

1. 서 론
1.1 연구 배경
1.2 연구 목표
2. 에이전틱 FEA 해석 자동화 시스템의 아키텍처 설계
2.1 Claude Code 및 최신 추론 모델(Claude Opus 4.6) 특성
2.2 멀티 에이전트 시스템 구성과 자기 수정 루프 설계
2.3 Abaqus MCP 서버와 도구 체계
2.4 환각 완화 장치: 논리적 제약 메커니즘 적용
2.5 FEA 자동화 시스템 아키텍처 및 워크플로우
3. FEA 자동화 시스템 검증 사례 연구
3.1 FEA 자동화 시스템 검증: 프롬프트로부터 FEA까지
3.2 환각 완화 장치 검증 실험
3.3 고난도 문제 해결 역량 검증: 풍력 블레이드 사례
3.4 사례 검증 결론 및 한계
4. 결 론
1. 서 론
1.1 연구 배경
최근 대규모 언어모델(Large Language Model, LLM)은 단순한 텍스트 생성을 넘어 공학 문제의 요구사항 분석, 절차 계획, 코드 작성 및 도구 실행과 결과 해석을 하나의 자율적인 워크플로우로 연결하는 ‘에이전틱(Agentic)’ 시스템으로 진화하고 있다. 국내 카이스트에서도 멀티 에이전트(Multi-Agent) 기반의 시뮬레이션 설정부터 코드 생성 및 실행까지 전 과정을 자동화한 연구(Park et al., 2026) 및 사출 성형 공정의 문제 해결을 지원하는 IM-Chat 시스템(Lee et al., 2025)이 제안되는 등 LLM을 활용해 설계, 제조 및 해석 업무에 통합하려는 연구가 활발히 진행 중이다(Heo and Na, 2025; Kim et al., 2025). 해외에서도 관련 기술의 진보를 체계적으로 정리한 조사 연구들이 보고되고 있다(Baker et al., 2025; Mustapha, 2025).
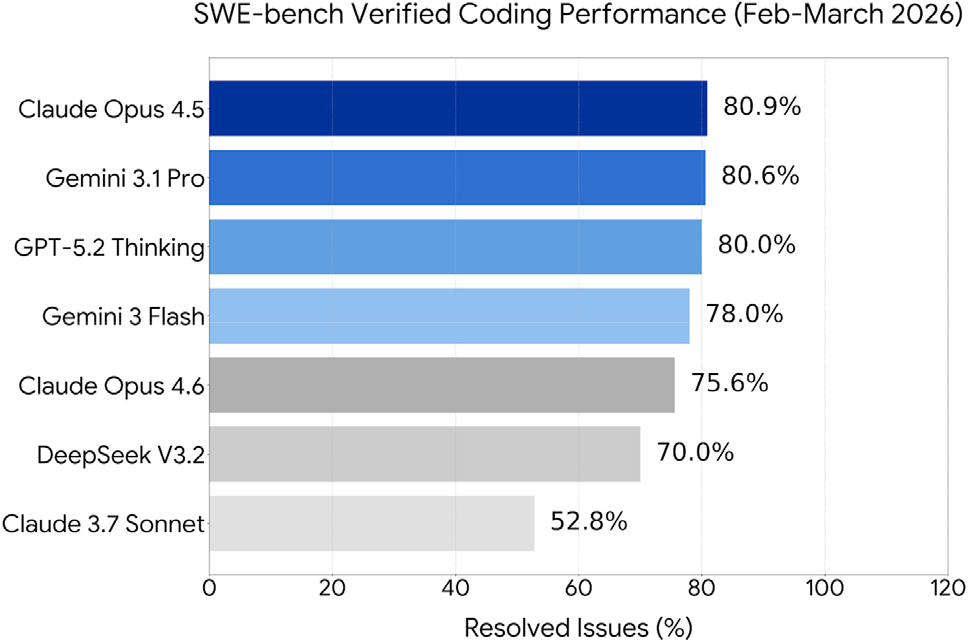
이러한 기술적 확산의 원인은 LLM의 코딩 및 소프트웨어 문제 해결 능력이 획기적으로 향상되었다는 점에 있다. LLM의 복잡한 소프트웨어 이슈 해결 능력을 평가하는 SWE-bench Verified 벤치마크의 2026년 3월 최신 결과에 따르면(SWE-bench, 2026; Zhang et al., 2025), 최상위 모델들은 이제 단순 지식 답변이 아닌 순수 문제 해결 역량만으로 80% 이상의 해결률을 보고하고 있다. Fig. 1에서 확인하듯이, 2025년 11월에 출시된 Claude Opus 4.5가 80.9%의 해결률을 기록하며 업계 최초로 80%의 벽을 돌파하였고, 2026년 2월에 출시(Google, 2026)된 Gemini 3.1 Pro(80.6%)와 강력한 추론 능력을 갖춘 2025년 12월에 출시(OpenAI, 2026)된 GPT-5.2 Thinking(80.0%) 역시 높은 성능을 입증하였다. 이는 LLM이 공학 해석 자동화를 위한 신뢰할 수 있는 코딩 에이전트로 활용될 수 있는 토대가 되었음을 시사한다.
그러나 LLM의 코드 생성 능력은 단편적인 작업 수행에는 유용하게 활용될 수 있으나, 높은 추론 역량이 요구되는 구조 해석과 같은 공학적 도메인에서는 신뢰할 수 있는 수준의 완성도를 확보하는 데 어려움이 있다(Alansari and Luqman, 2025). 이를 극복하기 위해 LLM 에이전트가 오랜 기간 검증된 외부 전문 소프트웨어에 직접 접근하고 이를 제어하기 위한 개방형 표준 규격으로 Model Context Protocol(MCP)이 제시되었다(Anthropic, 2024; Model Context Protocol, 2025).
