

1. 서 론
구조실험정보를 위한 데이터 모델은 구조실험과 관련된 실험정보를 정형화하여 표현하므로 데이터 저장소를 개발하는데 이용할 수 있다. 컴퓨터 시스템으로 구현하여 인터넷으로 접속할 수 있도록 만든 데이터 저장소는 연구논문이나 보고서에 비하여 구조공학자와 연구자들이 실험정보를 더 편리하게 저장하고 검색하고 내려 받을 수 있는 장점이 있다.
데이터 저장소의 예로는 미국 내에서 14개 대학에서 수행된 구조실험을 포함한 다양한 종류의 실험을 공유하기 위한 목적으로 설립된 NEES(https://nees.org)에서 관리하는 NEEShub Project Warehouse가 있으며, 국내에서는 12개의 대학과 연구기관의 실험시설(완공 예정 포함)을 체계적으로 운영하고 관리하기 위하여 설립된 건설연구인프라운영원(http://www.koced.net)의 사이버 문헌정보관이 있다. NEEShub Project Warehouse는 각각의 프로젝트에 대한 실험정보를 여러 단계로 구성하여 저장하고 이와 관련된 모든 데이터 파일들을 저장하도록 되어 있어서 실험정보에 대한 구체적인 내용들을 모두 살펴볼 수 있다. 건설연구인프라운영원의 사이버 문헌정보관에서는 실험에 대한 개요를 살펴볼 수 있고 실험데이터 파일과 논문 및 보고서를 내려 받을 수 있다. NEEShub Project Warehouse와 건설연구인프라운영원의 사이버 문헌정보관은 모두 실험데이터 파일을 내려 받아 살펴볼 수 있는 기능을 제공하지만 NEEShub Project Warehouse는 계층화된 실험정보 구성을 가지고 있어서 대규모의 다양한 실험에 대한 정보를 손쉽게 이해할 수 있는 특징을 가지고 있다.
NEEShub Project Warehouse는 오랜 기간에 걸쳐서 Reference NEESgrid Data Model(Peng and Law, 2004) 등의 데이터 모델을 기초로 하여 개발되고 개선이 이루어져서 현재의 데이터 저장소로 구축된 것이다. 국내에서 NEEShub Project Warehouse와 같은 전문적인 데이터 저장소를 개발하고자 할 때에는 데이터 모델의 이용이 바람직한데 특히 규모가 크고 복잡한 실험정보를 데이터 모델을 통하여 효율적으로 구성할 수 있다(Lee et al., 2008).
구조실험정보를 위한 데이터 모델을 데이터 저장소의 개발에 이용하기 위해서는 데이터 모델에 대한 평가가 정확히 이루어져야 하는데 이와 관련된 연구로는 데이터 모델의 구성특성에 대한 수치적인 평가요소(Lee, 2010), 레벨별 실험정보의 평가요소(Lee, 2013), 개별적인 실험정보의 구성평가요소(Lee, 2014)가 있다. 이러한 평가요소들은 데이터 모델에 대한 서술적인 평가가 아닌 구체적이고 수치적인 평가가 가능하도록 하였지만, 개발된 데이터 모델이 데이터 저장소로 구현이 되었을 때 얼마나 효율적으로 사용되고 있는지에 대한 상세한 평가방법은 다루어지지 않았다. 본 논문에서는 데이터 모델의 구성을 사용성 측면에서 분석하기 위한 새로운 평가요소를 소개하고 이를 NEES의 데이터 모델에 적용하여 그 타당성을 검토하였다.
2. 데이터 모델의 구성 및 사용성 평가의 범위
구조실험을 위한 데이터 모델을 클래스(class)와 객체(object)의 개념을 이용하여 표현하면 데이터 모델의 자체적인 구성은 클래스로 나타낼 수 있고 실제의 실험정보들은 객체로 나타낼 수 있다. 본 논문에서 데이터 모델의 클래스와 객체의 표현은 개체형 통합설계모델(Hong et al., 1994; Lee et al., 1998)의 표기법을 이용하였다. 이 표기법을 이용하여 간단히 만든 데이터 모델의 클래스와 객체가 Fig. 1에 나타나 있는데 이 그림을 이용하여 데이터 모델의 구성 및 사용성 평가의 범위를 설명하도록 한다.
