

1. 서 론
2. 관련 연구(Related Work)
2.1 구조공학 분야의 LLM 적용과 한계
2.2 검색-증강 생성(RAG)과 전문분야 검색기
3. StructCPT 검색 시스템 설계 (Methodology)
3.1 지식베이스 구축과 요구사항
3.2 StructCPT 검색기의 구조와 원리
3.3 MAXIM 대조학습 기법의 필요성
4. 성능 평가
4.1 실험 구성
4.2 결과 및 비교 분석
4.3 시스템 효율성과 적용 가능성
5. 결론 및 향후 연구
1. 서 론
건축 구조공학 분야에서 대형 언어 모델(Large Language Models, LLM)의 급속한 발전은 새로운 가능성과 도전을 함께 가져오고 있다. 최근 연구들은 LLM이 구조해석, 설계 최적화, 지진 응답 평가 등 복잡한 구조공학 업무 수행에 높은 잠재력을 보임을 입증하였다 (Tapeh and Naser, 2023). 예를 들어 딥러닝 기반 언어 모델을 활용하여 건물의 동적 거동을 예측하거나 구조 설계안을 자동으로 생성하는 시도가 이루어지고 있다. 그러나 이러한 발전에도 불구하고, 한국 구조공학 실무 환경에 LLM을 적용하는 데에는 여전히 상당한 한계가 존재한다. 대표적인 문제는 LLM의 환각 현상으로 모델이 사실과 다른 정보를 그럴듯하게 생성하는 경향이다 (Ji et al., 2023). 구조물의 안전성이 최우선인 구조공학 분야에서 철근 콘크리트 배근이나 철골 접합부 설계에 대한 잘못된 정보는 심각한 안전사고로 이어질 수 있다. 또한, 일반 LLM의 훈련 데이터가 최신 건축구조 기준이나 신기술을 반영하지 못하면 실제 설계 적용 시 중요한 오류가 발생할 수 있다. 이러한 문제는 특히 한국형 구조설계 기준(KDS, KBC 등)과 같이 지역 특화 규정을 준수해야 하는 경우에 더욱 두드러진다.
이러한 한계를 극복하기 위한 유망한 접근법으로 검색-증강 생성(Retrieval-Augmented Generation, RAG) 기술이 주목받고 있다(Borgeaud et al., 2022; Lewis et al., 2020). RAG는 LLM이 응답을 생성할 때, 사전에 구축된 지식베이스로부터 관련 정보를 검색하여 제공함으로써 정확성과 신뢰도를 높인다. 예를 들어, 학교 건물의 내진 설계나 비정형 구조물의 동적 거동 분석과 같은 복잡한 문제에 대해 최신 연구결과나 설계 지침을 검색해 모델에 주입하면 보다 정확한 답변을 얻을 수 있다. 실제로 방대한 외부 지식을 참조하는 RAG 기법은 의료, 법률 등 다양한 분야의 질의응답에서 LLM의 환각을 줄이고 최신 정보로 보강하는 효과를 보이고 있다(Xia et al., 2025).
그러나 한국 건축구조공학 분야에 특화된 효과적인 RAG 시스템을 구축하려면 여러 도전과제가 있다. RAG 시스템은 일반적으로 지식베이스(Corpus,말뭉치), 검색기(retriever), 그리고 생성기(LLM)의 다양한 구성요소로 이루어지는데, 각 요소를 구조공학 전문 지식을 잘 반영하도록 최적화해야 한다. 특히 검색기는 사용자의 전문적 질의에 대해 방대한 구조공학 문헌과 기준서 중에서 정확한 근거를 찾아주는 핵심 역할을 한다. 기존의 키워드 기반 검색(예: BM25)이나 범용 밀집 임베딩 검색 모델(예: Contriever)은 전문 용어, 약어, 그리고 한국어로 기술된 구조공학 지식을 충분히 포착하지 못할 수 있다. 예컨대 “전단 보강근 간격”이나 “기둥 좌굴 길이”와 같은 용어는 일반 도메인 모델이 이해하기 어려우며, 영어로 주로 학습된 임베딩 모델은 한글 용어 및 국내 기준의 뉘앙스를 놓칠 수 있다. 따라서 도메인 특화 검색기의 개발이 필수적이다.
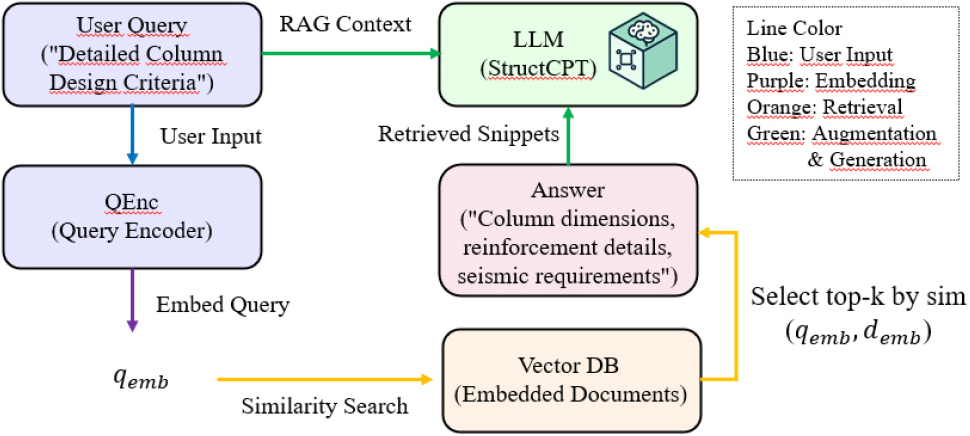
본 논문에서는 Fig. 1과 같이 한국 건축구조공학 도메인에 특화된 RAG 시스템인 StructCPT를 제안한다. StructCPT는 구조공학 분야에 맞춤 개발된 검색기로서, 대조학습 기반의 MAXIM 검색 기법을 활용하여 질의-문서 간 최대 유사도를 학습한다. 이를 통해 국내 구조기준, 전문용어, 설계사례 등의 방대한 지식베이스에서 질의에 가장 적합한 근거를 실시간으로 추출하고, LLM의 응답 생성에 반영함으로써 정확성을 향상시킨다. 우리는 제안하는 StructCPT의 검색 원리와 MAXIM 대조학습 기법의 구조 및 필요성을 상세히 설명하고, 성능 면에서 기존 기법들과 비교・분석하며, 실제 구조공학 문제에의 적용 가능성을 평가한다. 특히 BM25와 범용 임베딩 모델(Contriever), 학술특화 모델(SPECTER) 대비 StructCPT의 장점을 정량적으로 보여주고, 검색 속도 및 메모리 효율 측면에서의 이점을 논의한다. 마지막으로 제안 기법의 미래 확장 방향으로서 도면・이미지 등 멀티모달 정보 및 지식그래프와의 통합 가능성을 모색한다. 본 연구는 한국 구조공학 분야의 안전 한 의사결정을 지원하기 위한 AI 기술 발전에 기여하며, 해당 분야에 특화된 최초의 대규모 RAG 시스템 개발 및 평가라는 의의를 가진다.