기존의 유한요소해석(Finite Element Analysis, FEA) 자동화 방식은 해석이 정상적으로 종료되더라도 사용자의 설계 의도와 실제 모델이 불일치하거나, 결과에 잠재적 모델링 오류가 있는 LLM 고유의 환각(Hallucination) 현상이 발생했다. 최근 연구에서는 이러한 환각을 효과적으로 억제하기 위해 추론 과정에 구조적 제약이나 명시적인 논리 규칙을 도입할 것을 강조한다(Huang et al., 2023; Wilberg, 2025).
따라서 단순한 MCP 기반 자동화 시스템을 넘어 LLM의 환각 문제 해결을 위한 시스템적 제어 장치와 자율적 오류 해결 루프를 도입하여 해석 결과의 신뢰성을 확보하고, 더 나아가 경험적 지식 데이터 활용을 통해 동일 유형의 오류 재발을 방지 등 문제해결의 최적화 역량을 확보하는 것이 필요하다.
1.2 연구 목표
본 연구의 목표는 Claude Code 환경에서 최신 추론 모델(Claude Opus 4.6)을 활용하여 Abaqus FEA의 전 과정을 에이전트 주도로 자동화하여 수행하는 에이전틱 자동화 시스템을 구축하고, 해석 결과의 ‘의도 재현성’과 ‘경험 기반 수행 최적화’ 역량을 정량적으로 확보하는 것이다. FEA는 구조 설계 및 성능 검증에서 필수적인 도구이며(Bathe, 1996), 상용 해석기인 Abaqus는 Python 스크립팅 인터페이스를 통해 모델 생성 및 해석의 자동화를 지원한다(Dassault Systèmes, 2018). 특히 Abaqus는 로컬 시스템에서 직접 접근 가능한 Python API를 제공하므로, 해석 소프트웨어의 핵심 기능을 MCP 규격의 도구로 체계화하여 LLM 에이전트와 연동하는 것이 가능하다.
따라서 본 연구는 제안한 시스템이 단순한 스크립트 실행 성공을 넘어 해석 결과의 신뢰성과 자동화 성능 향상을 목표로 하며, 다음과 같은 세 가지 핵심 기여를 제시한다.
1) MCP 기반의 FEA 자동화 파이프라인 구축: LLM 에이전트와 Abaqus를 MCP 규격으로 연동하여, 자연어 기반의 외부 도구 제어 및 결과 데이터 추출 과정을 자동화 시스템으로 구축한다.
2) 환각 완화 장치 및 문서 기반 자기 수정 루프 구현: 입력 파라미터를 정형화하는 환각 완화 장치를 도입하여 모델의 임의 가정을 검증함으로써 의도 재현성을 확보하고, 실행 로그를 진단 문서(Diagnostic Document)로 구조화하여 분석하고, LLM 에이전트가 에러를 스스로 복구하는 자기 수정 루프(Self-correction loop)를 설계한다.
3) 경험 기반 수행 최적화 성능의 정량적 검증 및 실증: 공학 사례 검증을 통해 자기 수정 루프 반복 횟수 감소, 전체 소요 시간 단축, 반복 수행 완료율 확보와 함께 경험적 지식 데이터의 축적과 재사용에 따른 경험 기반 수행 효율 향상을 정량적으로 입증한다.
본 논문의 2장에서는 FEA 자동화 시스템의 아키텍처와 상세 설계를 기술하고, 3장에서는 실제 해석 사례를 통해 시스템 성능부터 환각 완화 장치 및 경험 지식 데이터의 효용성을 정량적으로 검증한다. 마지막 4장 결론에서는 주요 성과와 향후 과제를 제시한다.
2. 에이전틱 FEA 해석 자동화 시스템의 아키텍처 설계
2장에서는 의도 재현성 및 수행 최적화 역량을 갖춘 FEA 자동화 시스템을 구축하기 위한 아키텍처 설계와 기술적 구현 내용을 상세히 다룬다. 세부적으로는 핵심 추론 엔진(2.1), 다중 에이전트 및 자기 수정 루프(2.2), MCP 서버와 도구 체계(2.3), 환각 완화 장치(2.4)의 설계를 다루며, 최종적으로 전체 아키텍처와 7단계 워크플로우(2.5)를 제시한다.
2.1 Claude Code 및 최신 추론 모델(Claude Opus 4.6) 특성
본 연구에서 사용하는 Claude Opus 4.6 모델(Anthropic, 2026)은 복잡한 시스템 제어 및 코드 수정 작업에서 검증된 성능을 제공한다. 이러한 추론 역량은 프롬프트로부터 문제를 구체화하고, FEA 전 과정을 단계별로 계획하고, 상용 툴인 Abaqus를 다루기 위해 필수적인 Abaqus Python API의 정교한 문법 이해를 갖춘 에이전트 모델로 적합하다.
에이전트 실행기 역할의 Claude Code는 MCP 규격을 네이티브로 지원하여, 가용한 MCP 서버를 별도의 미들웨어 없이 호출하고 사용할 수 있다. 또한 에이전트가 작업 수행 과정에서 누적되는 대화 이력을 효율적으로 관리하는 토큰 최적화 기술이 적용되어 있어, 장시간의 워크플로우 수행 시에도 작업 내용을 보존하고 운영 비용을 절감하는 환경을 제공한다.