Fig. 1에서 클래스는 사각형으로 객체는 타원으로 표시하였으며 속성(attribute)은 사각형 또는 타원 아래에 수평선과 함께 나타내었다. 단일 값을 갖는 속성(SVA; single- valued attribute)이면 수평선의 끝을 흰색 원으로 복수의 값을 갖는 속성(MVA, multi-valued attribute)이면 수평선의 끝을 검은색 원으로 표시하였다. 속성의 수평선 아래의 괄호에는 속성의 종류 정보가 있는데 B는 기본속성(base attribute)을 DVA는 숫자, 문자, 파일 등을 값으로 갖는 속성(data-valued attribute)을 의미하며 OEVA는 다른 객체를 값으로 갖는 속성(object entity-valued attribute)을 의미한다.
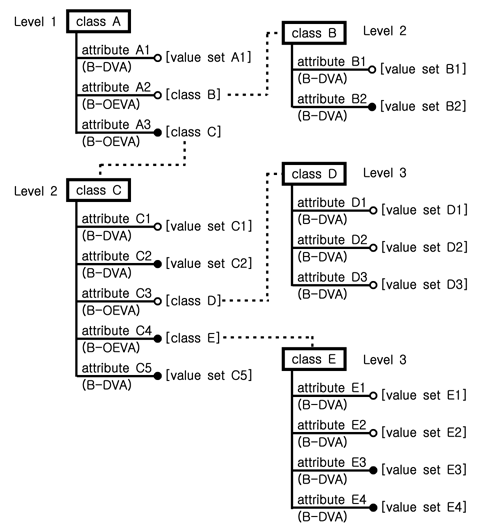
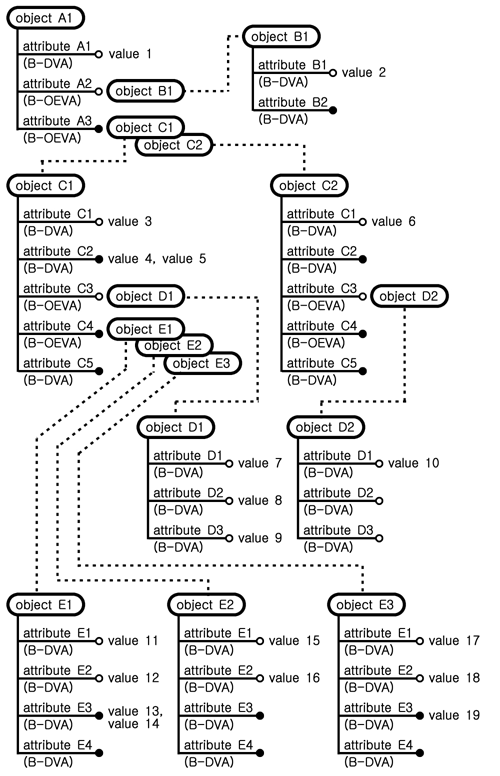
Fig. 1에서 클래스와 객체는 여러 단계의 레벨에 걸쳐서 분포하고 있다. 예를 들면 Fig. 1(a)에서 레벨 1에 있는 클래스 A는 그 속성들을 통하여 레벨 3까지의 정보를 포함하고 있으며, 레벨 2에 있는 클래스 C는 레벨 3까지의 정보를 포함하고 있다. 이와 같은 이유로 어떤 클래스의 구성을 평가할 때 클래스의 자체적인 속성을 포함하여 하위레벨에 있는 모든 클래스와 속성들을 고려하여야 한다. Fig. 1(a)에 있는 클래스를 하위레벨을 고려하여 기본 정보를 정리한 것이 Table 1에 나타나 있다. 클래스 C의 경우를 보면 5개의 자체적인 속성을 가지지만 실제로는 2개 레벨에 걸쳐서 3개의 클래스를 포함하고 있고 총 12개의 속성들이 관련되어 있다.
Table 1
Organization of classes and attributes in example data model
(Note) For each class, the number in parentheses indicates the number of attributes.