2. 관련 연구(Related Work)
2.1 구조공학 분야의 LLM 적용과 한계
건설 및 구조공학 영역에서는 AI 기술이 점차 활발히 도입되고 있다. 머신러닝 기반의 예지보전, 컴퓨터 비전 기반 구조물 손상 탐지 등 여러 활용이 보고되었으나, 고도화된 자연어 처리 기술의 적용은 아직 초기 단계이다(Feng et al., 2024; Meng et al., 2024). 최근 일부 연구들이 구조공학 문제 해결에 대형 언어 모델을 활용한 사례를 내놓았다. Tapeh와 Naser (2023)은 사전학습된 LLM을 이용해 건축구조 설계에 조언을 얻는 실험을 수행했고, deFitero Domínguez등(2024)은 보고서 생성을 자동화하는 가능성을 탐색하였다. 이러한 시도들은 LLM의 지식 추론 능력이 잠재적으로 구조공학 도메인에서도 유용함을 보여준다. 그러나 앞서 언급한 바와 같이, 구조공학 분야에서 LLM의 단독 활용에는 잘못된 정보 생성, 최신 규정 미반영 등의 한계가 있다. 특히 한국어로 전문지식을 처리해야 하는 경우, 대부분 영어 데이터로 학습된 기존 모델들은 전문 용어 번역 오류나 문화적 맥락 누락을 일으킬 수 있다.
2.2 검색-증강 생성(RAG)과 전문분야 검색기
검색-증강 생성(RAG) 기법은 지식검색과 언어생성을 결합함으로써 LLM의 한계를 완화한다. RAG의 기본 개념은 사용자의 질문에 답하기 위해 사전에 준비된 지식베이스에서 관련 문서를 찾아 LLM에 제공하고, 모델이 이를 근거로 답변을 생성하도록 하는 것이다. Lewis 등(2020)은 지식 집중형 질의응답에서 RAG의 효과를 처음 체계적으로 입증하였고, 이후 의료(Abacha et al., 2023)나 법률 등 다양한 분야에서 RAG 응용 연구가 활발하다. RAG의 성능은 검색기(retriever)의 성능에 크게 좌우되는데, 일반적으로 아래 두 가지 접근이 널리 사용된다:
1)전통적 문자열 기반 검색기: 대표적으로 BM25(Robertson and Zaragoza, 2009)는 질의와 문서 간 공통 단어(키워드)의 빈도와 역문헌빈도 등을 고려하여 관련 문서를 찾는다. BM25는 구현이 간단하고 특정 키워드 일치에 강점을 보여 여전히 강건한 성능을 보이는 경우가 많다. 다만 문장 구조나 동의어를 고려하지 않기 때문에 전문 용어가 일치하지 않으면 관련 문서를 놓칠 수 있다. 특히 구조 설계기준과 같이 엄밀한 용어로 기술된 문서를 찾을 때, 질의 표현이 정확히 맞지 않으면 검색 누락이 발생한다.
2)사전학습 임베딩 기반 검색기: 최근에는 질의와 문서를 각각 벡터 임베딩으로 변환하여 유사도를 측정하는 밀집 검색(dense retrieval)이 각광받고 있다. 질의-문서 쌍을 대조학습(contrastive learning)으로 훈련한 쌍변환기(dual encoder)를 활용하면 의미적으로 유사한 문장은 벡터 공간에서 가까워지도록 임베딩할 수 있다. Karpukhin 등(2020)은 대용량 질의응답 쌍으로 DPR(Dense Passage Retriever)을 훈련하여 초기 기여를 하였고, 이후 Xiong 등(2020)의 ANCE 등 개선된 학습 기법들이 제안되었다. 범용 도메인에서 뛰어난 성능을 보이는 공개 임베딩 모델로 Contriever가 있는데, 위키피디아 등을 활용한 자기지도학습으로 개발되어 사전 지식 없이도 강력한 성능을 보인다(Izacard et al., 2021). 한편, 논문 검색 등 과학기술 도메인에 특화된 임베딩 모델로 SPECTER가 있으며, 논문 간 인용 관계 그래프를 활용한 학습으로 유사 연구주제 문서를 잘 연결해낸다(Cohan et al., 2020). 이처럼 임베딩 기반 검색은 단어의 어형이 달라도 의미가 유사하면 잘 매칭하지만, 모델이 훈련 때 보지 못한 특수한 도메인 개념에 대해서는 정확도가 떨어질 수 있다.
구조공학 분야의 도메인 특화 검색기에 대한 연구는 아직 보고된 바가 거의 없다. 구조공학은 일반 문서와 달리 수식, 도면, 표준 코드 조항 등 다양한 형태의 지식이 혼재하며, 한글/영어 혼용 전문용어, 약어가 많아 검색이 까다롭다. 따라서 구조공학에 적합한 말뭉치 구축과 전문 검색 알고리즘 개발이 요구된다. 본 연구진은 선행 연구로 한국 구조공학 지식과 질의응답 데이터를 집대성한 SAFE 벤치마크를 구축하고 여러 RAG 구성의 성능을 평가하였는데, 이때 구조공학 특화 검색기의 필요성이 강조되었다. 본 논문에서는 이러한 배경을 바탕으로, 구조공학 도메인에 최적화된 검색기 StructCPT와 MAXIM 기법을 새롭게 소개하고자 한다.
3. StructCPT 검색 시스템 설계 (Methodology)
3.1 지식베이스 구축과 요구사항
StructCPT 시스템을 개발하기 위해 먼저 도메인 지식베이스(StructCorpus)를 구축하였다. 한국 건축구조공학 실무와 연구에서 자주 참고되는 자료들을 망라하기 위해 다음과 같은 다양한 출처의 데이터를 수집・정제하였다: (1) 전문 용어집 - 구조공학 핵심 개념과 용어 정의 6,000여 개(한・영 번역 및 해설 포함), (2) 설계기준/표준 - 국내 건축구조기준(KBC) 및 한국산업규격(KS) 등 구조설계 관련 코드 조항, (3) 교과서 및 교육자료 - 대학 교재, 전문서적, 기술보고서 등 이론 및 배경지식, (4) 프로젝트 보고서 - 실제 건설 프로젝트의 구조계산서, 검토의견서 등 사례 기반 문서. 이렇게 총 37만7천여 개의 스니펫(문단 단위 지식)을 선별하여 통합 StructCorpus를 구성하였다. 이 지식베이스는 구조역학, 재료거동, 내진/내풍 설계, 시공 및 유지관리 등 구조공학 전분야를 포괄하며, 한국어를 중심으로 일부 영문 자료를 포함한다. StructCPT 검색기는 이 말뭉치를 대상으로 동작하며, 주요 요구사항은 다음과 같다: 첫째, 구조공학 전문질문에 대하여 높은 재현율로 관련 정보를 찾을 것 (전문 용어가 달라도 의미가 맞으면 찾아야 함); 둘째, 수초 이내의 실시간 응답 속도를 제공할 것; 셋째, 수십만 조각의 지식에서도 메모리 상에서 효율적으로 검색할 수 있을 것; 넷째, 텍스트 외에도 향후 도면, 이미지 등 다른 형식의 데이터와 연계 확장이 가능할 것으로 설정하였다.
