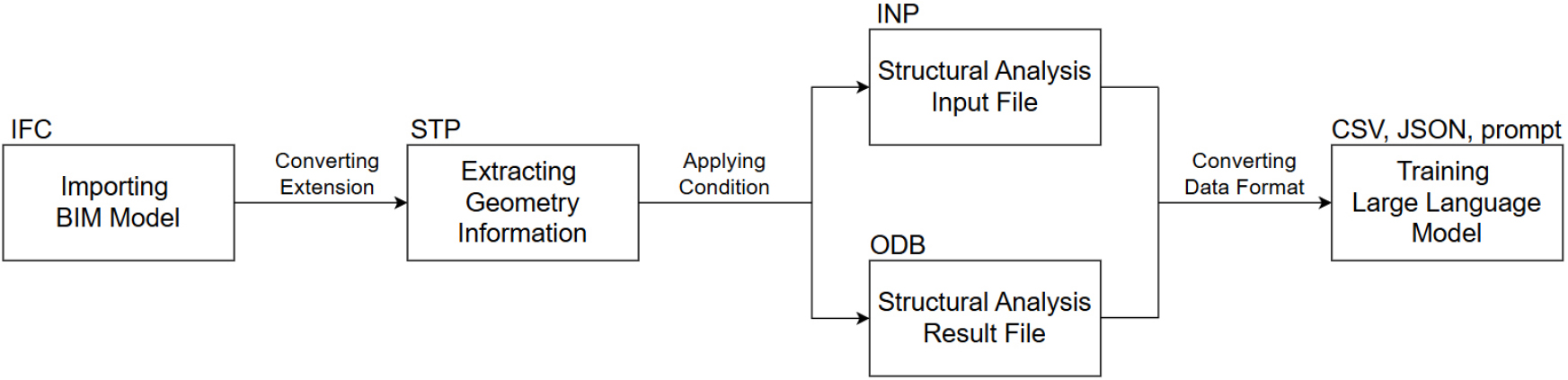
유한요소해석의 자동화를 위해서는 Building Information Modeling(BIM)과 유한요소해석 소프트웨어 간 상호 운용 문제를 해결해야 한다. BIM 기술은 방대한 건설 관련 정보들을 하나의 표현 형식으로 통합한다는 점에서 활용도가 높지만, 데이터 스키마와 파일 형식 간의 불일치 등으로 인해 ABAQUS 같은 구조해석 소프트웨어와의 직접적인 상호 운용에 제약이 따른다. 엔지니어들은 BIM 모델로부터 얻은 정보와 구조해석에 필요한 부가적인 정보들을 ABAQUS/CAE에 직접 입력하며, 이러한 수작업 기반의 데이터 전처리 과정에서 상당한 시간이 소요된다. 또한 기존의 구조해석 소프트웨어가 생성하는 바이너리 형식의 결과 파일은 LLM이 직접 처리하기 어렵기 때문에 이를 LLM이 학습 가능한 텍스트 기반의 데이터로 변환하려면 추가적인 후처리 과정이 필요하다. 이러한 문제들을 해결하기 위해 이 연구에서는 BIM 모델에서의 기하 정보 추출부터 유한요소해석 수행까지의 전 과정을 자동화하고 구조해석 결과 파일을 AI가 학습 가능한 데이터 형식으로 자동 변환하는 알고리즘을 제시한다. ABAQUS가 제공하는 Python API를 활용하여 Graphical User Interface(GUI) 없이 강구조 라멘 모델에 대한 구조해석 과정을 구현하였다. 또한 AI 학습의 신뢰도 평가를 위하여 생성된 결과 파일의 데이터 형식과 LLM 간 조합에 따른 정보 인덱싱 성능을 분석하였다.
2. BIM-유한요소해석 연계 해석을 위한 데이터 전처리
2.1 BIM 활용 필요성 및 IFC 표준
구조해석의 자동화를 위해서는 표준화된 데이터를 기반으로 하는 구조해석 모델이 필요하다. BIM은 기하학적 형상, 물리적 특성, 구성요소의 명칭 및 기능적 특성을 통합적으로 표현한 3차원 정보 모델로서(Migilinskas et al., 2013), 구조 설계 과정에서 요구되는 물리적 정보와 해석 정보를 하나의 표준화된 데이터 형식으로 제공한다(Yusuf, 2020). 이러한 특성은 구조해석 소프트웨어와의 연계를 효과적으로 지원하는 동시에 데이터 신뢰성과 처리 효율성을 높인다. 따라서 이 연구에서는 기하 정보 추출 대상으로 BIM 모델을 사용하였다.
