

1. 서 론
2. 본 론
2.1 강화학습
2.2 Deep Q-learning
2.3 RC라멘교의 특징
2.4 교량설계프로세스
2.5 강화학습 알고리즘 – 외부 해석프로그램 간 인터페이스 시스템
3. 결 론
1. 서 론
현재 교량과 같은 토목구조물의 설계과정은 노선계획에 따른 형식 선정 후 1차 설계를 수행하고, 설계기준에 부합하는 최적 설계파라미터 산정 시까지 반복적인 과정을 설계자가 직접 수행한다. 특히 철도 교량의 경우 궤도-교량 상호작용, 주행 안정성, 승차감 등의 특화된 검토가 추가로 필요하나, 설계 완료 단계에서 부가적인 검토를 통해 단순히 결과물의 기준 만족 여부만을 확인하고 있는 실정이다. 이와 같은 반복적인 설계 과정은 건설 설계에 소요되는 시간을 연장시키는 원인이 되며, 보다 수준 높은 설계에 투입되어야 하는 고급 엔지니어링 인력을 기계적인 단순 반복 작업에 소모하는 문제를 야기하고 있다.
설계절차는 크게 설계환경 인식, 단면가정, 구조해석, 결과검토로 구분할 수 있으며, 이와 같은 각각의 개별적인 작업과정들로 이루어진 진행절차를 거쳐 반복수행 및 결과피드백을 통해 구조적인 성능을 만족하며 공사비용의 최적값을 탐색하는 통합 과정이다. 강화학습 기법은 이러한 최적값 탐색에 효과적인 기법 중 하나로 불확실성을 포함하는 최적제어 문제에 대해 주어진 모델과 상태로부터 보상을 최대화할 수 있는 전략을 찾는 방법이다. 모델을 수학적으로 명확하게 정의할 수 있을 경우 이러한 최적제어 기법들이 매우 효과적이지만 교량설계와 같이 설계절차 중 반복하여 이루어지는 단면가정, 구조모델링 및 구조해석 절차 등 변화가 여러 전후 단계에 영향을 미쳐 매끄러운 정의가 힘든 경우 적용에 어려움이 있다. 한편 최근 AI분야에서 활발하게 적용되고 있는 Deep Learning의 경우 모델을 직접 정의할 필요없이 입력값과 출력값과의 관계를 표현할 수 있는 신경망을 효과적으로 생성할 수 있으나, 충분한 양의 사전학습데이터를 필요로 하며 특히 철도 교량과 같이 설계자료가 매우 적은 경우 적용에 어려움이 있다.
Deep Q-leaning 알고리즘은 위와 같은 문제들에 대처할 수 있는 알고리즘으로 강화학습 알고리즘과 Deep Learning 알고리즘이 각각 가지고 있는 문제들을 해결하기 위한 수단으로서 주어진 모델을 강화학습하는 대신 신경망을 강화학습하는 기법이다. 본 연구에서는 Deep Q-learning 알고리즘을 교량설계문제에 적용하여 사전학습데이터 없이 반복수행 가능한 설계모델을 AI가 학습하도록 하였다.
한편, AI알고리즘 적용을 위해서는 앞서 언급한 바와 같이 충분한 양의 학습데이터 또는 반복 수행이 가능한 모델이 요구된다. 설계모델의 경우 구조해석 절차는 대부분 설계엔지니어에 의해 전용프로그램을 사용하여 수동으로 진행하는데, 이는 해석과정 중 구조물의 기하학적 형상, 재료적 특성 및 해석조건 등은 설계엔지니어의 주관적 판단에 따라 결정되며 일반화되기 어려운 것으로 여겨졌기 때문이다. 이러한 외부의 전용프로그램에 의해 진행되는 절차들은 개별적으로는 파라메트릭 모델링 등의 자동화가 진행되고 있으나 통합적인 자동화는 미비한 실정이며 강화학습과 신경망 알고리즘과 같은 AI를 적용하기 위해서는 전 과정의 자동화 시스템이 필요하다(Park et al., 2008).