3.2 StructCPT 검색기의 구조와 원리
StructCPT는 위 요구사항을 만족하기 위해 이중 인코더 아키텍처와 대조학습 기반 임베딩 최적화를 이용한 도메인 특화 검색엔진이다. Fig. 2는 StructCPT의 전체 학습 절차를 개략적으로 나타낸 것이다. StructCPT는 질의와 문서를 각각 별도 인코더(Transformer 구조)로 임베딩 벡터로 변환하여 벡터 유사도가 곧 질의-문서의 의미적 유사도를 나타내도록 학습된다. 구체적인 원리는 다음 두 단계로 요약된다:
단계 1에서는 구조공학 질의-문서 쌍 데이터를 이용하여 쌍변환기 구조의 질의 인코더(QEnc)와 문서 인코더(DEnc)를 대조학습으로 훈련한다. 양성 쌍에 대해서는 임베딩 유사도를 최대화하고, 음성 쌍에 대해서는 유사도를 최소화하는 방향으로 조정하여, 벡터 공간상에서 의미적으로 밀접한 문서일수록 QEnc-DEnc 출력 벡터가 가까워지도록 한다. 단계 2에서는 학습된 변환기를 활용하여 상위 검색 결과에 대한 교차 인코더(CrossEnc)를 미세조정한다. QEnc가 추출한 상위 문서들 중 양성(관련 있음)과 음성(관련 없음) 예시를 구성하여, 질의-문서 전체 토큰의 상호작용을 고려한 정밀한 유사도 점수를 계산하도록 교차 인코더를 훈련한다. 이로써 최종적으로 Struct CPT는 실시간 추출 단계의 벡터 검색과 재순위 단계의 정밀 판별을 모두 활용하여 고정확도의 검색을 실현한다.
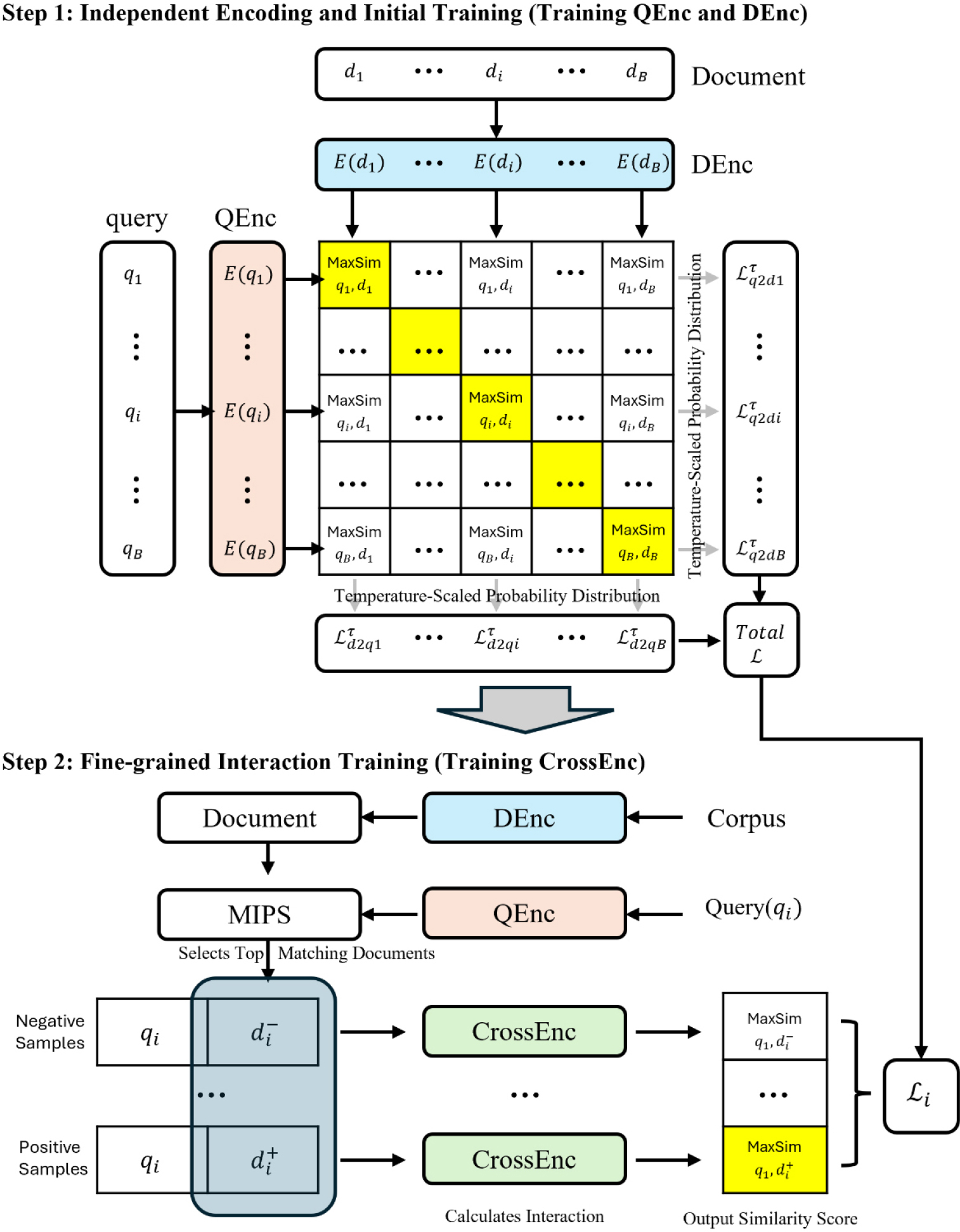
첫 번째 단계는 질의-문서 쌍변환기 학습이다. 구조공학 도메인에 적합한 임베딩 표현을 얻기 위해 우리말 구조공학 질문과 그에 대응하는 관련 문서(스니펫) 쌍을 수집하여 대조학습을 수행하였다. 질의-문서 쌍 데이터는 앞서 구축한 Struct Corpus에서 생성하였다. 예를 들어 전문 용어집의 항목(질의)과 해당 정의문(문서)를 한 쌍으로 삼고, 설계기준 문의사항과 해당 조항 해설, 과거 기술사 문제와 해설지 등을 활용하여 다수의 양성 훈련 쌍을 확보하였다. 임베딩 모델 초기 가중치는 멀티링구얼 미세조정이 용이한 범용 Transformer 기반 언어모델을 활용하였으며, 약 1억 1천만 개 파라미터 규모로 설정하였다(Contriever, SPECTER 등 비교 모델과 유사한 크기). 학습 목표는 주어진 양성 질의-문서 쌍에 대하여 임베딩 유사도(내적값)를 크게 하고, 무작위로 짝지은 음성 쌍에 대해서는 유사도를 낮추는 것이다. 이는 InfoNCE 손실 기반의 대조학습으로 구현되었다. 이렇게 학습된 StructCPT 쌍변환기는 구조공학 분야에서 의미적 유사도에 최적화된 벡터 표현체계를 습득하게 된다. 우리는 이 학습 기법을 MAXIM(Maximum Similarity Retrieval)이라고 명명하는데, 이는 임베딩 공간에서 질의와 문서의 최대 유사도를 달성하도록 학습한다는 의미를 담고 있다. 일반 도메인 임베딩 모델이 구조공학의 맥락을 잘 이해하지 못하는 반면, MAXIM 기법을 거친 StructCPT는 전단설계 vs 휨설계와 같은 개념 구분, 한국어 특유의 용어 사용 등을 반영하여 도메인 지식에 정통한 검색 성능을 발휘한다.