2.2 멀티 에이전트 시스템 구성과 자기 수정 루프 설계
2.2.1 멀티 에이전트 시스템: 역할 분담
본 시스템은 Fig. 2와 같이 전체 공정을 총괄하는 메인 에이전트(Main Agent)와 특정 작업에 특화된 서브 에이전트(Sub-agent)로 구성된 멀티 에이전트 구조를 가진다. 메인 에이전트는 사용자의 요구사항을 구조화하여 단계별 실행 계획을 수립하고, MCP 도구 호출을 통해 Abaqus 실행 및 결과 확인을 총괄한다. 서브 에이전트는 전처리 스크립트의 생성과 오류 발생 시의 코드 수정을 전담한다. 이러한 역할 분담은 메인 에이전트가 전체적인 해석 흐름과 성공 조건 유지에 집중하게 하며, 상세 코딩 작업은 독립적인 컨텍스트를 가진 서브 에이전트가 수행하게 함으로써 작업 흐름의 오염을 방지하고 복잡한 태스크 수행의 안정성을 높인다.
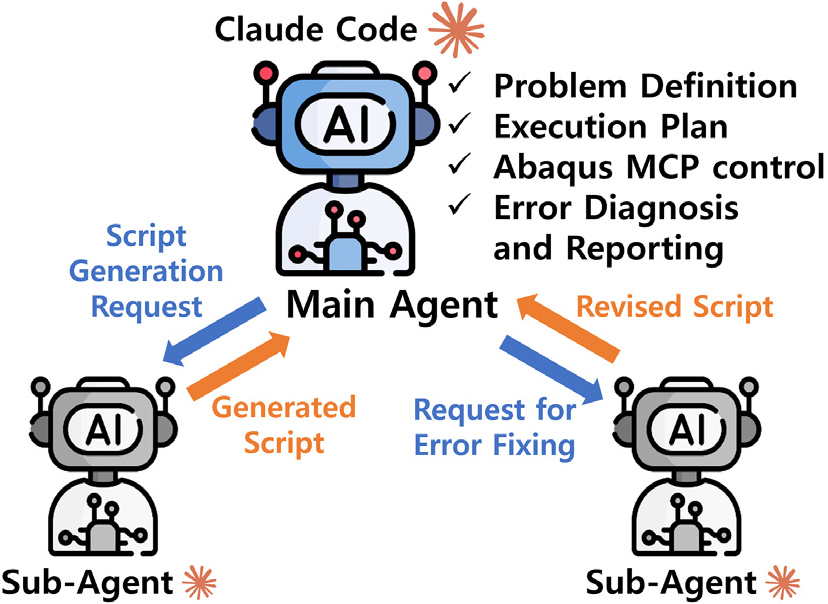
2.2.2 자기 수정 루프: 진단 문서 기반 수정 전략
본 시스템에서는 해석 과정 중 오류가 발생할 경우 메인 에이전트가 이를 확인하고 ‘자기 수정 루프’를 통해 해결하는 구조를 구현하였다. 제안한 오류 수정 메커니즘은 에러 로그와 기존 코드 패턴의 대응만으로 동작하는 것이 아니라, 이름 불일치나 요소 타입 오류와 같은 문제는 로그 기반 패턴 교정으로 해결하고, 형상 생성 방식의 전환이나 요소 연결성 수정과 같은 문제는 FEA 도메인 지식에 기반한 공학적 판단을 통해 교정하는 이중 구조로 이루어져 있다.
Abaqus는 스크립트 구동이나 해석 수행 중 오류가 발생할 경우 .dat 및 .log 파일에 에러 내용을 반환한다. 메인 에이전트는 반환된 오류 정보를 바탕으로, 해당 시점의 오류 원인과 직접적인 수정 계획을 정리한 진단 문서 ERROR_CONTEXT.md를 생성하여 수정 전담 하위 에이전트에게 전달한다. 하위 에이전트는 이 문서를 참조하여 스크립트의 오류 구간을 우선적으로 수정한다.
또한 시스템은 오류 수정 루프가 수행될 때마다 수정 과정을 FIX_HISTORY.md로 기록하고 관리한다. FIX_HISTORY.md에는 기존에 발생한 오류의 유형, 적용된 수정 내용, 수정 결과가 축적되며, 이를 통해 동일하거나 유사한 오류의 재발을 효과적으로 억제한다. 이러한 진단 문서 및 이력 관리 방식은 장문의 로그와 코드가 메모리에 누적되는 것을 방지하여 토큰 사용 효율을 높이고, 반복적인 루프 수행 시에도 모델의 추론 성능이 저하되지 않도록 돕는다.
2.3 Abaqus MCP 서버와 도구 체계
제안한 자동화 시스템에서 메인 에이전트의 Abaqus 제어는 MCP를 통해 구현된다. 구축된 Abaqus MCP 서버는 Python 기반의 FastMCP 프레임워크를 활용하여 제작되었으며, 윈도우 로컬 환경의 특성을 고려하여 MCP 표준 입출력 방식인 stdio 전송(Standard Input/Output Transport) 방식을 채택하였다.
본 연구에서 MCP는 LLM 에이전트가 상용 해석 소프트웨어를 사용할 수 있도록 기능을 도구 단위로 표준화하는 인터페이스로 활용되었다. 일반적인 Python 스크립팅 기반 자동화가 사람이 작성한 절차의 실행에 적합하다면, MCP 기반 구조는 Abaqus의 실행, 상태 점검, 로그 확인, 결과 추출과 같은 기능을 에이전트가 일관된 방식으로 호출하고 조합할 수 있게 한다. 또한 이러한 구조는 새로운 기능의 추가나 타 소프트웨어로의 확장에도 유리한 인터페이스를 제공한다.