Fig. 1(a)에 있는 클래스들이 실제의 실험정보를 갖게 될 때의 상태가 Fig. 1(b)에 나타나 있는데 클래스별로 다양한 수의 객체를 갖고 각 객체에서 값이 있는 속성 수도 다르다. 예를 들면 객체 C1과 C2는 클래스 C로부터 생성된 것으로서 5개의 속성 중에서 객체 C1은 값이 있는 속성 수가 4개이고 객체 C2는 값이 있는 속성 수가 2개이다. 객체 C1과 C2가 모두 클래스 C로부터 생성이 되었지만 그 사용성의 정도에서는 차이가 있다. 객체 C1은 하위레벨에 또 다른 여러 개의 객체를 포함하지만 객체 C2는 하위레벨에 단 1개의 객체만을 포함하고 있어서 하위레벨을 고려하면 그 사용성에 더 큰 차이가 생긴다는 것을 알 수 있다.
Fig. 1과 Table 1에서 나타난 클래스들에 대하여 설명한 바와 같이 데이터 모델의 구성과 사용성에 대한 평가는 각 클래스별로 하위레벨을 포함하여 관련된 모든 클래스와 속성에 대한 고려가 필요하기 때문에 이에 대한 평가요소를 소개하고 적용하는 것을 본 논문에서의 데이터 모델의 평가범위로 한다.
3. 데이터 모델의 구성 및 사용성 평가요소
데이터 모델의 구성 및 사용성 평가를 위하여 각 클래스의 자체적인 구성으로부터 하위레벨에 있는 모든 클래스들을 포함한 구성 그리고 데이터 모델이 포함하고 있는 전체 클래스에 대한 평가를 위하여 정의한 평가요소들이 Table 2에 나타나 있다.
Table 2
Definitions of evaluation criteria for use of data model
(Note) AVE indicates the ratio of attribute value existence.
Table 2에 나타난 평가요소는 5개로서 속성의 사용성에 대한 ‘AVE(attribute value existence)’라는 용어를 포함하고 있는데 해당 속성에 값이 있는가를 의미한다. 아래쪽에 있는 평가요소부터 살펴보면 Attribute AVE는 해당 속성이 있는 클래스의 객체들 중에서 값이 있는 객체의 비율을 의미하고 Class AVE는 클래스 내에 값이 있는 속성의 비율을 의미하며 이를 하위 레벨의 모든 클래스까지 확장한 것이 Class Level AVE이다. Project AVE는 하나의 프로젝트에 있는 모든 클래스들의 속성사용 비율을 의미하는데, 데이터 모델을 이용하여 저장된 모든 프로젝트에 대하여 평균값을 계산하면 Data Model AVE가 된다.
Table 2에 나타난 평가요소를 Fig. 1과 Table 1에서 나타난 클래스들을 이용하여 계산한 결과가 Table 3에 나타나 있다. Fig. 1의 데이터 모델의 아래쪽부터 사용성 평가를 해보면 Fig. 1의 맨 아래 부분에 있는 속성 E1은 3개의 객체들에서 모두 값을 가지고 있으므로 Table 3에서 Attribute AVE는 1.0이 되고 Fig. 1에서 속성 E4는 3개의 객체들에서 모두 값이 없으므로 Table 3에서 Attribute AVE는 0.0이 된다. 이와 같은 방법으로 클래스에 대하여 살펴보면 클래스 E로부터 생성된 3개의 객체에 대한 평균 속성사용 비율을 계산하면 Class AVE가 0.668이 된다. 평균 66.8%의 속성들이 사용되고 있다는 의미로 보면 된다. Table 3에서 클래스 C의 Class AVE는 0.6이지만 Class Level AVE가 0.528이므로 클래스 C의 하위레벨까지 고려하면 사용성이 약간 낮아진다는 것을 알 수 있다. Fig. 1(b)에 나타난 모든 객체와 속성에 대한 사용성을 계산하면 Table 3에서 0.608의 수치를 나타내고 있다. Fig. 1(a)의 데이터 모델은 Fig. 1(b)로 표시되는 하나의 프로젝트만을 고려하였으므로 Data Model AVE도 동일한 수치를 갖게 되며 데이터 모델은 60.8%의 사용성을 갖고 있는 것으로 이해할 수 있다.