두 번째 단계는 교차 인코더 미세조정이다. 쌍변환기만으로도 대용량 코퍼스에서 고효율로 후보 문서를 검색할 수 있지만, 임베딩 유사도는 질의와 문서의 특정 세부 정보 매칭을 완벽히 반영하지 못할 수 있다. 예컨대 질의에 “KDS 17 10 조항에 의하면...?”처럼 특정 코드 조항을 언급한 경우, 같은 주제 일반 문서보다 실제 해당 조항 텍스트가 더 적합하다. 이를 보완하기 위해 1단계에서 학습된 QEnc로 상위 k개의 후보 문서를 검색한 뒤, 교차 인코더로 이들 후보를 재평가하여 순위를 정교하게 조정한다. 교차 인코더는 질의와 문서의 전체 토큰을 함께 입력받아 세부적인 상호작용까지 고려하여 관련도를 판별하는 BERT 기반 모델이다. 우리는 1단계 학습에서 확보된 모델 가중치를 초기값으로 사용하여, 상위 검색 결과들 중 양성 예시(실제 정답 문서)와 음성 예시(무관한 문서)를 구성, 이들을 구분하도록 미세조정하였다. 이 과정으로 StructCPT는 벡터 검색의 효율성과 문장 단위 정밀판별의 정확성을 모두 갖춘 검색 파이프라인을 완성하게 된다.
StructCPT 검색엔진의 동작 흐름을 정리하면 다음과 같다: 사용자의 입력 질의가 들어오면, 질의 인코더가 해당 질의를 임베딩 벡터로 변환한다. 이 벡터를 키로 하여 미리 임베딩되어 인덱싱된 전체 StructCorpus에서 가장 유사한 문서 벡터들을 최근접 탐색(MIPS: maximum inner product search) 기법으로 효율적으로 찾아낸다. 수십만 문서 중 상위 50-100개 정도의 초기 후보가 밀리초 수준 내에 검색되며, 이어서 교차 인코더가 이들 중 상위 20-30개를 재평가하여 최종 순위를 결정한다. 이렇게 선정된 최종 상위 문서 스니펫들은 LLM 생성기의 입력에 첨부되어, 모델이 근거와 함께 답변을 생성하도록 한다. 이때 chain-of-thought 등의 프롬프트 기법을 병행하여 답변의 논리적 일관성을 높일 수 있다(Wei et al., 2022). Struct CPT의 이러한 두 단계 검색 구조는 실시간성과 정확성의 균형을 맞추어 주며, 구조공학과 같이 방대한 전문 지식이 요구되는 질의에서도 신뢰도 높은 답변을 생성할 수 있도록 한다.
3.3 MAXIM 대조학습 기법의 필요성
StructCPT에 도입한 MAXIM(최대 유사도) 대조학습 기법은 왜 필요할까? 이는 한마디로 도메인 지식의 함양 때문이다. 범용 검색 모델은 인터넷 백과사전이나 뉴스 등을 주로 학습하여 구조공학처럼 특수 전문영역의 세부 내용에는 최적화되어 있지 않다. MAXIM 기법으로 StructCPT를 훈련하면서 얻은 주요 이점은 다음과 같다:
1)전문 용어와 약어 처리: 예를 들어 “PC 부재의 프리스트레스 도입”이라는 질의가 들어온 경우, 일반 모델은 “PC”나 “프리스트레스” 등의 의미 연결을 놓칠 수 있다. 그러나 MAXIM 대조학습은 해당 용어들이 자주 함께 등장하는 문맥(교과서, 기술보고서 등)을 학습하여, 질의 의도 파악과 관련 문서 연결을 정확히 수행한다. 그 결과, “프리스트레스트 콘크리트 부재의 인장응력 도입 방법”에 관한 설명을 담은 문서를 최상위로 찾아낼 수 있게 된다.
2)한국어 및 이중언어 이해: StructCPT는 학습 단계에서 한국어 질의-문서 쌍을 다수 접함으로써, 한국 구조공학 문헌 특유의 표현 방식에 익숙해진다. 예컨대 “기둥 좌굴 길이”라는 질의에 대해 영어로 작성된 문서라도 buckling length 개념이 언급된 부분을 찾아낼 수 있다. MAXIM은 또한 용어집의 한영 병기 데이터 등을 활용하여 다국어 임베딩 공간을 부분적으로 통합하였기 때문에 한글 질의와 영문 문헌 사이의 의미적 매칭도 어느 정도 가능하다.
3)문맥 기반 의미 매칭: 일반 대규모 말뭉치로 학습된 Contriever 같은 모델은 “강도 설계법” vs “허용응력도 설계법”과 같은 구조공학 개념 간 미묘한 차이를 구별하지 못할 수 있다. 반면 StructCPT는 구조공학 전문 문헌의 문맥 속에서 학습되므로, 이러한 대비 개념도 올바르게 분류한다. 즉 MAXIM 기법을 통해 유사 개념은 가깝게, 대조 개념은 멀게 임베딩 공간을 형성함으로써 검색 결과의 정확도를 높였다.
4)최신 정보 반영: 학습 데이터에 최신 설계기준 개정 내용과 최근 연구 성과를 포함함으로써 StructCPT는 빠르게 변화하는 지식을 반영하도록 했다. 예를 들어 2021년 개정된 내진설계 기준에 관한 질의가 들어오면 과거 문헌보다 개정 후 내용을 담은 문서를 우선 제시한다. 이는 사전지식이 고정된 일반 LLM과 달리 최신 문헌을 직접 검색하는 StructCPT의 강점이다.
이렇듯 MAXIM 대조학습은 구조공학 분야에 특화된 맞춤 검색기를 탄생시키는 핵심 기술이라 할 수 있다. 다음 절에서는 이러한 StructCPT 기반 RAG 시스템이 실제 구조공학 Q&A에서 얼마나 향상된 성능을 보이는지 정량적인 실험으로 확인한다.