개발된 Abaqus MCP 서버는 Table 1과 같은 11가지 핵심 도구로 구성되어 있으며, 기능적 측면에 따라 크게 세 가지 범주로 분류할 수 있다.
1) 프로세스 및 환경 관리(Tool 1-4): Abaqus/CAE GUI와 솔버 프로세스의 실행 상태를 실시간으로 점검하고 제어한다. 특히 소프트웨어 라이선스 문제나 시스템 지연을 에이전트가 스스로 인지하고 대응할 수 있는 환경을 제공한다.
2) 모델링 및 해석 실행(Tool 5-8): 에이전트가 생성한 Python 스크립트 파일을 실행하거나 텍스트 형태의 INP 파일을 통해 해석 작업을 수행한다. 이 과정에서 작업 디렉토리 내의 파일을 관리하고 진행 상황을 모니터링하여 해석의 시작과 종료를 자율적으로 제어한다.
3) 후처리 및 리포트 생성(Tool 9-11): 해석 완료 후 바이너리 형태의 ODB 결과 데이터에서 필요한 필드 값을 추출하여 CSV 등 언어모델이 인지 가능한 텍스트 데이터로 변환한다. 또한 해석 결과를 Abaqus GUI 윈도우에 직접 가시화하거나, 전체 워크플로우 수행 이력을 마크다운 형식의 최종 보고서(WORKFLOW_REPORT.md)로 저장하여 사용자에게 제시한다.
Table 1.
Definition of categories and functions for Abaqus MCP tools
2.4 환각 완화 장치: 논리적 제약 메커니즘 적용
LLM은 비정형 자연어 입력으로부터 누락된 정보를 보완하는 과정에서 임의의 파라미터를 설정하는 환각 문제를 가진다. 이를 극복하고 설계 의도의 재현성을 확보하기 위해 본 연구에서는 에이전트의 추론 과정에 개입하는 ‘논리적 제약 메커니즘(Logical Constraint Mechanism)’ 기반의 환각 완화 장치를 적용하였다.
이 장치는 Claude.md 파일 내에 강력한 시스템 지침 형태로 명시되어, 에이전트가 이를 반드시 따르도록 하는 강제 규약으로 작동한다. 이에 따라 메인 에이전트는 요구사항을 즉시 실행하는 대신, 사전 정의된 구조 스키마(SPEC TEMPLATE.md)를 참조하여 필수 해석 조건(형상 치수, 재료 물성, 하중 및 경계조건 등)을 Spec.JSON 파일로 먼저 구조화한다. 특히, 에이전트가 자의적으로 가정한 값이 존재할 경우 이를 명시적으로 노출하고 최종 승인을 받는 휴먼인더루프(Human-in-the-loop) 절차를 거친다. 결과적으로 이러한 정형화 및 확인 과정은 LLM의 확률적 추론에 의한 불확실성을 실행 이전에 효과적으로 억제하며, 공학 해석의 안정성을 보장하는 핵심 역할을 한다.
2.5 FEA 자동화 시스템 아키텍처 및 워크플로우
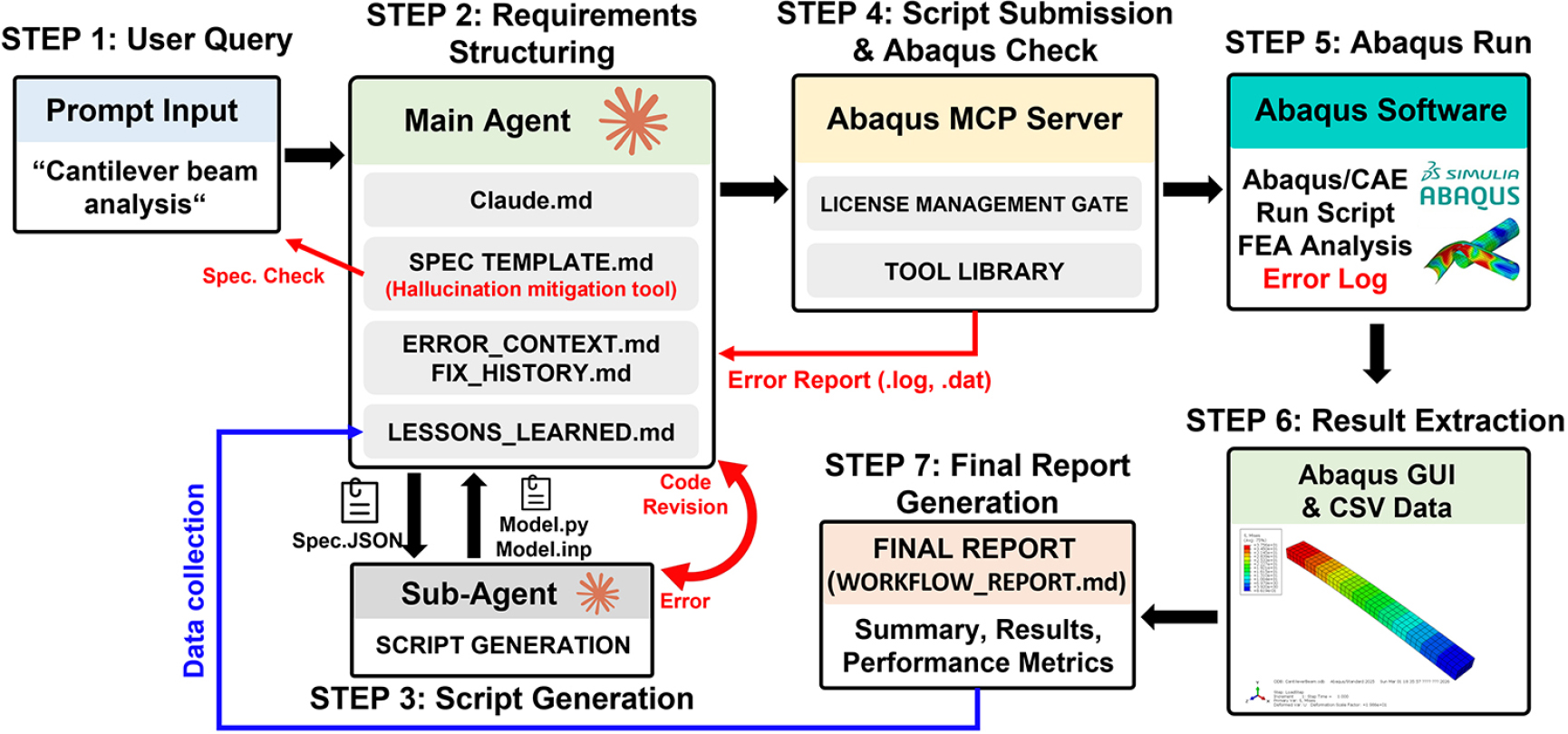
제안하는 자동화 시스템은 LLM 에이전트 영역, Abaqus MCP 서버 영역, 그리고 Abaqus 소프트웨어 실행 영역의 세 가지 계층으로 구분되며, 구축된 MCP 서버를 통해 유기적으로 데이터를 교환한다. 전체 시스템의 실행 워크플로우는 Fig. 3과 같이 초기 요구사항 분석부터 최종 경험 지식 데이터 축적까지 총 7단계의 절차를 거쳐 수행된다.