최근 건설 분야에서는 이러한 설계 분야로의 AI 적용을 위한 연구가 활발히 진행되고 있다(Kang et al., 2017). 건축 분야에서는 딥러닝의 경우 2차원 모델로부터 3차원 모델의 자동 작성(Gu et al., 2018), 트러스 구조물의 정적, 동적 거동 예측(Sim et al., 2018) 등의 연구가 수행되었고, 강화학습의 경우 Deep Q-learning을 활용한 건물 에너지의 최적 상태 유지(An, 2018), 공간배치안 생성과 철골구조물의 대안부재선정 등에 활용된 바 있다(MOLIT, 2019). 토목 분야에서는 교량의 경우 자동설계프로그램(Noh, 2002), 구조성능 최적화 기술(Park, 2006) 등이 제안되었으나 이는 일부 단순구조물에 한정되어 있으며, 통합적인 설계절차가 아닌 구조해석 부분 등 일부 과정만을 최적화하는 한계가 있다.
이 연구에서는 이러한 문제를 해결하기 위한 한 방안으로서 강화학습 알고리즘과 외부 해석프로그램을 외부에서 자동으로 제어할 수 있는 인터페이스 프로그램을 작성하여 반복수행 중 입출력 데이터가 상호교환되어 강화학습에서 필요한 피드백과정 및 수정된 입력값을 새로운 해석모델에 상시 반영할 수 있는 시스템을 구축하였다.
2. 본 론
2.1 강화학습
강화학습은 기계학습의 한 분야로서 주어진 환경(environment)에서 에이전트(agent)가 현재의 상태(state)를 파악하여 선택 가능한 행동(action)들 중 누적보상(cumulative reward)을 최대화하는 행동을 선택하는 정책(policy)을 찾는 방법이다(Park et al., 2019)(Fig. 1).
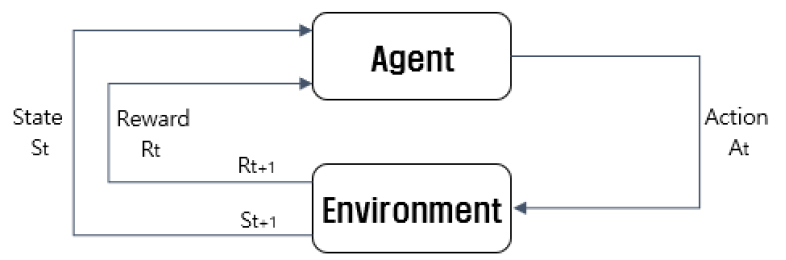
강화학습은 근사동적 계획법이다. 강화학습에서 환경은 일반적으로 마르코프 결정과정(MDP, Markov Decision Process)으로 공식화된다. 정확한 수학적 모형을 가지는 고전적 동적 계획법과 달리 강화학습은 정확한 방법이 실행 불가능한 대규모의 MDP를 대상으로 할 수 있어 시스템에 매우 많은 수의 상태가 있고 복잡한 확률적 구조를 가질 때 적합한 기법이다. MDP는 상태의 변화가 오로지 현재의 상태에만 의존하며 이전 경로(trajectory)를 무시할 수 있는 특징을 가진다. MDP는 다음과 같이 표현된다.
여기서, 는 상태전이확률행렬이고 는 상태집합이다. 상태전이확률 는 상태 에서 다음 상태로 전이하는 확률을 의미하며, 다음과 같이 정의된다.
보상함수은 다음과 같이 정의된다.
강화학습은 에이전트와 환경의 상호작용을 통해 보상을 확인하며 정책(Policy, )을 발전시킨다.
식 (4)는 결정적(deterministic) 정책이며, 식 (5)는 확률적(stochastic) 정책이다. 취한 행동이 결과를 결정할 경우 결정적 정책이 사용되며 환경에 불확실성이 있을 때는 확률적 정책을 사용한다.
가치함수는 정책의 성능을 평가하는 함수이며 다음과 같이 표현된다.
가치함수는 최적 정책을 찾기 위해 사용되며 보상(Reward)이 현재 행동으로 얻게 되는 실제 값인 반면, 가치(Value)는 반환(Return)에 대한 추정값이다. 식 (6)은 상태 가치함수로 정책 에서의 상태 의 가치를 나타내고, 식 (7)은 행동 가치함수로 정책 에서의 행동 의 가치를 나타낸다. 여기서, 는 기댓값을 의미한다.