4. 성능 평가
4.1 실험 구성
StructCPT의 성능을 검증하기 위해 전문가 질의응답 벤치마크를 활용하였다. 벤치마크는 한국어로 된 구조공학 QA 데이터 약 4,200문항으로 구성되며, 구조역학, 재료 및 거동, 구조설계, 시공 및 유지관리 등 5개 세부분야를 포함한다. 각 문항은 객관식 또는 주관식 문제와 정답으로 이루어져 있으며, 일부는 한국건축구조기술사 기출, 일부는 연구논문 Q&A 등 다양하다. 이 데이터셋은 도메인 특화 RAG 시스템들의 성능을 비교평가하기 위한 목적으로 구축된 것으로, 여기서는 그 중 정확도(accuracy) 지표를 사용하여 시스템의 정답률을 측정하였다.
우리는 다음과 같은 다양한 검색기와 LLM 조합에 대해 실험을 수행하였다:
1)검색 알고리즘: (a) BM25(키워드 기반, Lucene 구현), (b) Contriever(범용 사전학습 임베딩, 차원 768, 110M 파라미터), (c) SPECTER(논문 도메인 임베딩, 110M 파라미터), (d) StructCPT(제안 방법, 110M 파라미터). 각 검색기는 동일한 StructCorpus 지식베이스에 대해 질의당 상위 32개의 스니펫을 검색하였다. 추가로 검색 미적용 케이스로서 LLM 자체만으로 chain-of-thought 추론을 수행하는 CoT baseline도 포함하였다.
2)생성 모델(LLM): OpenAI GPT-4o(2024) API를 이용하여 답변을 생성하였다. GPT-4o는 현존 최고 성능의 상용 LLM은 아니지만 2025년 현 시점 API로 가장 활발하게 사용되는 모델이며, 주어진 지식자료를 활용한 답변 생성에 강점이 있고 저렴하다. 비교를 위해 사전학습 지식만으로 답하는 GPT-4o(CoT 프롬프트만 제공)를 기준선으로 삼고, 검색기를 통해 추가 정보를 제공하는 RAG 설정에서 성능 향상을 관찰하였다(참고로 벤치마크 개발 과정에서는 공개모델 Llama 계열과 자체 개발 LLM (MAGI) 등도 평가되었으나, 본 연구에서는 검색기의 상대적 효과에 집중하기 위해 단일 생성기를 사용하였다.
각 실험에서 검색기로부터 얻은 상위 스니펫 32개 중 상위 25개를 LLM 입력에 첨부하였다. 이는 사전 실험을 통해 검색 결과 25개 정도가 답변 정확도 향상에 충분하면서도 문맥 부담을 과도하게 늘리지 않는 적정치였기 때문이다. LLM에는 질의와 함께 검색 스니펫들이 제공되었고, 이후 답변 생성은 temperature = 0.3(결정적 출력 유도) 및 chain-of-thought 유도 프롬프트를 적용하여 일관된 추론을 유도하였다. 최종 생성된 답변이 벤치마크의 정답과 일치하면 정답 처리하여 정확도를 계산하였다.
4.2 결과 및 비교 분석
Table 1은 다양한 지식베이스 구성과 검색기 조합에 따른 QA 정확도를 요약한 것이다. StructCorpus 통합 코퍼스를 사용하고 제안하는 StructCPT 검색기를 적용한 구성이 전체 평균 89.09%의 정확도로 가장 뛰어난 성능을 달성하였다. 이는 검색 미적용(CoT만 사용) 대비 약 3.87%p 높은 수치이며, 구조공학 RAG 시스템의 성능을 크게 향상시킴을 보여준다. 다른 검색기들을 적용한 경우에도 대체로 모든 과업에서 비검색 대비 정확도 개선이 관찰되었다. Contriever와 SPECTER를 사용한 경우 84~85% 대의 비교적 높은 정확도를 보였으나, 구조 분야 지식로 특화된 StructCPT보다는 다소 낮았다. 흥미롭게도 전통적 BM25 모델은 단순한 단어 매칭에 불과함에도 불구하고, 특정 영역(특히 설계기준 관련 질의)에서 안정적인 성능을 나타냈다. 예를 들어 예/아니오 형태로 국내 기준 충족 여부를 묻는 StructCase-Y/N 과업의 경우, 정확한 코드 조항 문구가 질의에 포함되므로 BM25도 높은 재현율을 보였다. 그럼에도 전반적으로는 StructCPT가 가장 우수한 검색 성능을 발휘하였으며, 특히 통합 코퍼스와 결합될 때 90%에 육박하는 정확도를 기록하여 다른 조합들을 앞질렀다
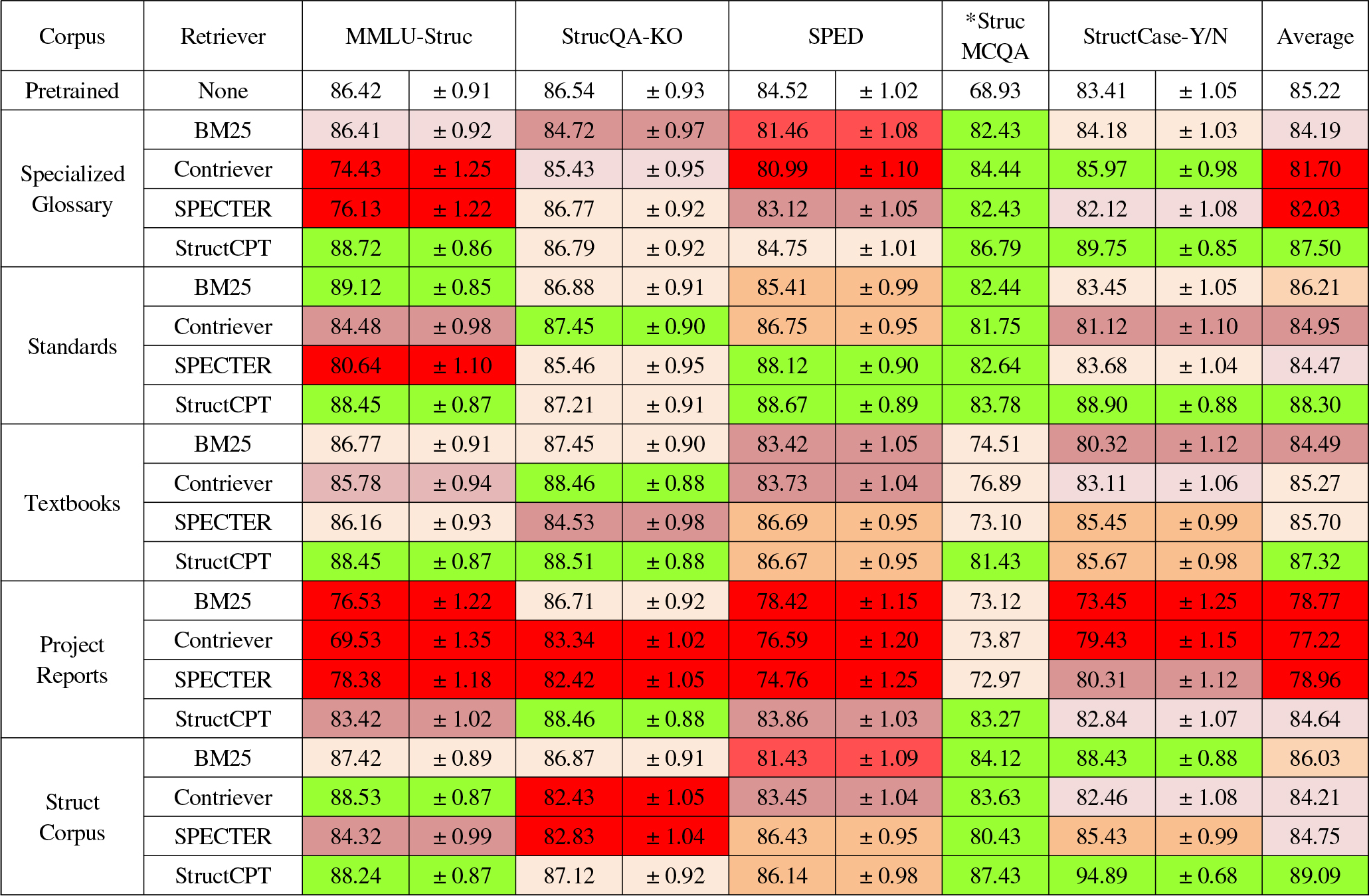
Table 1의 상세 결과를 살펴보면, 지식 소스별로 특정 과업에 두드러진 효과가 나타나는 것을 볼 수 있다. 예를 들어 교과서 코퍼스만 사용한 경우 이론적 배경 지식이 중요한 Struct QA-KO 과업에서 88.46%의 높은 정확도를 보여 해당 유형의 질의에 효과적이었다. 반면 설계기준 문서만 사용한 경우 구조성능 평가 및 설계 관련 과업(SPED, 88.67%)에서 가장 큰 기여를 하였다. 이처럼 질문의 성격에 따라 적합한 정보 출처가 존재하며, 통합 코퍼스는 다양한 출처로부터 고르게 정보를 제공함으로써 모든 과업에 안정적으로 대응하는 것으로 나타났다.