1) STEP 1(User Query): 데스크탑 기반의 Claude code 인터페이스를 통해 사용자로부터 비정형 자연어 프롬프트가 입력된다. 입력된 프롬프트는 시스템을 총괄하는 메인 에이전트(Claude Opus 4.6 모델)에 전달되어 사용자의 해석 의도와 세부 요구사항이 분석된다.
2) STEP 2(Requirements Structuring): 메인 에이전트가 Claude.md에 명시된 시스템 지침에 따라 사용자 요구사항을 분석하고, FEA 문제 정의에 필수적인 설계 파라미터를 사전에 정의된 구조 스키마(SPEC TEMPLATE.md)를 기반으로 정형화하고 사용자의 검토를 받는다. 최종적으로 확정된 데이터는 구조화된 설계 명세인 Spec.JSON 파일로 출력되어 다음 단계로 전달된다.
3) STEP 3(Script Generation): 메인 에이전트로부터 Spec. JSON 파일을 인계받은 서브 에이전트가 실제 해석 코드를 생성한다. 서브 에이전트는 문제의 복잡도를 판단하여, 단순한 모델링은 Python 기반 스크립트(Model.py)를 작성하고 정교한 제어가 필요한 고난도 태스크는 텍스트 형태의 모델 파일(Model.inp)을 직접 작성하는 방법으로 스크립트를 작성한 후 메인 에이전트에게 전달한다.
4) STEP 4(Script Submission & Abaqus Check): 메인 에이전트가 Abaqus MCP 서버를 사용해 Python API를 기반으로 Abaqus를 제어하며, 서버 내부의 도구들을 사용해 소프트웨어 가용 상태(라이선스 관리 게이트)와 Abaqus 내부 작업 현황을 실시간으로 점검한다.
5) STEP 5(Abaqus Run): 소프트웨어 가용 상태가 확인되면, 메인 에이전트가 MCP를 기반으로 Abaqus에서 서브 에이전트가 작성한 스크립트(Model.py 또는 Model.inp) 해석을 수행한다. 해석이 성공하면 다음 단계인 STEP 6으로 넘어가며, 에러 발생 시에는 .dat 및 .log 파일에 기록된 오류 정보가 MCP 서버를 통해 메인 에이전트에게 반환된다. 이때 메인 에이전트는 반환된 로그를 확인하고, 오류의 원인과 수정 계획을 담은 ERROR_CONTEXT.md 진단 문서를 생성하고, 서브 에이전트에게 스크립트 수정을 요청한다. 서브 에이전트는 전달받은 진단 문서와 FIX_HISTORY.md에 기록된 수정 이력을 상호 참조하여 동일한 오류의 반복을 방지하며 스크립트를 정밀하게 교정한다. 교정된 결과는 다시 메인 에이전트에게 보고되어 정상적인 해석이 완료될 때까지 자기 수정 루프를 반복한다.
6) STEP 6(Result Extraction): 해석이 성공적으로 완료되면 메인 에이전트가 MCP 서버를 사용하여 Abaqus 해석 결과 파일로부터 필요한 정보를 추출한다. 또한 Abaqus GUI를 통한 컨투어(contour) 결과 출력과 응력, 변위 등의 수치 데이터를 CSV 파일로 저장하며, 이를 통해 시스템이 시각적 및 정량적 정보를 통합 분석할 수 있는 기반을 마련한다.