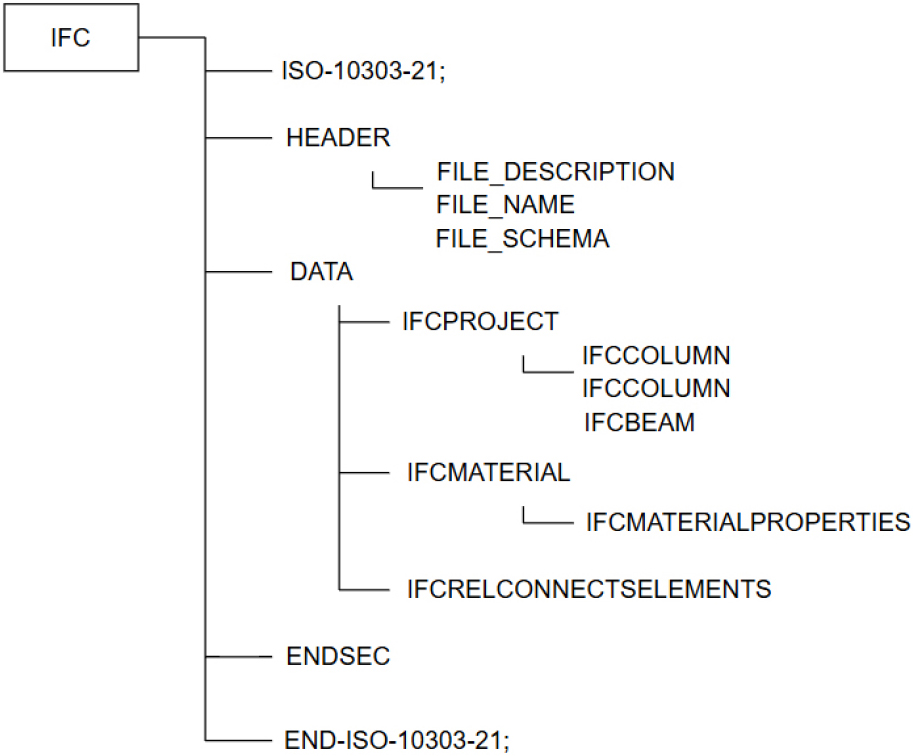
BIM은 여러 소프트웨어 간의 데이터 공유를 필수적으로 요구하므로 공개적이고 풍부한 데이터 포맷이 필요하다(Ramaji and Memari, 2018). 현재 BIM의 데이터 포맷으로서 IFC가 사용되고 있으며, 이 표준으로 인해 다양한 프로젝트 간의 정보 교환과 소프트웨어와의 상호운용이 이루어지고 있다(Antunes et al., 2024). IFC는 모델에 대한 정보를 각 엔티티 간의 상호 관계를 통해 체계적으로 표현할 수 있다. 엔티티는 공간 구조 계층과 물리적 객체 계층 등을 포함하고 있으며, 상위 엔티티와 하위 엔티티 간의 관계를 형성해 공통 속성 내에 세부 속성들을 확장해 나간다. Fig. 1은 IFC 데이터 구조의 간단한 예제를 도식화한 것이다. 여기서 IFCPROJECT는 공간 구조 계층이자 최상위 계층이다. IFCMATERIAL은 물리적 객체 계층이며, 이곳에 정의된 재료 정보들이 최상위 계층인 IFCPROJECT와 연결된다. IFCRELCONNECTSELEMENTS는 부재들 간의 연결 관계를 나타낸다.
2.2 ABAQUS 및 Python API
이 연구에서는 BIM과 구조해석의 연계와 해석 과정의 자동화를 위하여 ABAQUS를 사용하였다. Fig. 2는 실제 엔지니어가 ABAQUS를 활용해 구조해석을 수행하는 과정을 나타낸다. 기존의 방법은 구조해석에 필요한 정보들을 사용자가 전부 직접 입력해야 하므로 이러한 수작업 기반의 데이터 전처리 과정에서 상당한 시간이 요구된다는 단점이 있다. 그러나 ABAQUS/CAE의 동작이 Python 객체와 함수를 기반으로 이루어진다는 특성을 활용하면 Fig. 2의 과정을 GUI 없이도 자동 수행하도록 할 수 있다. 모든 해석 작업은 ABAQUS 내부의 Model Database(mdb) 객체를 중심으로 수행된다. mdb는 ABAQUS 구조해석의 전 과정을 통합적으로 관리하는 Python 기반 데이터베이스 객체로서, 사용자가 생성하는 모든 구조적 특성이 이 객체의 하위 계층에 포함된다. 즉, 사용자는 mdb 객체를 통해 ABAQUS의 GUI 환경에서 수행하던 작업을 Python 코드에서도 동일하게 제어할 수 있다.