검색기 알고리즘의 영향도 유의미하였다. StructCPT는 거의 모든 분야 과업에서 가장 높은 정확도를 보였으며, 특히 구조기준 준수 여부(StructCase-Y/N) 문제에서는 94.89%의 정답률로 두드러졌다. 이는 해당 과업이 국내 설계 기준 조항을 정확히 찾아 적용하는 능력을 평가하는데, StructCPT가 다른 검색기보다 관련 조항을 잘 찾아내었음을 의미한다. Contriever와 SPECTER도 상당히 높은 정확도를 보였지만, 약어 처리나 한글 맥락이 필요한 경우 성능 저하가 관찰되었다. BM25는 평균 성능은 낮았지만, 간단 명료한 키워드 질의(예: 특정 공식명)에서는 임베딩 기법 못지않은 결과를 내기도 했다. 전반적으로 전문 지식에 특화된 임베딩 모델의 우수성과 다양한 정보원의 균형 있는 활용이 RAG 성능 향상에 중요함을 확인할 수 있었다.
제안한 StructCPT 검색기는 기존 방법들과의 정량적 지표 비교에서 두드러진 성능 우위를 보였다. Table 2의 결과에 따르면 StructCPT는 BM25, Contriever, SPECTER 대비 Recall@10, MRR, Precision@10 모든 항목에서 최고 값을 기록하였다. 구체적으로 StructCPT의 Recall@10은 약 85% 수준으로, 학술 문헌 기반 임베딩인 SPECTER의 약 73% 대비 12%p 이상 높았다. 이와 함께 MRR과 Precision@10도 각각 SPECTER 대비 0.08 및 0.09 절대치로 향상되어, 정답 문서를 최상위에 배치하는 비율뿐 아니라 사용자가 원하는 정보를 신속히 찾는 능력(MRR)과 반환 결과의 전반적 정확성(Precision)까지 향상되었음을 보여준다. 이러한 결과는 도메인 특화 임베딩을 통해 구조공학 질의에 대한 의미적 연관성을 효과적으로 학습한 덕분으로 판단된다. 실제로 StructCPT(MAXIM)은 구조공학 말뭉치를 활용한 대조학습으로 일반 학습모델이 놓치기 쉬운 전문 용어 및 문맥 정보를 포착하여, 전 영역에 걸쳐 고른 성능 개선을 이루었다(Contriever 및 SPECTER 등 범용 모델은 평균 80% 이상의 Recall@10을 보였으나 StructCPT만큼의 일관된 성능은 내지 못하였다.
Table 2.
Performance comparison results
| Retriever Model | Recall@10 | MRR | Precision@10 |
| BM25 | 65.4% | 0.52 | 0.45 |
| Contriever | 71.8% | 0.58 | 0.49 |
| SPECTER | 73.2% | 0.60 | 0.52 |
| StructCPT (MAXIM) | 85.3% | 0.68 | 0.61 |
Fig. 3은 구조 전문 용어(Terminology), 코드 준수(Code Compliance), 실무 사례(Practical Case) 등 질의 유형별로 BM25, Contriever, SPECTER, StructCPT+MAXIM 모델의 Recall@10 (%) 성능을 비교한 그래프이다. 모든 질의 범주에서 StructCPT가 가장 높은 재현율을 기록하였으며, 특히 StructCPT 은 전 질의 유형에서 안정적으로 80% 이상의 Recall@10을 달성하여 경쟁 모델들을 상회하였다. 반면 BM25는 표준 코드 기반 질의에서는 선전하였으나 용어 정의나 복잡한 사례 질의에서는 한계가 드러났고, Contriever와 SPECTER 역시 전문 용어 처리나 문맥 추론 면에서 StructCPT 대비 성능이 열세였다. 이는 다양한 질의 유형에 고르게 대응하기 위해서는 구조공학 지식에 특화된 임베딩 학습이 필수적임을 시사한다. 본 연구에서 구축한 SAFE 도메인 지식베이스와 MAXIM 대조학습 기법이 이러한 성능 향상의 기반을 제공하였으며, 구조공학용 말뭉치로 학습된 StructCPT 모델이 범용 모델 대비 월등한 검색 품질을 보여준다.