7) STEP 7(Final Report Generation): 메인 에이전트가 모든 단계의 수행 이력과 데이터를 취합하는 최종 단계이다. 이를 바탕으로 요약 내용, 해석 결과, 성능 지표를 포함하는 마크다운 형식의 최종 보고서(WORKFLOW_REPORT.md)를 생성하여 사용자에게 제시한다. 보고서 작성이 마무리되면 워크플로우 과정에서 습득한 오류 패턴과 해결 전략을 경험적 지식 데이터(LESSONS_LEARNED.md)에 기록하여 향후 유사 태스크 수행을 위한 지식 자산으로 축적한다.
이와 같은 7단계의 워크플로우는 에이전트의 추론 역량과 MCP 도구를 결합해 공학적 신뢰성을 갖춘 자율 해석 시스템을 구현한다. 초기 단계의 환각 완화 장치와 실행 과정의 자기 수정 루프를 통해 해석 모델의 일관성을 유지하며, 이때 습득한 최적의 스크립트와 오류 해결 전략은 경험적 지식 데이터(LESSONS_LEARNED.md)로 자산화된다. 이러한 지식 베이스 구축은 새로운 해석 시나리오에서도 과거의 시행착오를 선제적으로 방어함으로써, 오류 재발을 막고 최종 결과 도출까지의 경로를 최적화하는 핵심 기반으로 작용한다.
3. FEA 자동화 시스템 검증 사례 연구
3장 검증 사례 연구에서는 제안한 FEA 자동화 시스템이 실제 FEA 문제를 자연어 프롬프트로부터 모델 생성, 해석 실행, 결과 도출까지 수행할 수 있는지 검증한다. 특히 2장에서 설계한 각 기능적 요소들이 단계적으로 활성화됨에 따라 시스템의 FEA 결과가 어떻게 변화하는지 분석한다. 이를 위해 각 실험 별로 시스템 구성 조건을 다르게 설정하였으며, 구체적인 기능 적용 여부와 내용에 대한 정보는 Table 2와 같다.
1) 자동화 시스템 성능 검증(3.1절): 복수의 단순 벤치마크 문제들을 대상으로 문제 정의부터 결과 도출까지의 전 과정 자동화 완수 능력을 확인한다. 특히 실행 과정에서 발생하는 구문 오류 등에 대해 2.2절에서 설계한 자기 수정 루프가 정상적으로 동작하여 최종 해석 성공에 도달하는지, 파이프라인의 기본 안정성을 검증한다.
2) 동일 프롬프트 반복 수행(3.2.1절): 동일 프롬프트 입력 조건을 반복 수행하여 결과의 변동성과 환각 발생 양상을 확인하고, 환각 완화 장치의 필요성을 논의한다.
3) 환각 완화 장치 적용 효과 분석(3.2.2절): 논리적 제약 메커니즘 적용 여부에 따른 파라미터 임의 설정 발생 가능성과 설계 의도 재현성을 비교한다. 환각 완화 장치 적용 시 동일 입력 반복 수행에서 결과 일관성을 확인하여 유효성을 입증한다.
4) 고난도 모델 확장성 검증(3.3절): 풍력 블레이드와 같은 고난도의 모델링 문제로 적용 범위를 확장하여 시스템의 실무 적용 가능성을 검증한다. 특히 경험적 지식 데이터(LESSONS_LEARNED.md)의 활용이 고도화된 문제 해결 과정에서 경험 기반 수행 최적화 성능을 정량적으로 입증한다.
Table 2.
Feature activation by paper section
| Paper section |
Abaqus MCP | Self-correction loop | Hallucination mitigation mechanism | Use of experience data |
| 3.1 | O | O | X | X |
| 3.2.1 | O | O | X | X |
| 3.2.2 | O | O | O | X |
| 3.3 | O | O | O | O |
실험에 사용된 PC 및 소프트웨어 사양은 Table 3과 같다.
Table 3.
Hardware and software specifications for simulation
| Category | Specifications |
| CPU | Intel Core i9-14900K |
| GPU | NVIDIA GeForce RTX 5080 |
| RAM | 64 GB (DDR5-5600) |
| OS | Microsoft Windows 11 |
| Software | Abaqus 2025, Python 3.10 |
3.1 FEA 자동화 시스템 검증: 프롬프트로부터 FEA까지
3.1.1 FEA 자동화 시스템 검증 실험 입력
시스템의 기본 성능 검증을 위해 대표적인 정적 해석 사례 3가지와 모달 해석 사례 1가지를 선정하였다. 실험의 각 케이스는 하기와 같으며, 제안한 자동화 시스템은 사용자의 프롬프트 입력으로부터 문제를 정의하고, Abaqus MCP를 호출하여 모델링부터 결과 리포트 도출까지 수행한다. 상세한 입력 프롬프트와 해석 유형은 Table 4에 정리하였다. 각 실험은 자동화 시스템의 자동화 검증을 위하여 프롬프트 입력 외의 별도 사용자의 개입없이 진행하였다.
Table 4.
Prompt inputs for verification of the automated analysis system
1) Case 1: 외팔보 정적 해석
2) Case 2: 중앙 구멍이 있는 평판의 정적 해석
3) Case 3: L자형 브래킷의 정적 해석
4) Case 4: 강철(Steel)과 알루미늄(Aluminum) 복합 재료가 적용된 단차 원형축 모달 해석
3.1.2 FEA 자동화 시스템 검증 결과
각 케이스에 대한 자동화 시스템 실행 결과는 Table 5에 요약하였다. 해당 표에는 형상, 재료, 해석 조건, 메시, 주요 결과와 함께 자기 수정 루프 반복 횟수 및 전체 소요 시간이 제시되어 있다. FEA 수행 과정에서 문제 정의는 구조화된 설계 명세 파일인 Spec.JSON으로 저장되며, 여기에는 형상 정보, 재료 물성, 단면/섹션 정의, 메시 조건, 경계조건, 하중 조건 등 해석 수행에 필요한 핵심 파라미터가 포함된다. 이후 메인 에이전트는 해당 명세를 하위 에이전트에 전달하며, 하위 에이전트는 이를 기반으로 해석 스크립트(Model.py) 또는 입력 파일(Model.inp)을 생성한다. 생성된 파일은 다시 메인 에이전트로 전달되고, 메인 에이전트는 이를 이용하여 Abaqus 해석을 수행한다.