2.2 Deep Q-learning
고전적인 강화학습 알고리즘은 사전학습데이터 없이 주어진 모델의 반복을 통해 최적 해를 탐색할 수 있다는 장점이 있으나, 마르코프 성질을 전제로 하므로 전후 데이터간 연관성(Correlation)이 높은 경우에 적합하다는 전제가 존재한다. 반면 Deep Learning의 경우 데이터 샘플 간 관계가 서로 독립적일 때에도 적용 가능한 기법이지만, Deep Learning은 입력-출력 데이터간 관계가 정의된 충분한 양의 사전 학습데이터가 필요하여 특히 토목구조물 설계와 같이 학습에 필요한 충분한 양의 사전 데이터를 확보하기 어려운 경우 활용하기 힘들다는 단점이 있다.
위와 같은 문제를 해결하기 위한 방안으로서 본 논문에서는 설계상 최적값을 탐색을 위해 강화학습 알고리즘 중 하나인 Deep Q-learning을 적용하였다. Deep Q-learning 알고리즘은 구글 딥마인드가 개발한 알고리즘으로 기존 강화학습 이론 중 하나인 Q-learning 알고리즘에 experience replay와 target network 개념을 사용하여 심층 신경망으로 Q함수를 구성해 강화학습을 수행하는 기법이다. Deep Q-learning은 기존 Q-learning에 비해 각 단계마다의 경험이 가중치 업데이트에 사용되어 데이터 효율성이 높으며 샘플과 샘플 사이의 강한 상관관계에 의해 발생하는 학습의 비효율성을 완화하고자 샘플 사이를 무작위화하여 연속 샘플을 학습 직접 학습할 수 있게끔 한다(Mnih et al., 2013). 또한, 기존 on-policy에서 매개변수가 학습된 다음 데이터 샘플이 결정되는 구조에 의해 발생할 수 있는 feedback loops 및 local minimum 문제에 있어 experience replay를 사용하여 데이터 일부 범위가 지배적이 되는 현상과 파라미터의 발산이나 진동을 피하고 학습을 원활하게 진행할 수 있다는 장점이 있다. Deep Q-learning의 알고리즘은 Fig. 2와 같다.

2.3 RC라멘교의 특징
Fig. 3과 같은 RC라멘교는 PSC교량이나 강박스교량, 거더교량과 달리 폭대비 교량의 길이가 매우 짧은 편이며, 길이나 폭에 비해 높이가 상대적으로 높다는 특징이 있다(Kim and Kwon, 2009). 구조적으로 상부와 하부가 강절되어 있어 전체적인 강성이 높으며 지간 내 휨모멘트를 하부에 분담할 수 있는 특징이 있고, 일체형 구조로 인해 구조해석 및 공사비 산정을 위한 모델링 시 단일형태로 간주한다.
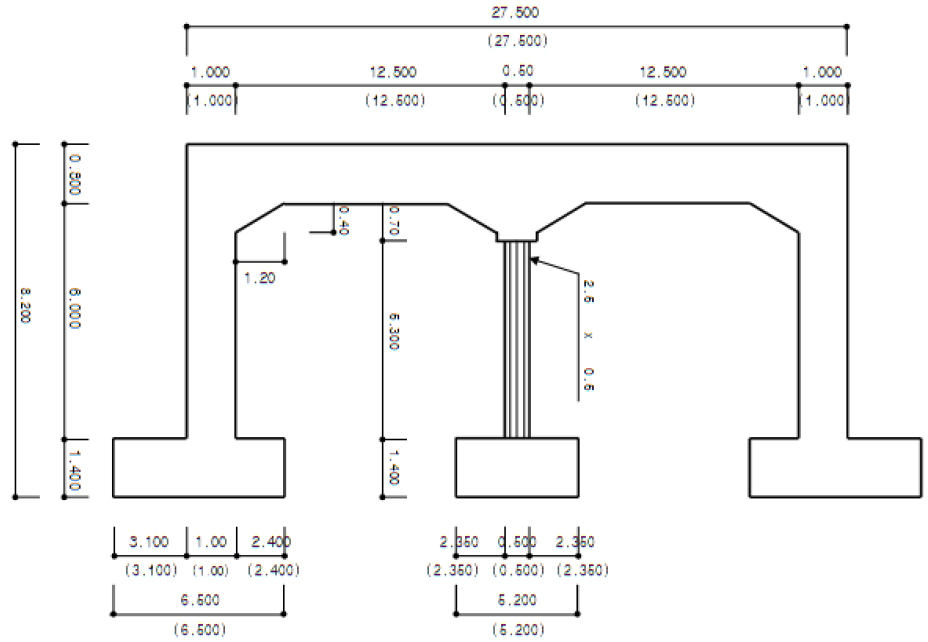
이 연구에서는 철도 교량 중 가장 단순한 형태인 RC 라멘교를 대상으로 선정하였다.