Table 3
Values for evaluation criteria for use of example data model
(Note) ave(number 1, number 2, ---, number n) indicates the average of the numbers in parentheses.
4. 데이터 모델의 구성 및 사용성 평가요소의 적용
데이터 모델의 구성 및 사용성 평가를 위하여 본 논문에서 정의한 5개의 평가요소들을 실제의 데이터 저장소에 사용하는 데이터 모델에 적용하였을 때 어떠한 결과를 나타내고 그것이 어떠한 의미를 나타내는지에 대한 확인을 NEES 데이터 모델을 이용하여 수행하였다.
4.1 NEES 데이터 모델의 클래스와 속성
NEEShub Project Warehouse의 대략적인 실험정보의 구성이 Fig. 2에 나타나 있다. 하나의 project는 여러 개의 experiment를 포함하고 있으며 하위레벨로 내려가면 trial, repetition이 있고 여러 가지 실험데이터를 저장하기 위한 unprocessed data, converted data, corrected data, derived data 등을 포함하고 있다. 이러한 내용이 NEES에서 사용하는 데이터 모델의 근간을 이루는데 세부적인 구성을 모두 나타내면 복잡하기 때문에 중요한 내용만을 발췌하여 Table 4에서 클래스와 속성으로 나타내었다. Table 4에서 project 클래스는 최상위 레벨인 레벨 1에 있으며 19개의 속성을 포함하고 있다. project 클래스의 속성 중에서 여러 개의 속성은 하위레벨의 클래스를 포함하고 있는데 밑줄 친 experiments 속성에 대하여만 그 속성과 관련이 있는 하위 레벨의 experiment 클래스와 그 속성들이 나타나 있다. Table 4에서는 8개의 클래스와 56개의 속성이 있어서 NEES 데이터 모델이 포함하는 클래스와 속성의 일부이지만 NEES 데이터 모델의 핵심내용을 이해하는데 부족하지 않으며 본 논문에서 다루는 평가요소의 타당성을 검토하기에는 충분한 분량인 것으로 볼 수 있다.
4.2 NEES 데이터 모델의 구성 및 사용성 평가결과
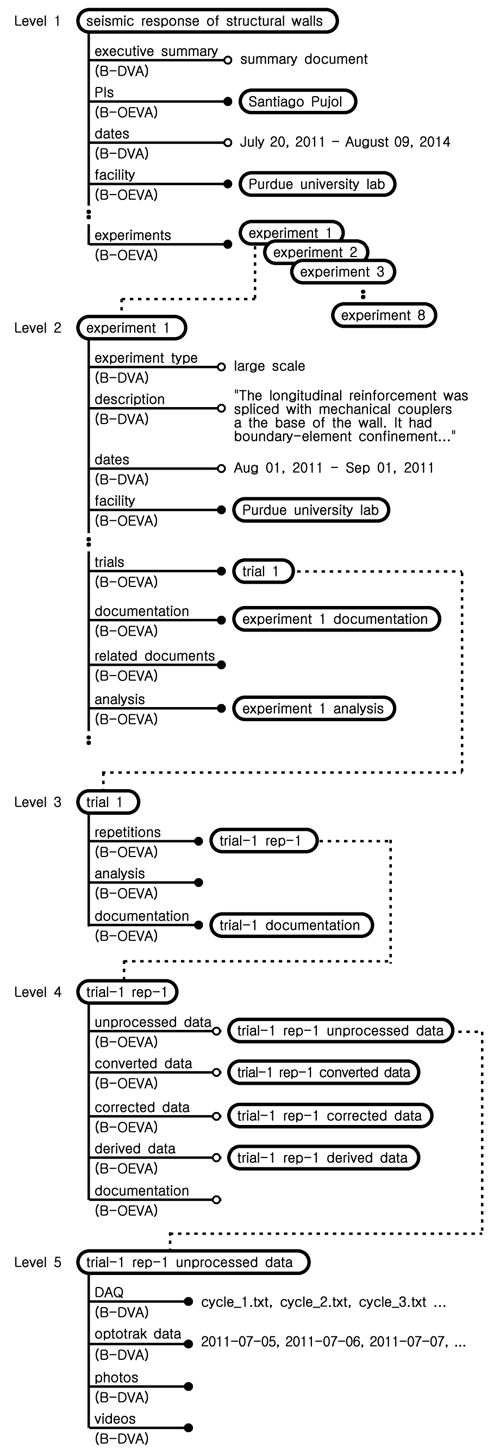
NEEShub Project Warehouse에는 Fig. 2와 Table 4에 나타난 구성에 따라서 저장된 프로젝트가 260개 이상 있는데 이중에서 실험정보가 잘 갖추어졌기 때문에 Enhanced Projects라는 이름으로 구분해 놓은 프로젝트 중에서 하나의 프로젝트(Year of Curation 2014; Project Number 1050)에 대하여 객체와 속성을 표현한 것이 Fig. 3에 나타나 있다. Fig. 3에서 레벨 1에 seismic response of structural walls 객체가 있고 이 객체의 experiments 속성은 8개의 객체를 포함하고 있다. 이중에서 experiment 1 객체가 레벨 2에 나타나 있고 이 객체의 trials 속성은 레벨 3의 trial 1 객체를 포함하고 있다. 이러한 연결이 레벨 5까지 이르고 있다.