2.3 거대언어모델 입출력 특성
LLM은 텍스트 기반의 순차 데이터를 처리하도록 설계되었으며, 방대한 텍스트 코퍼스를 학습하여 문맥을 이해하고 응답을 생성하며 입력값을 토큰으로 변환할 수 있음을 전제로 한다. 그러나 ABAQUS가 출력하는 결과 해석 파일은 바이너리 형식인 ODB(Output Database) 확장자로, 이러한 비정형 데이터는 비구조적 특성으로 인해 효율적으로 활용하기 어렵다. Ahn과 Lee(2025)의 연구에 따르면 비정형 데이터를 구조화하고 학습 가능한 형태로 가공하는 과정은 응답 정확도, 처리 효율성, 문맥 이해력 등 핵심 성능 지표에 중대한 영향을 미친다. 따라서 ODB 파일에서 유의미한 공학 데이터를 추출하여 텍스트 기반 데이터 형식으로 변환하는 작업이 선행되어야 한다. 그러나 텍스트 변환에 더해 이를 어떤 형식으로 구조화하여 입력하는지도 LLM의 데이터 인덱싱 성능에 큰 영향을 미친다. Wedholm(2024)의 연구에 의하면 동일한 정보라도 JSON 등 어떤 형식으로 LLM에 입력하는지에 따라 모델 응답의 일관성뿐만 아니라 문제 해결 논리와 결과의 합리성에까지 큰 영향을 미친다.
3. BIM-유한요소해석 자동화 파이프라인 구축
Fig. 3는 이 연구에서 제시한 BIM-유한요소해석 자동화 파이프라인의 전체 흐름을 도식화한 것으로, Fig. 2에서 제시한 수작업 기반의 ABAQUS 구조해석 절차에 비해 상당히 간소화되었음을 알 수 있다.
이 연구에서는 강구조 라멘 모델을 BIM 모델로 생성하였고, 이 시험 모델을 대상으로 자동화 파이프라인을 설계하였다. 각 부재의 단면은 H형 단면으로 모델링하였고 두 기둥의 바닥면을 고정단으로 구속하였다. Fig. 4는 시험 모델의 정면 개략도이다. 탄성계수, 포아송 비, 밀도를 포함한 부재별 기하 정보와 물성값을 Table 1에 나타내었다.
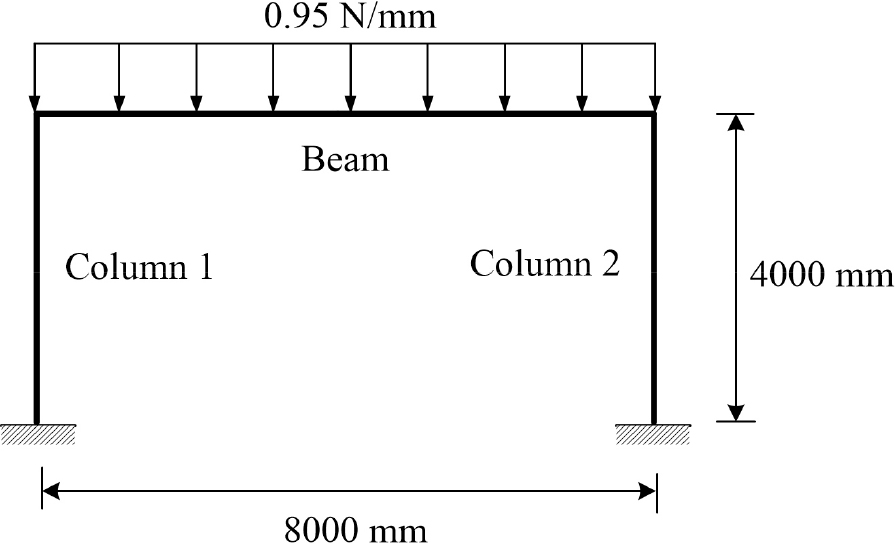
Table 1.
Dimensions and material properties for each member in the test model
3.1 IFC 기하 정보 추출 및 STP 변환 자동화
ABAQUS는 STEP(Standard for the Exchange of Productdata) 형식을 따르는 STP 확장자 파일로부터 기하 정보를 추출하여 이를 Part로 생성한다. 즉, BIM 모델을 ABAQUS로 불러오기 위해서는 IFC 파일을 STP 파일로 변환하는 과정이 필요하다. STP는 IFC와 달리 기하 정보만을 포함하기 때문에 단일 엔티티만으로 전체 형상을 표현할 수 있으며, 이러한 단일 구조 덕분에 ABAQUS는 구조물을 부재 단위로 분리하여 인식할 수 있다.
이 연구에서는 IFC 파일을 STP 파일로 변환하기 위하여 IfcOpenShell이 제공하는 IfcConvert 프로그램을 사용하였다. IfcConvert 프로그램을 호출하기 위하여 Python의 표준 라이브러리인 subprocess 모듈을 사용하였다. 사용자에게 IFC 파일을 입력으로 제공하도록 하였고 IfcConvert 프로그램을 통해 이를 STP 파일로 변환하였다.