2.4 교량설계프로세스
철도 교량의 경우 도로 교량과 달리 step 3~4에서 궤도 등 선로를 구성하는 시설의 자중이 고려되고, KRL-2012 등 설계 열차 하중이 적용되므로 부재력이 상대적으로 커지는 특징이 있다. 또한 부재 설계단계 이후 동적 해석을 통한 사용성 검토 등이 추가로 수행된다. 본 연구의 분석 대상인 철도 RC라멘교의 경우 Fig. 4과 같은 절차에 의해 설계가 수행되며, 서로 다른 특성을 가진 다양한 파라미터들에 의해 최종검토 결과가 결정된다. 설계스크립트 구현에 있어 이러한 파라미터들 중 초기 입력 혹은 제어 가능한 파라미터들을 input-1~3, variable- 1~2로 정의하였고, 계산 중 보정되는 파라미터를 weight-1~5로 구분하였다.
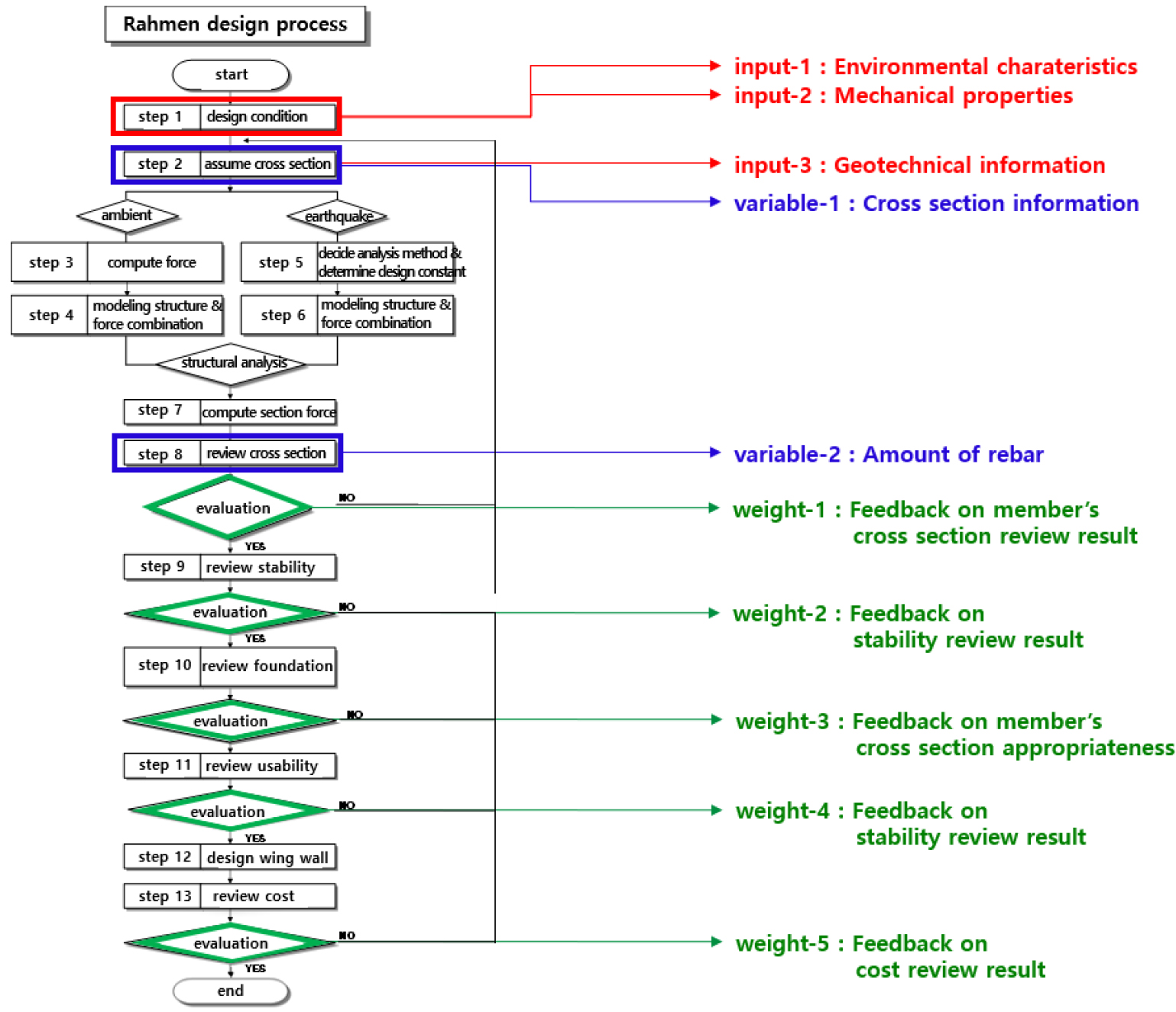
Input은 입력 파라미터를 의미하며 실제 설계에서 초기설계조건으로 주어진 후 변경되는 경우가 거의 없는 요소들이며, input-1은 외부 환경에 의해 결정되는 파라미터, input-2는 구조물의 구조적 특성, 형상 등 구조물의 역학적 특성에 의해 결정되는 파라미터, input-3은 input-1과 유사하나 단면가정 단계에서 입력되는 파라미터이다. Variable은 변동 파라미터로 variable-1은 설계 단면의 부재 치수를 의미하며 구조해석 이전에 사전정의되는 파라미터이고, variable-2는 구조해석 결과에 제약을 받는 상태에서 제어할 수 있는 파라미터이다. weight는 가중치 파라미터로 weight-1은 구조해석 결과 산정된 단면력 결과를 바탕으로 단면 강도의 적정성을 판단하여 계산한 피드백 값이다. 