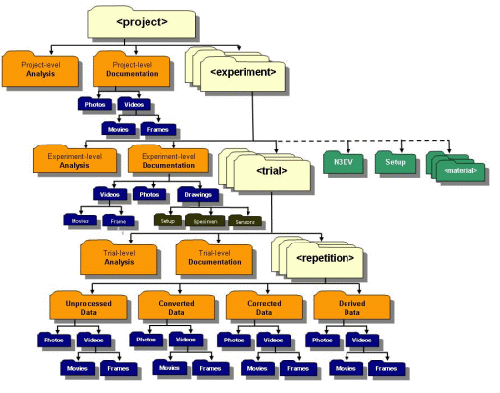
Fig. 3에 나타난 객체와 속성으로 표현되는 프로젝트에 대한 데이터 모델의 사용성을 평가하기 위해서는 Fig. 3의 모든 객체와 속성을 정확히 구분하여 기록하는 것이 필요하였는데 Table 5에서 제안한 표기법을 이용하였다. 시간이 많이 걸리는 과정이었지만 이러한 과정은 나중에 적절한 프로그래밍을 이용하여 자동화하여 해결하면 된다. Table 5는 객체의 속성이 가지고 있는 값의 개수를 표시하고 있기 때문에 1개의 project 객체가 8개의 experiment 객체를 포함하고 있고 하위레벨로 가면 10개의 trial 객체가 있고 10개의 repetition 객체가 있는 것을 알 수 있으며 각 객체에 대하여 값이 있는 속성의 수도 쉽게 계산할 수 있다.
Fig. 3에 나타난 프로젝트에 대하여 Table 5의 표기법을 이용하여 데이터 모델의 구성 및 사용성에 대한 평가 결과를 계산한 내용이 Table 6에 나타나 있다. Table 6에서는 3개의 프로젝트에 대한 평가결과가 있는데 Fig. 3에 나타난 프로젝트는 project 1으로 표시되어 있으며, project 2(Year of Curation 2014; Project Number 1053)와 project 3 (Year of Curation 2015; Project Number 1132)에 대한 평가결과도 포함하고 있다.
4.3 NEES 데이터 모델의 구성 및 사용성 평가결과의 분석
Table 6에 나타난 NEES 데이터 모델의 구성 및 사용성 평가결과를 살펴보면 Data Model AVE는 0.566으로서 절반을 약간 넘는 사용성을 보이고 있으며 Project AVE는 프로젝트별로 차이가 있다. 각 프로젝트별로 구성 및 사용성 평가결과를 분석하고 3개의 프로젝트의 구성 및 사용평가 결과를 종합적으로 비교․분석하였다.