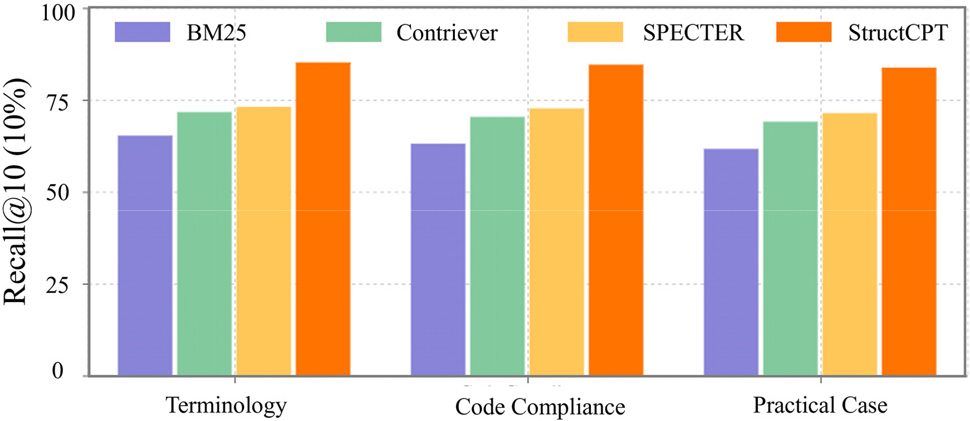
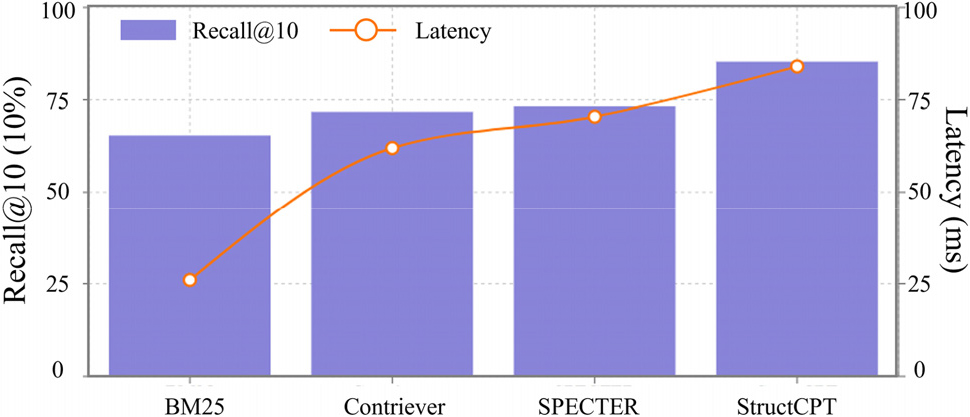
Fig. 4는 검색 스니펫 개수 k를 증가시킬 때 문서 Recall@10 (%)과 평균 검색 지연시간(ms)의 변화를 나타낸 그래프이다. 스니펫 수를 늘릴수록 관련 문서가 검색될 확률이 높아져 Recall이 향상되지만, 동시에 처리 지연이 선형적으로 증가하는 상충 관계가 관찰된다. k = 2에서 k = 32까지 Recall은 급격히 향상되어 약 90%에 근접하나, 32개 이후에는 증가 폭이 미미하였다. 반면 응답 지연시간은 k에 비례하여 늘어나 k = 128에서 초기 대비 약 4배에 이르렀다. 결국 약 32개 전후에서 성능과 속도 간 최적 균형점이 형성되는 것으로 나타나며, 이는 이전 연구에서 보고된 바와 유사한 추세이다. 본 실험에서도 32개 스니펫 구성의 StructCPT+GPT-4o조합이 종합 정확도 면에서 최상 성능을 보이면서도 추가 지연을 최소화하여, 실무 활용 관점에서 효율성과 효과성의 균형을 만족시킴을 확인하였다. 한편 StructCPT 적용 RAG 모델은 사전 지식만으로 답변하는 연쇄적 사고(CoT) 방식 대비 모든 과업에서 큰 성능 이득을 보였다. 예를 들어, StructMCQA 과업에서 RAG 적용 시 CoT 대비 정확도 10%p 이상 상승하여 복잡한 구조공학 문제에 외부 지식 제공이 주는 이점을 입증하였다. 이는 SAFE DB의 풍부한 도메인 지식과 MAXIM 기반 임베딩이 결합되어, LLM의 추론 과정에서 환각(hallucination)을 줄이고 답변 신뢰도를 높인 결과로 해석된다(Ji et al., 2023).
비록 StructCPT 기반 검색 성능이 전반적으로 우수하지만, 여전히 일부 한계 사례들이 존재한다. Table 3은 대표적인 에러 사례를 추려 정리한 것이다. 여기에는 최신 개정 코드 정보 부족, 희귀 전문용어 처리 한계, 멀티모달 문맥 미반영 등 구조공학 도메인 특성에 기인하는 오류 사례들이 포함되어 있으며, 각 사례별 원인과 향후 개선 방향을 함께 제시하였다.
Table 3.
Error analysis and improvement strategies for structCPT retrieval system
위의 사례들은 SAFE 지식베이스의 커버리지와 검색 모듈의 한계에 기인한 것으로 시스템 성능을 더욱 향상시키기 위한 향후 보완 방향을 시사한다. 예를 들어 최신 건축기준 개정사항에 대한 데이터는 정기적으로 갱신하여 포함하고, 새로운 공법이나 재료에 대한 정보를 지속적으로 확충해야 한다. 또한 구조설계 질의에서는 도면 이미지나 사진 등 멀티모달 자료의 활용이 중요하므로, 시각정보 메타데이터를 연계한 검색 고도화가 필요하다. 이러한 개선 작업을 추진한다면, 본 연구의 StructCPT 기반 RAG 시스템은 구조공학 분야에서 더욱 신뢰도 높은 지식 탐색 도구로 자리매김할 수 있을 것이다.
4.3 시스템 효율성과 적용 가능성
StructCPT 기반 RAG 시스템은 성능뿐 아니라 효율성 측면에서도 실제 적용에 유리하도록 설계되었다. 검색기의 온라인 추론 지연시간은 벡터 검색과 교차 재순위 단계를 합쳐 질의당 수백 밀리초 수준이다. 벡터 검색은 Approximate Nearest Neighbor 알고리즘(Faiss 라이브러리 활용)으로 최적화되어 0.1초 이내에 상위 후보를 반환하며, 이후 25개 내외 문서에 대한 교차 인코딩 재순위도 병렬화하여 약 0.2초 내에 수행된다. 따라서 전체 검색 소요시간은 ~0.3초로, LLM 생성에 드는 수 초에 비하면 무시할 수 있는 수준이다. 반면 BM25의 경우, 질의어가 매우 흔한 단어일 때 대량의 문서 스캔이 발생하거나, 한국어 형태소 분석 등의 전처리에 시간이 걸릴 수 있어 일관된 실시간 응답을 보장하기 어렵다. 이 점에서도 임베딩 기반 StructCPT의 장점이 있다. 메모리 사용 면에서도 StructCPT는 대용량 LLM 대비 경량이다. 쌍변환기 모델 자체는 약 1.1억 파라미터로 크기가 수백 MB 수준이며, 37만7천여 코퍼스 문서 임베딩(차원 768, FP16 기준)도 약 1.1GB 정도로 메모리에 적재 가능하다. 이는 최신 LLM(예: GPT-3.5 1750억 파라미터)의 수십 GB 메모리 요구량과 비교하면 매우 작다. 즉, 본 시스템의 검색 부분은 일반 서버 한 대에서도 충분히 구동될 수 있고, 엔진을 지속적으로 서비스하는 데 큰 부담이 없다. 지식베이스의 규모를 늘릴 경우 임베딩 저장 공간은 선형적으로 증가하지만, 수백만 문서 수준까지는 수 GB~수십 GB 내로 관리 가능하여 현실적인 한계 내에 있다. 또한 StructCPT는 정적 지식베이스에 대해 미리 임베딩과 인덱스를 구축해두므로, 검색 시에는 질의 인코딩만 수행하면 된다. 이는 매 질의마다 전체 코퍼스를 다시 스캔하거나 복잡한 연산을 하지 않으므로 서버 부하가 낮고 병렬 처리에 유리하다. 결과적으로 제안 시스템은 전문 분야에 특화되면서도 실시간 상용 서비스에 견딜만한 성능과 자원 활용 효율을 보여준다. StructCPT의 실제 적용 가능성은 상당히 높다고 판단된다. 우선, 본 연구의 실험에서 구조공학 QA에 대해 89% 이상의 높은 정답 정확도를 달성한 것은, 실제 현업 엔지니어의 질의응답 보조에 사용할 만한 수준임을 시사한다. 