Table 5.
Verification results of the proposed automated analysis system
해석 과정에서 오류가 발생할 경우 원인과 수정 계획은 ERROR_CONTEXT.md에, 수정 이력은 FIX_HISTORY.md에 각각 기록되어 자기 수정 루프에 활용된다. 정상적으로 해석이 종료되면 결과 데이터와 수행 이력은 WORKFLOW_ REPORT.md에 저장되며, 각 검증 케이스에 대한 대표적인 Abaqus 해석 결과는 Fig. 4와 같이 시각적으로 확인할 수 있다. 본 시스템은 모든 케이스에서 사용자의 자연어 프롬프트로부터 해석 결과 출력과 최종 리포트 생성까지의 전 과정을 성공적으로 수행하였다.
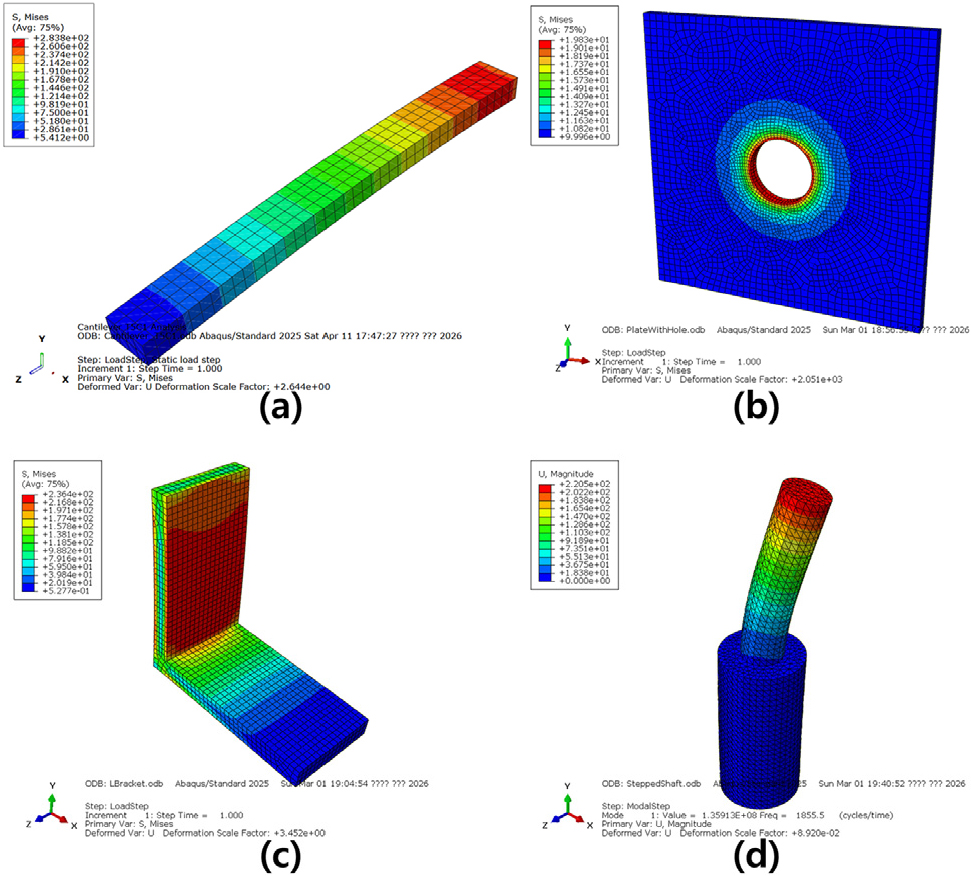
구체적으로 외팔보 정적 해석(Case 1)의 경우, 최대 von Mises stress는 291.25MPa, 최대 변위(U magnitude)는 7.571mm로 산출되었다. 동일 조건의 Timoshenko 보 이론에 따르면 최대 변위는 7.634mm이며, 본 해석 결과의 변위 오차는 약 -0.82%로 이론값과 매우 잘 일치하였다. 반면 최대 굽힘응력의 이론값은 600MPa로, FEA 결과와는 약 -51.5%의 차이를 보였다. 이는 C3D8R 축소적분 요소와 비교적 거친 메시 조건에서 고정단 근방의 급격한 응력 구배를 충분히 포착하지 못한 데 기인한 것으로 판단된다. 따라서 본 결과는 변위 응답의 정확도가 높음을 보여주며, 보다 엄밀한 응력 검증을 위해서는 추가적인 메시 세밀화 또는 고차/완전적분 요소의 적용이 필요함을 시사한다.
구멍 평판 정적 해석(Case 2)에서는 최대 응력과 응력집중계수(SCF)를 산출하였고, 이 과정에서 실행 오류를 극복하기 위해 자기 수정 루프가 2회 수행된 것으로 기록되었다. L자 브래킷 정적 해석(Case 3)에서도 결과가 성공적으로 산출되었으며, 단차축 모달 해석(Case 4)에서는 고유진동수 10개 모드를 출력함으로써 모달 해석까지 수행 가능함을 보였다.