4.3.1 project 1의 구성 및 사용성 평가결과의 분석
Table 6에서 project 1은 0.739라는 비교적 높은 사용성을 나타내는데 Class Level AVE를 보면 하위레벨로 갈수록 사용성이 낮아지고 있어서 구체적인 실험데이터가 미비한 것처럼 보인다. 개별 클래스의 Class AVE에 대하여는 상위 레벨에 있는 project 클래스와 experiment 클래스가 높은 사용성을 보이고 하위레벨에 있는 클래스 중에서는 repetition 클래스가 높은 사용성을 보이고 있지만 trial 클래스와 다른 클래스들은 낮은 사용성을 나타내고 있다. 이에 대한
Table 4
Organization of selected classes and attributes in NEES data model
(Notes)
1) For each class, the number in parentheses indicates the number of attributes.
2) Each underlined attribute has as its value set a lower level class shown in the table.
이유를 찾기 위하여 Attribute AVE로 표시되는 속성 사용성을 살펴보면 trial 클래스에서는 trial analysis 속성의 사용성이 0으로 되어 있고 unprocessed data 클래스 등에서는 photos 속성과 videos 속성의 사용성이 0으로 되어 있다. trial analysis 속성은 상위 레벨에 있는 클래스들의 project analysis 속성, experiment analysis 속성과 중복되는 부분이 있고 photos 속성과 videos 속성은 상위 레벨에 있는 documentation 속성에 비슷한 속성(Table 6에는 나타나 있지 않음)이 있기 때문인 것으로 파악된다. 따라서 project 1에서 하위레벨에서 실험데이터가 미비한 것은 실험데이터를 잘 입력하지 않았기 보다는 데이터 모델의 구성에서의 문제점으로 보인다. 또한 unprocessed data, converted data, corrected data, derived data 클래스는 한 가지 repetition에 대한 것이므로 photos 속성과 videos 속성은 repetition 클래스에 한 번만 두는 것이 바람직한 것으로 추정된다.
Table 5
List of object numbers and attribute numbers for project in NEES data model
(Notes)
1) The notation for an object is as follows: ((level number, object number, number of values),(level number, object number, number of values),---, (level number, object number))
2) The notation for an attribute is as follows: ((level number, object number, number of values),(level number, object number, number of values),---, (level number, object number, number of values))
4.3.2 project 2의 구성 및 사용성 평가결과의 분석
Table 6에서의 project 2에 대한 Project AVE는 0.429로서 비교적 낮은 편이다. Class Level AVE를 살펴보면 하위레벨로 갈수록 낮아지는데 repetition 클래스에 대한 수치가 극단적으로 낮아지는 문제가 있음을 볼 수 있다. 그 이유 중의 하나를 Class AVE에서 찾으면 repetition 클래스의 사용성이 낮은데 대부분의 속성의 사용성이 0이기 때문이며 또한 하위레벨에 있는 unprocessed data, converted data, corrected data, derived data 클래스 중에서 3개의 클래스의 사용성이 0이기 때문이다. 이를 통하여 이러한 4개의 클래스의 실험정보가 모든 실험에서 공통적인 것이 아니라는 의미로 판단된다. 따라서 만일 데이터 모델을 공통적인 실험데이터를 저장하는 목적으로 개발한다면 이와 관련된 클래스들을 통합하여 단순화 시킬 필요가 있다.
4.3.3 project 3의 구성 및 사용성 평가결과의 분석
Table 6에서의 project 3에 대한 Project AVE는 0.530으로 다른 두 프로젝트의 중간정도의 사용성을 갖는다. Class Level AVE를 살펴보면 하위레벨로 갈수록 사용성이 낮아지고 있다. Class AVE를 살펴보면 project 클래스는 최상위 레벨에 있음에도 낮은 사용성을 갖고 있다. 최하위 레벨에 있는 클래스들에 대하여는 project 2에서와 같이 전혀 사용되고 있지 않는 derived class와 같은 클래스가 존재하고 있다. project 3에서의 Attribute AVE를 살펴보면 project 2에서와 같이 사용성이 0인 것들을 발견할 수 있는데 그중의 하나가 related documents 속성이다. 이 속성은 documentation 속성과 함께 여러 곳에서 분포하는데 두 가지 속성의 유사성으로 인하여 모든 장소에서 두 가지 속성의 사용성이 모두 높기는 어려운 조건이다. 따라서 두 속성을 통합하든가 또는 일부 레벨에서만 함께 있도록 구성하는 방법으로 사용성을 높일 필요가 있다.