특히 한국 건축구조기준이나 내진설계 가이드와 같이 안전 관련 질의에 대해서 90%를 넘는 정답률을 보인 것은, 구조 설계검토, 기술자 교육 등에서 유용하게 활용될 수 있음을 의미한다. 예를 들어 구조기술사 교육 현장에서 수강생이 “철근콘크리트 기둥 축력-휨 상관도에서 축력비 증분이 단면해석에 미치는 영향은?”과 같은 질문을 하면, StructCPT 검색기는 관련 교과서 내용과 설계기준 해설을 찾아 제시하고 LLM이 이를 근거로 상세한 설명을 생성해줄 수 있다. 이는 일종의 도메인 전문가 수준의 Q&A 어시스턴트 역할을 수행하여, 사용자의 학습 곡선을 높이고 오류를 줄이는 데 기여할 수 있다. 또한 구조설계 실무에서 코드 컴플라이언스를 신속히 확인하는 도구로 활용 가능하다. 엔지니어가 특정 설계 상황에서 기준 충족 여부를 묻는다면, 시스템이 해당 기준 조항과 판례를 찾아주어 빠르게 검토를 도울 수 있다. 이러한 활용은 구조설계 검토 프로세스의 효율화와 안전성 향상 모두에 긍정적인 영향을 줄 것으로 기대된다. 물론 실제 적용을 위해서는 추가적인 안정성 검증과 사용성 개선이 필요하다. 예를 들어, LLM 생성 답변이 여전히 불확실성을 갖는 경우가 있으므로, 중요한 결정에는 인간 전문가의 검토가 병행되어야 한다. 또한 현재는 텍스트 위주의 정보 검색이지만, 구조 도면이나 도식 등 비정형 데이터에 대한 질의에는 추가 개발이 필요하다. 그럼에도 본 연구의 StructCPT 시스템은 기술적 검증을 통해 실효성을 보인 단계이므로 시제품 수준의 구현을 거쳐 충분히 현장에 투입할 수 있는 수준이라고 볼 수 있다.
5. 결론 및 향후 연구
본 논문에서는 한국 건축구조공학 분야에 특화된 RAG 시스템 StructCPT를 제안하고, 그 설계 원리와 성능을 학술적으로 고찰하였다. StructCPT는 구조공학 도메인 전용으로 구축된 대규모 지식베이스(StructCorpus)와 대조학습 기반의 MAXIM 임베딩 검색 기법을 핵심으로 한다. 제안 시스템은 질의응답 벤치마크 실험에서 기존의 일반 LLM 대비 약 4%p 향상된 약 89%의 정답 정확도를 기록하였고, 특히 한국형 구조설계 기준 문의에 뛰어난 성능을 보였다. 또한 BM25, Contriever, SPECTER 등 기존 검색기와 비교하여 전반적으로 우수한 결과를 달성함으로써, 도메인 특화 검색기의 효과성을 입증하였다. Struct CPT의 두 단계 검색 구조(임베딩 초기검색 + 교차 재순위)는 실시간 응답에 충분한 속도와 높은 정밀도를 양립시켰으며, 임베딩 모델 및 인덱스의 경량화로 시스템 자원 소모를 최소화하였다. 이러한 성능과 효율을 바탕으로, StructCPT는 구조공학 지식 기반의 AI 의사결정 지원 도구로서 실제 적용 가능성이 높음을 보였다. 이는 구조 안전과 직결되는 분야에서 LLM 기술의 활용을 한 단계 진전시켰다는 점에서 학술적, 실용적 의의가 크다.
향후 연구로는 멀티모달 정보 및 지식그래프와의 통합을 추진하고자 한다. 현재 StructCPT는 텍스트 형태의 문서 지식에 주로 의존하지만, 구조공학에서는 도면 이미지, 구조 해석 모델, 시공 사진 등 시각 정보의 중요성이 크다. 따라서 향후 이미지/도면까지 검색 가능한 멀티모달 RAG로 확장한다면 사용자는 구조 디테일 그림이나 건물 손상 사진을 질의에 포함시켜 더욱 풍부한 정보를 얻을 수 있을 것이다. 최근 멀티모달 RAG에 대한 연구들도 진행되고 있어(Abootorabi et al., 2025), 이미지와 텍스트 임베딩을 공동 학습하거나, Vision-Language 모델과 연계하는 등의 기법을 적용할 수 있다. 또한 구조공학 지식그래프를 구축하고 이를 검색에 활용하는 방안도 고려된다. 예를 들어 구조 부재-재료-공법 등의 관계망을 데이터베이스화하여, 검색기가 단순 문서 검색을 넘어서 지식그래프의 추론 경로를 활용한다면 더 높은 수준의 질문에도 답변할 수 있을 것이다. 최근 GraphRAG와 같이 지식그래프를 RAG에 통합하려는 시도가 보고되고 있으며(Han et al., 2025), 이러한 방법을 구조공학 도메인에 맞게 적용하면 복잡한 규정 간 상충관계나 설계 변수들 간의 관계까지도 효과적으로 다룰 수 있을 것으로 기대된다.
마지막으로 생성기(LLM)의 도메인 적응도 향후 과제이다. 본 연구에서는 범용 LLM에 검색으로 정보를 공급하는 접근을 취했으나, 장기적으로는 구조공학 데이터로 LLM 자체를 파인튜닝하거나, RAG 환경에서 학습(finetailoring)하는 RAFT 기법(Zhang et al., 2024) 등의 도입도 고려된다. 이를 통해 답변의 전문성 및 문장 표현을 더욱 향상시키고, 사용자 질의 의도를 정확히 파악하는 대화형 에이전트로 발전시킬 수 있을 것이다.
요약하면 StructCPT는 한국 건축구조공학 분야에 최적화된 검색-증강 생성 시스템으로서 학술적으로 새로운 시도와 성능 개선을 보여주었다. 본 연구를 통해 도메인 특화 AI 비서의 가능성을 확인한 만큼, 향후 멀티모달 통합, 지식그래프 연계, LLM 미세조정 등 후속 연구를 지속하여 안전하고 신뢰할 수 있는 구조공학 AI 솔루션으로 완성도를 높이고자 한다.
본 연구에서 사용된 데이터 및 검색기 모델은 다음 GitHub 링크에서 확인할 수 있다(https://github.com/m-ill/StructCPT).