3.2 Python API를 활용한 ABAQUS 구조해석 자동화
Python API를 활용하여 시험 모델에 대한 ABAQUS 구조해석 과정을 GUI 없이 구현하였다. mdb.openStep 함수를 사용하여 3.1절에서 변환된 STP 파일을 불러와 Part를 생성하였고, 물성치는 mdb.Material 객체 안에 정의하였다. 완성된 세 개의 Part는 mdb.rootAssembly 객체 안에 각각 독립적인 Instance로 정의하였고, IFC 파일의 기하 정보를 참고하여 이들을 공간상에 배치하였다. 기둥과 보는 서로 강접합되어 있으므로 두 개의 접합부에 Tie를 부여하였다. 좌표계를 이용하여 각 Instance가 갖는 x좌표의 최댓값과 최솟값을 결정하였고, getBy BoundingBox 함수를 통해 동일한 x좌표를 갖는 집합을 추출하였다. 이렇게 추출한 집합을 통해 Instance 간의 접합면을 정의하였고, mdb.Tie 함수를 사용하여 강접합 조건을 부여하였다.
정적 자중 해석을 위해 mdb.StaticStep 객체를 생성하여 해석 모드를 정적 해석으로 설정하였다. 해석 결과에는 변위, 응력, 반력, 접촉력이 포함되도록 하였다. mdb.Gravity 함수를 사용하여 y축 방향의 중력가속도를 -9.81m/s2로 설정하였다. 두 기둥의 하단 지점이 고정단 조건을 만족하도록 경계조건을 부여하였다. 경계면을 정의하기 위하여 Tie를 부여한 방법과 마찬가지로 getByBoundingBox 함수를 사용하였다. y좌표로 0을 갖는 집합을 추출하여 경계면을 정의하였고, mdb.Encastre BC 함수를 사용하여 고정단 조건을 부여하였다. 요소 분할을 위해서 assy.generateMesh 함수를 사용하였다. 강체 회전으로 인한 추가적인 변형 자유도를 고려하여 3차원 8절점 솔리드 요소인 C3D8I을 사용하였으며 요소 크기는 30mm로 설정하였다.
mdb.Job 함수를 사용하여 입력된 정보들을 토대로 시험 모델에 대한 구조해석을 수행하였다. 구조해석이 완료되면 출력으로 INP 파일과 ODB 파일이 생성된다. INP 파일은 해석에 대한 모든 지시 사항과 정보 입력 과정을 텍스트 형식으로 저장한다. 사용자는 INP 파일 안의 정보들을 재구성할 수 있으며 이를 반영하여 구조해석을 재수행할 수 있다. 이는 추후 LLM과의 상호작용을 통해 입력 정보를 자동으로 수정하고, 수정된 파일을 기반으로 새로운 해석을 수행하는 순환형 프로세스의 개발에 활용될 수 있다.
3.3 자동화 알고리즘 검증을 위한 구조해석 결과
Fig. 5(a)는 이 연구에서 생성한 IFC 파일을 Open IFC Viewer 26.5.0을 통해 나타낸 기하학적 형상이고, Fig. 5(b)는 이 연구의 알고리즘을 통해 생성한 INP 파일을 ABAQUS에서 나타낸 기하학적 형상이다. Fig. 5(a)와 5(b)의 두 기하 형상은 서로 일치하며, ABAQUS의 Query Tool을 사용하여 확인한 결과, 각 부재들의 길이가 Table 1에 제시한 길이와 일치하였다. 이는 BIM 모델의 기하 정보를 추출하는 과정에서 기하 간섭이나 엔티티 손실이 발생하지 않았음을 의미한다.