Table 6
Values for evaluation criteria for use of NEES data model
4.3.4 구성 및 사용성 평가결과의 종합적인 비교분석
Table 6에서의 3가지 프로젝트를 비교하면 사용성이 비슷한 클래스도 있고 그렇지 않은 클래스도 있다. Class AVE에 대하여 살펴보면 project 클래스는 프로젝트별로 사용성이 큰 차이를 보이지만 experiment 클래스는 그렇지 않다. 이는 project 클래스의 속성 구성이 experiment 클래스와 비교하여 덜 일반적이라는 의미로 받아들일 수 있다. trial 클래스도 모든 프로젝트에서 낮은 사용성을 보이고 있는데 클래스의 속성구성이 바람직하지 않아 개선의 여지가 있는 것으로 해석할 수 있다.
Table 6에 나타난 평가결과의 분석을 종합하면 본 논문에서 소개한 5가지 평가요소를 사용하여 데이터 모델의 구성과 사용성에 대한 여러 가지 내용을 이해할 수 있었다. 개별적인 Class AVE와 Attribute AVE를 통하여 개선이 필요한 클래스와 속성을 찾아낼 수 있으며 Class Level AVE를 통하여 레벨 구성에서 개선이 필요한 부분을 찾아낼 수도 있다. 여기에 더하여 프로젝트별 Project AVE들을 비교하면 데이터 모델에서 효율적으로 구성된 부분과 개선이 필요한 부분을 더욱 명확히 구별하여 파악할 수 있다. Data Model AVE는 데이터 모델이 가지고 있는 전체 속성들 중에서 값을 갖는 속성의 비율(즉, 사용되고 있는 속성의 비율)을 의미하는 것으로 이해하면 되는데 이에 따라서 많은 수의 클래스와 속성을 갖는 데이터 모델일수록 Data Model AVE가 낮아지는 경향을 나타내므로 이를 고려하여 데이터 모델의 사용성 평가에 이용하는 것이 필요하다.
5. 결 론
본 논문에서는 데이터 모델의 구성과 사용성을 평가하기 위한 평가요소들을 제안하였고 이 평가요소들을 구조실험을 포함한 여러 가지 실험정보를 포함하는 데이터 저장소인 NEEShub Project Warehouse에 이용된 데이터 모델에 적용하여 타당성을 검토하였다. 본 논문의 요약 및 결론은 다음과 같다.
(1)구조실험정보를 위한 데이터 모델의 구성과 사용성에 대한 평가는 각 클래스별로 하위레벨에 분포된 모든 클래스와 이에 대한 속성을 고려하여 수행되어야 한다.
(2)클래스의 속성이 값을 갖는지를 의미하는 사용성에 대한 ‘AVE(attribute value existence)’라는 용어를 도입하고 속성의 사용성에 대한 Attribute AVE, 클래스의 사용성에 대한 Class AVE, 하위 레벨에 있는 클래스를 포함하는 Class Level AVE, 하나의 프로젝트의 모든 클래스에 대한 Project AVE, 모든 프로젝트를 포함하는 데이터 모델에 대한 Data Model AVE를 정의하였다.
(3)Attribute AVE와 Class AVE를 이용하여 사용성이 낮은 속성과 클래스를 쉽게 찾아낼 수 있으며 이를 Class Level AVE와 연계하면 사용성이 높은 부분과 낮은 부분이 어떻게 분포하는 가를 이해할 수 있다.
(4)Project AVE가 서로 다른 여러 개의 프로젝트가 있으면 Attribute AVE, Class AVE, Class Level AVE를 프로젝트별로 교차하여 비교하는 과정을 통하여 개선이 필요한 부분을 명확히 파악할 수 있다.
(5)Data Model AVE는 데이터 모델의 전체적인 사용성을 나타내는데 클래스와 속성의 개수가 많은 대규모의 데이터 모델일수록 Data Model AVE가 낮아진다.
(6)본 논문에서 소개한 데이터 모델의 구성과 사용성에 대한 평가요소는 NEES 데이터 모델이외의 다른 종류의 데이터 모델에도 적용가능하며 실제의 데이터 모델의 개발과정에 충분히 응용할 수 있을 것으로 판단된다.