마찬가지로 weight-2는 안정검토에 의한 피드백 값, weight-3은 기초에서 부재단면 적정성의 피드백 값, weight-4는 사용성 검토 결과에 의한 피드백 값이며 weight-5는 모든 단계 완료 후 비용의 적정성을 판단하여 계산된 피드백 값이다. weight-1~5의 피드백은 단면조정으로서 이전단계에 반영되며 variable-1을 주로 제어하여 단면가정 단계를 갱신하게끔 한다. input-1~3, variable-1~2에 해당하는 파라미터들은 Table 1에 기술하였다.
Table 1.
Classification parameters
2.5 강화학습 알고리즘 – 외부 해석프로그램 간 인터페이스 시스템
본 논문에서는 교량설계 프로세스를 수행하기 위한 강화학습 알고리즘 및 외부 해석프로그램 간 인터페이스 환경을 Fig. 5와 같이 구축하였다.
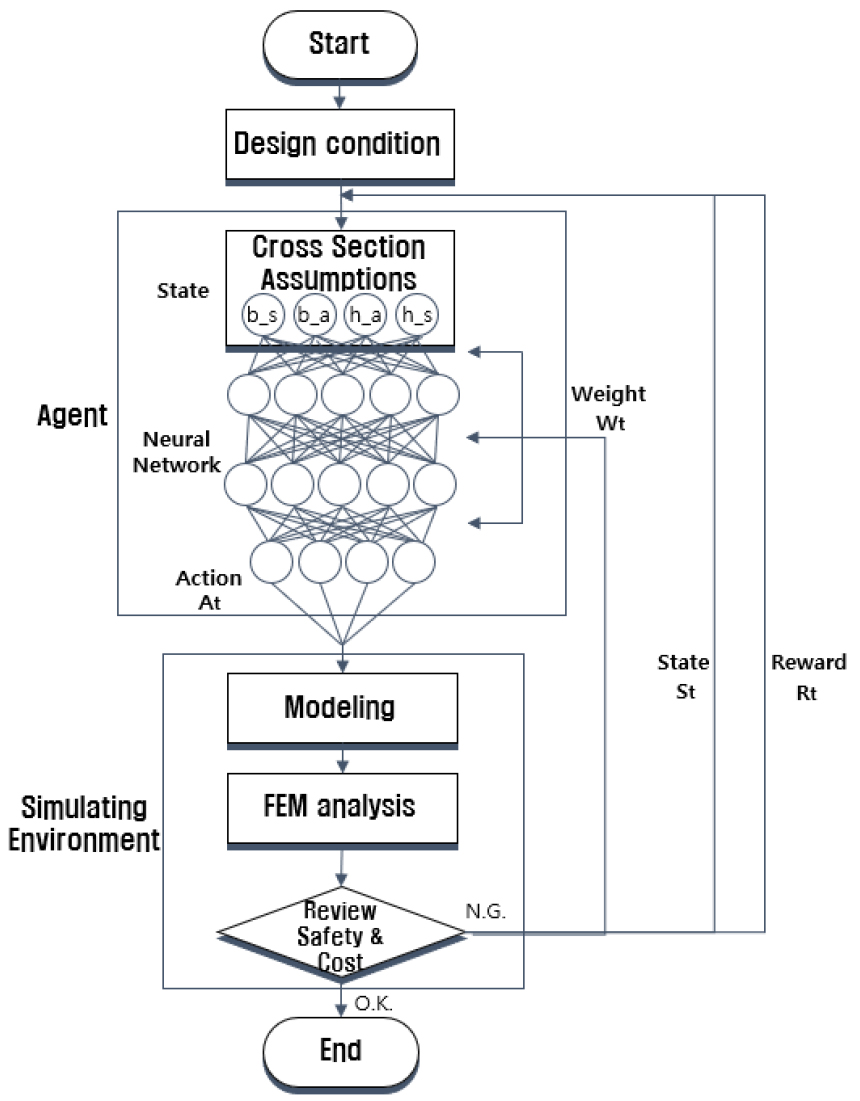
작성된 인터페이스 시스템은 Matlab 언어로 작성되었으며, 스크립트 실행을 통해 Start& Design Condition(초기파라미터 입력단계), Agent(파라미터의 AI 학습 및 결과 반영단계), Simulating Environment(외부 해석프로그램 실행 및 결과 추출단계), End(검토 및 피드백 산정단계)의 총 4단계를 반복 수행한다. 첫 번째 단계인 Start& Design Condition은 2.4절에서 언급한 input-1~3을 정의하는 단계로 설계제약 조건을 정의하는 절차이다. 두 번째 단계인 Agent에서는 Cross Section Assumptions을 통해 2.4절에서 각 단면의 치수에 해당하는 variable-1을 정의한 후 Neural Network 계산을 수행하여 결과로서 Action값을 출력한다. 세 번째 단계인 Simulating Environment는 외부 해석프로그램이 직접적으로 활용되는 단계이다. 