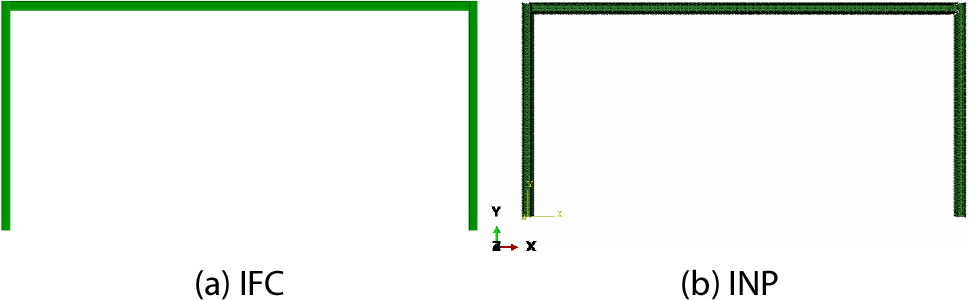
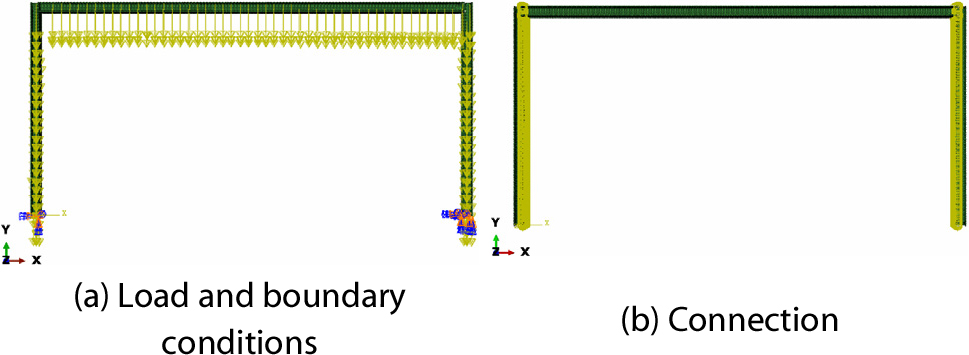
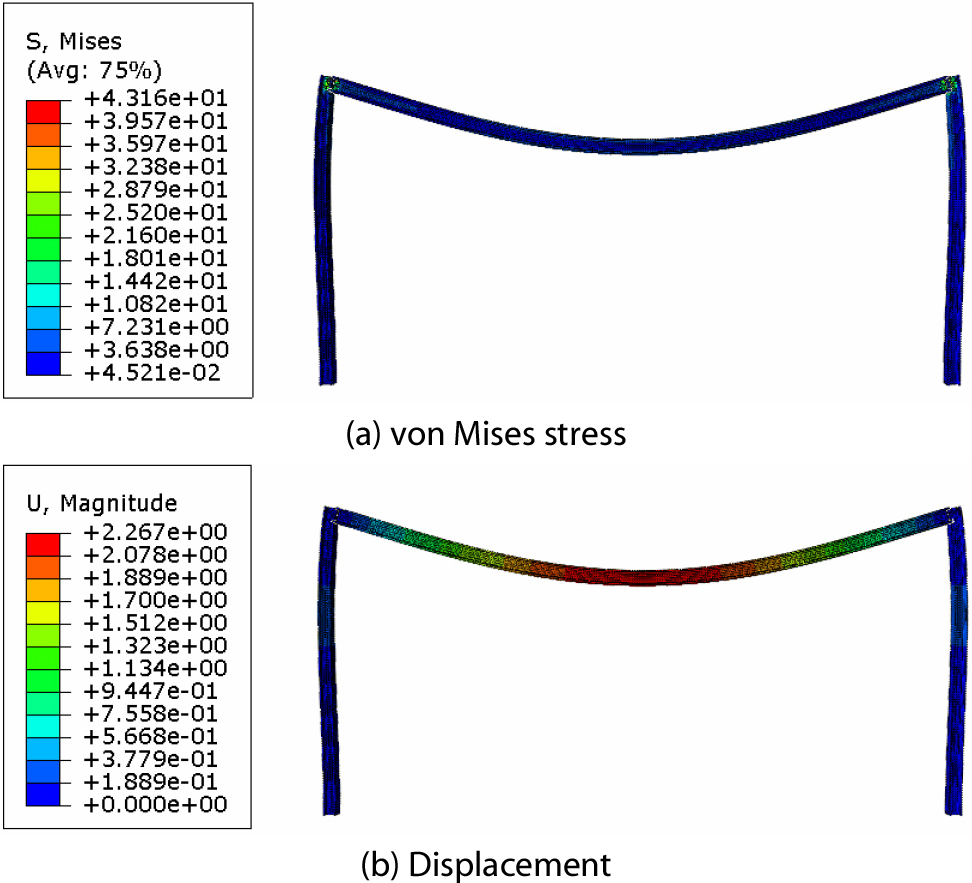
Fig. 6(a)와 6(b)는 생성된 INP 파일에 정의된 하중 및 경계조건과 부재 간의 접합 조건을 ABAQUS로 시각화한 결과이다. 이로부터 시험 모델의 해석 정보들이 ABAQUS에서 제대로 부여되었음을 알 수 있다. Fig. 7(a)와 7(b)는 생성된 ODB 파일을 ABAQUS로 불러와 시각화한 구조물의 von Mises 응력 과 변위를 나타낸다. 보의 중앙에서 가장 높은 응력과 변위가 기록되었으며, 자중만을 고려했으므로 이러한 결과는 타당하다. 따라서 이 연구에서 제시한 Python API 기반 구조해석 자동화 알고리즘은 기하 정보 추출, 해석 조건 적용, 구조해석 수행까지의 전 과정에서 유효하다.