이전 출력된 Action값을 반영하여 Modeling을 갱신하고 해석을 수행한 후 Review Safety & Cost 과정에서 단면의 휨, 전단 등에 대한 안전 검토 및 비용 산정을 수행한다. 이 단계에서 인터페이스 시스템은 외부 해석프로그램들에서 제공하고 있는 텍스트형식의 해석 입력 파일을 사전 정의한 규칙에 따라 생성하여 강화학습과 외부 해석프로그램간 연결고리 역할을 수행한다. 또한, 외부 해석프로그램의 해석결과로서 출력된 파일을 읽어들이고 안전 검토 및 비용 산정 수행이 가능하도록 필요한 정보를 추출하는 역할을 담당한다. 검토 결과는 Agent가 기준을 만족하는지 여부를 판단하는데 활용하며, 검토기준을 만족하지 못한 경우 피드백 결과인 을 통해 각각 Cross Section Assumtions와 Neural Network에 반영되고 검토기준을 만족한 경우 네 번째 단계인 End 절차로 진행하여 설계프로세스를 완료한다.
3. 결 론
본 연구에서는 교량설계 프로세스의 AI기반 자동화 시스템을 구축하여 기존 설계 중 반복작업을 대체하고자 강화학습 알고리즘과 외부 해석프로그램을 함께 제어할 수 있는 인터페이스 시스템을 구축하였다. 이를 통하여 사전데이터 확보가 힘들어 Deep Learning 기반 AI 학습이 어려운 철도 교량에 대해서 강화학습 기반 AI 학습 체계를 마련하였다. 강화학습 알고리즘은 모델을 특정할 수 없을지라도 피드백 결과에 의한 추론 결과를 제공함으로써 교량설계 문제와 같이 정식화하기에 복잡한 문제에 적용하기 적절한 알고리즘으로 판단된다. 강화학습 알고리즘-외부 해석프로그램간 인터페이스 시스템의 프로토타입은 가장 단순한 형식 교량 중 하나인 2경간 RC라멘교를 대상으로 제작하였다. 개발된 인터페이스 체계는 향후 최신 AI 및 타 형식의 교량설계간 연계를 위한 기초기술로써 활용될 수 있을 것으로 판단된다.