3.4 ODB 결과 데이터의 LLM 학습용 데이터 변환
3.3절을 통해 얻은 ODB파일을 AI 학습에 용이한 구조화된 형식으로 변환하기 위하여 필요한 데이터를 추출하고 이를 다시 텍스트 형식으로 재생성한다. ODB파일에 포함된 다양한 정보 중에서 ABAQUS API를 이용하여 각각의 부재에 대해 절점과 요소의 고유 번호, 3차원 좌표값, 변위 벡터 그리고 응력 텐서 데이터를 추출한다. 요소의 위치정보는 기하학적 중심으로 저장된다. 절점 변위는 세 직교 좌표 성분 , , 의 값으로 추출되고 응력 텐서는 , , , , , 6개의 값으로 추출된다. 추출된 정보는 LLM의 성능 평가를 위해 세 가지 구조화된 형식으로 변환하였으며 각각의 부재에 대해 분할하여 저장하였다.
4. 데이터 형식별 LLM 인식 성능 평가 및 분석
자동화 파이프라인으로 생성된 구조해석 데이터가 실제로 LLM에 의해 효과적으로 처리될 수 있는지 검증하였다. 또한 최적의 데이터 형식과 LLM 모델 조합을 탐색하기 위한 성능 평가 실험을 설계하고 수행하였다.
4.1 성능 평가 항목 및 테스트 설계
구조 해석과 연동해 LLM에 입력하는 데이터 형식의 후보군은 토큰 효율성과 LLM의 입출력 처리 특성을 고려하여 선정하여야 한다. Mior(2024)에 따르면 LLM이 이미 방대한 데이터를 학습하는 과정에서 소스 코드 내 JSON 스키마를 접했을 가능성이 높으므로 그 계층적 구조에 익숙할 수 있다. 또한 Hojda(2025)의 연구에서는 대형 모델과 비교하여 상대적으로 텍스트 처리능력이 약한 소형 모델도 표 형식의 데이터 처리는 비교적 잘 수행하는데, 이는 CSV도 효과적인 데이터 입력 형식이 될 수 있음을 의미한다. 또한 prompt는 LLM의 가장 기본적인 상호작용 방식으로서 직접적인 형태로 데이터를 제공할 수 있다. 이 연구에서는 선행 연구를 고려하여 구조 해석 데이터 형식으로 적합하다고 볼 수 있는 JSON, CSV, 그리고 prompt를 평가 대상 데이터 형식으로 선정하였다. 이러한 데이터를 처리할 LLM은 OpenAI의 ChatGPT-4, Google의 Gemini 2.5 Pro, Anthropic의 Claude 4의 유료 모델로 선정하였다.
이 연구에서는 LLM의 구조 해석 데이터 이해도를 평가하기 위하여 StructTest(Chen et al., 2025)의 벤치마크 접근법을 활용하였다. 이 방법은 질문지의 답변을 사전에 정의된 정답지와 비교하는 규칙 기반 평가자 방법이다. 각 LLM 모델에 3.4절에서 변환한 데이터 파일과 주석 파일을 함께 입력한 후 순차적으로 질문을 입력하였고, 그 답에 대해 정답 1점, 근사치 0.5점, 오답 0점으로 채점하였다. 최종 성능은 정답률로 산출하였다. 이를 통해 객관적이고 자동화된 방식으로 LLM의 구조해석 데이터 이해도를 평가할 수 있다. LLM의 구조물 인식, 해석 데이터 검색, 통계, 추론 등 구조해석과 관련된 공학적 정보를 LLM이 인식하는 수준을 분석하고자 하였다. Table 2는 LLM에 제공하는 질문지 내용을 나타낸다. 각 질문 카테고리는 데이터에서 구조 정보 인식 여부, 데이터 내 특정 정보 검색 능력, von Mises 응력식 적용 등 복합 수행 능력, 명시적으로 존재하지 않는 정보 유추 능력의 평가를 목적으로 한다.
Table 2.
Questions for evaluating the LLM recognition of structural analysis data
4.2 인식 성능 비교 분석
설계한 평가 항목과 테스트 설계를 바탕으로 3종의 LLM과 3종의 데이터 형식을 교차 검증하는 정량 평가를 수행하였다. 각 조합의 성능은 정답률(%)을 기준으로 측정하였다.
4.2.1 LLM 모델별 성능 분석
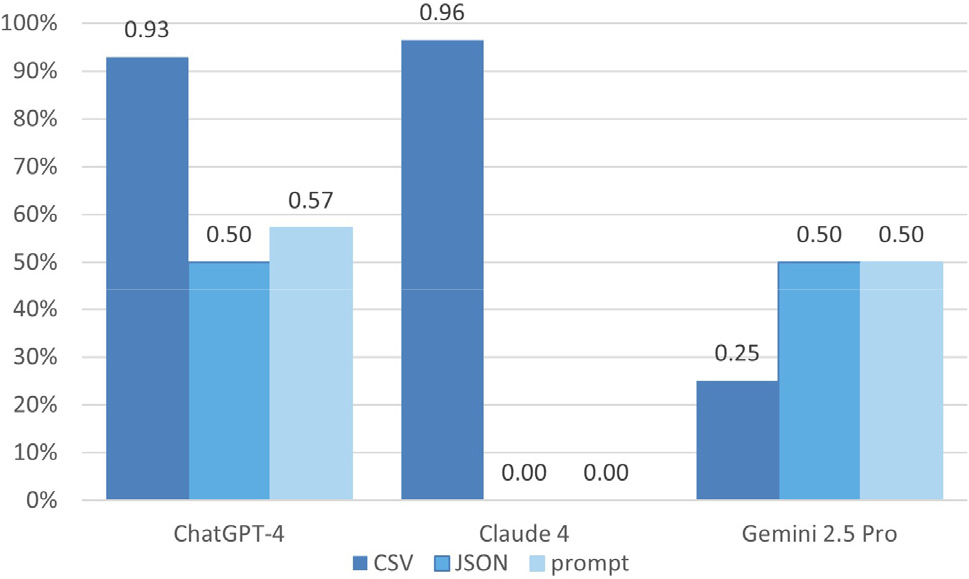
Fig. 8은 3종의 LLM 모델별 구조해석 정보 인식 성능을 나타낸다. Claude-4는 CSV 형식에서 96%의 높은 인식 정확도를 보였으나 JSON과 prompt 형식은 파일 용량이 커서 업로드할 수 없었다. ChatGPT-4는 이 실험에서 3가지 데이터 형식을 성공적으로 인식했으며 특히 CSV 형식에서는 93%의 높은 정답률을 보였다. Gemini 2.5 Pro는 모든 데이터 형식에 대해서 50% 이하의 낮은 정답률을 보였다. 이는 계산이 필요한 ‘데이터 검색’과 ‘통계’ 항목에서 세부 답변의 정확도가 상대적으로 낮았기 때문인 것으로 추정된다. 또한 Gemini는 보안 정책상 업로드된 파일 전체를 직접 열람하지 않고 요약된 일부 데이터를 활용하기 때문에 정확도가 제한적이었던 것으로 평가된다. 모든 데이터 형식에 호환되고 높은 계산 정확도를 보인 모델은 ChatGPT-4로 확인되었다.
4.2.2 데이터 형식별 성능 분석
LLM의 구조해석 데이터 인식 실험 결과를 데이터 형식별로 정리하였다. Fig. 9에 따르면 데이터 형식이 LLM의 인식 성능에 실질적으로 큰 영향을 미친다는 것을 알 수 있다. CSV 형식은 보안 정책으로 인해 평가가 제한적이었던 Gemini를 제외한 나머지 모델에서 평균 94% 이상으로 매우 높았다. 그러나 이를 제외한 나머지 형식의 정답률은 모두 50% 이하로 저조하게 나타났는데, 이로부터 정답률이 높은 CSV가 구조 해석 데이터 처리에 가장 효율적인 형식이라고 볼 수 있다.
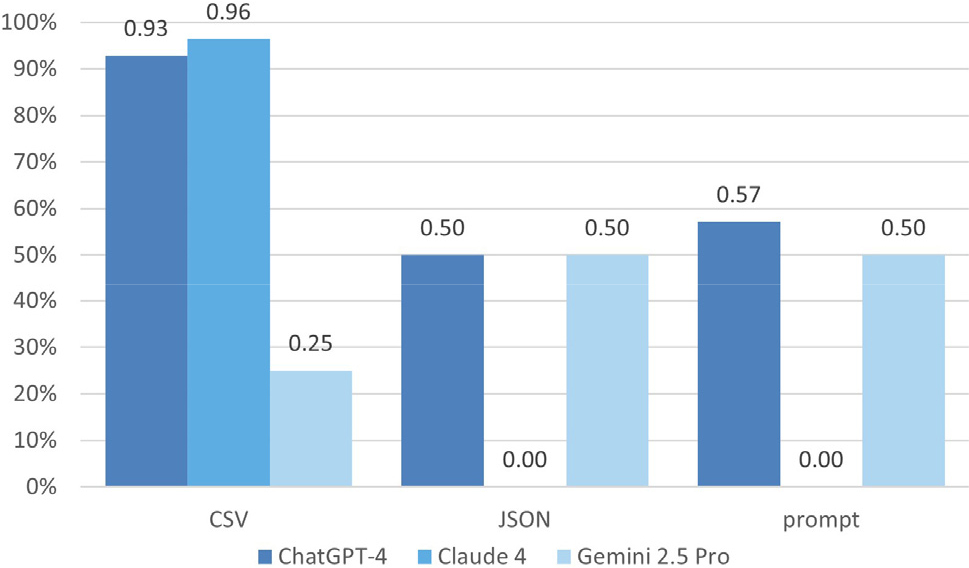
구조 인식과 데이터 검색으로 구분된 평가 영역에서 파일 형식별 정답률 차이가 큰데, 이는 LLM이 데이터를 탐색하고 색인하는 데 있어 JSON의 복잡한 계층적 구조나 prompt의 모호한 자연어 형식보다 CSV의 평면적이고 명확한 표 구조가 효율적임을 시사한다. 이러한 결과는 선행 연구와도 일치하는데, LLM의 구조화된 데이터 생성 능력을 벤치마킹한 Yang 등(2025)의 연구에서는 LLM을 통해 텍스트를 타 형식으로 변환할 때 CSV로 변환 시 100%의 높은 정확도를 기록했다. 이는 CSV의 단순하고 평면적인 구조가 LLM에게 더 직관적이고 오류없이 처리될 수 있음을 시사하며, 이러한 특성은 대규모 데이터를 처리해야 하는 구조해석 분야에서 유리하다.
4.3 최적 조합 도출 및 결과 고찰
모델 측면에서는 ChatGPT-4가 3가지 데이터 형식을 모두 높은 정확도로 인식하였고, 형식 측면에서는 CSV가 평균 94%로 타 형식 대비 높은 정답률을 기록하였다. 이러한 결과를 종합적으로 고려할 때, 현재 시점에서는 ChatGPT-4 모델과 CSV 데이터 형식의 조합이 AI 학습용 구조해석 데이터를 처리하는 데 안정적이고 효과적인 방법으로 평가된다. 이러한 연구 결과는 LLM을 실제 구조해석에 활용할 때 중요한 시사점을 제공한다. JSON의 계층 구조나 자연어 prompt보다 단순하고 평면적인 CSV 형식의 입력이 LLM의 구조해석 데이터 처리 성능을 극대화하는 효율적인 방법이라고 할 수 있다. 그러나 이번 연구에서는 용량의 제한으로 Claude 4에 JSON과 prompt 형식의 조합을 적용하지 못했고, 보안 정책으로 인해 Gemini에 CSV 형식의 데이터를 정상적으로 적용하지 못했다. 이에 따라 향후 모델 업데이트에 따른 추가적인 호환성 검증이 필요할 수 있다.
5. 결 론
이 연구에서는 IFC 기반의 BIM 모델로부터 기하 정보를 추출하여 구조해석을 수행하고, 그 결과를 LLM이 해석 가능한 텍스트 형식으로 자동 변환하는 단방향 파이프라인을 제안하였다. 이러한 과정은 Python API를 활용하여 시험 모델에 대한 ABAQUS 구조해석을 자동화하고, 결과 해석 파일인 ODB파일을 LLM의 데이터 처리 특성을 고려하여 적합할 것으로 추측되는 CSV, JSON, prompt의 후보군으로 변환하고 가장 효율적인 입력 형식을 테스트 및 선정하는 것을 포함한다.
검증을 위해 2개의 기둥과 1개의 보를 가진 H형 단면 강구조 라멘 모델을 대상으로 파이프라인을 적용하였다. 복합적인 엔티티 구조를 가진 IFC 파일을 ABAQUS가 인식할 수 있는 기하 정보 STP(STEP) 파일로 변환하는 과정을 자동화하기 위해 IfcOpenShell의 IfcConvert 프로그램을 Python의 subprocess 모듈을 사용했다. ABAQUS의 Python API를 활용하여 Part와 Material을 정의, 기둥과 보 사이에 Tie(강접합) 조건을 부여, 바닥면에 고정단 경계조건 적용하고 ODB 결과해석 파일을 얻는 과정을 GUI 없이 자동화하였다.
LLM 인식 성능 평가를 위해서 객관적이고 재현성이 높은 규칙 기반 평가자 방법의 벤치마크를 설계하였고, ODB파일의 정보를 AI 학습에 효율적인 CSV, JSON, prompt 형식으로 변환하고 각 파일의 구조를 설명하는 주석 파일을 함께 생성하여 입력 파일을 생성했다. ChatGPT-4, Claude4, Gemini2.5Pro 모델을 대상으로 정보 인덱싱 성능을 평가한 결과, LLM 모델 중에서는 GPT-4가 모든 형식에 대해 데이터 처리에 성공했으며 데이터 형식 중에서는 CSV가 평균 94% 이상의 가장 높은 정답률을 보인다는 결과를 얻었다.
이 연구의 의의는 BIM 모델의 데이터셋을 효율적으로 구조해석에 이용할 수 있는 파이프라인 구축과, 나아가 이후 LLM을 활용한 구조해석 연구 및 실무 적용 시 원본 해석 데이터를 어떤 형식으로 변환해야 AI가 가장 효율적으로 처리할 수 있는지에 대한 실무적인 기준 제시에 있다. 이 연구에서 개발한 자동화 파이프라인이 아직 특정 구조 형식에 국한되는 한계점을 가지고 있으므로, 후속 연구에서는 모듈의 범용성을 확보하고 데이터 처리 기술을 고도화해야 할 것이다. 이 연구는 BIM 모델의 구조적 타당성을 자동으로 검증하고 보완하는 혁신적인 설계 자동화 시스템 개발을 위한 초석이 될 것으로 기대된다.