그러나 FEA 수행 성공이 설계 의도와의 완전한 일치를 보장하지 않음이 확인되었다. 타공판 문제(Case 2)에서의 하중 조건 임의 해석이나 L자 브래킷(Case 3)의 볼트홀 누락 사례는, 단순한 스크립트 실행 성공 이상의 검증 절차가 필수적임을 시사한다. 이는 모델 형상, 하중, 경계조건 등 핵심 항목에 대해 사용자의 의도 반영 여부를 확인하는 별도의 신뢰성 담보 장치가 필요함을 의미한다.
3.1.3 프롬프트 기반 모델 수정 가능성
본 시스템은 후속 프롬프트를 통해 모델을 수정하거나 설계 변경을 반영할 수 있는 유연성을 제공한다. 제시된 타공판(Case 2) 해석 결과에 대해 “적용 하중이 전방향이 아닌 x축 방향 인장응력 모델로 수정하여 해석”하도록 요청하면 시스템의 에이전트가 이를 수정하기 위한 행동을 취하며, 수정된 결과를 Fig. 5와 같이 확인할 수 있다.

이는 수작업 편집없이 자연어 지시만으로 해석 조건을 갱신하고 결과를 재산출하는 반복 운용성을 보여준다. 제안한 시스템은 단발성 자동화 FEA를 넘어 사용자 피드백을 수용하며 설계에 반영할 수 있음을 보여준다.
3.2 환각 완화 장치 검증 실험
3.1절의 기초 검증 결과, 사용자의 비정형 자연어 프롬프트 입력 시 LLM 기반 에이전트가 누락된 파라미터나 이미 제공된 파라미터를 임의로 설정하는 환각 현상이 관찰되었다. 본 절에서는 이러한 변동성을 분석하고, 이를 억제하기 위해 제안한 환각 완화 장치의 도입 전후 결과 일관성을 비교한다.
3.2.1 환각 완화 장치 미적용 검증
환각 완화 장치를 적용하지 않은 상태에서 “Abaqus MCP를 사용하여 외팔보 끝단 집중하중 모델의 정적 해석을 수행하라”는 동일 프롬프트로 4회 반복 실험하였다. 실험 결과, Table 6과 Fig. 6에서 확인되듯 동일한 프롬프트임에도 불구하고 수행 시마다 형상 치수, 하중 정의 방식, 메시 조건 등 해석의 핵심 파라미터가 일관되지 않게 구성되는 사례가 관찰되었다.
Table 6.
Variability in FEA outcomes under identical prompt inputs
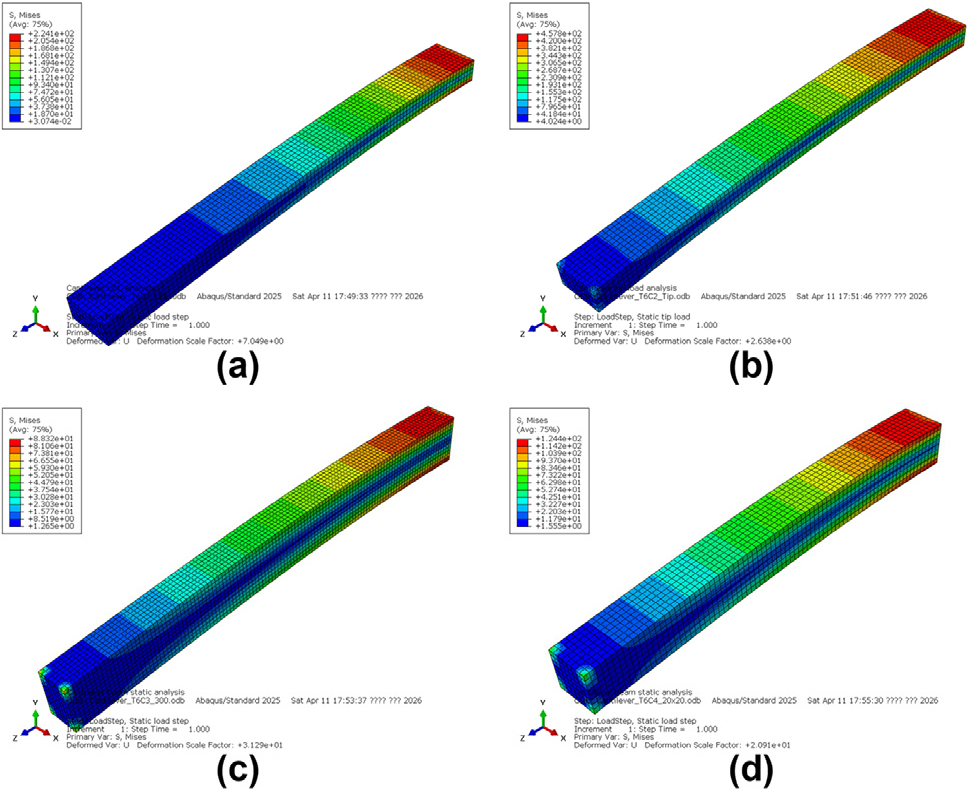
본 절의 핵심 문제는 해석 정확도 자체보다는 동일 입력에 대해 모델 정의가 비결정적으로 달라진다는 점에 있다.
3.2.2 정형화 기반 환각 완화 장치 적용 검증
이러한 변동성을 억제하기 위해 2.4절에서 상술한 논리적 제약 메커니즘 기반의 환각 완화 장치를 활성화하여 시스템의 성능을 검증하였다. 해당 장치가 적용된 환경에서 시스템은 즉각적인 FEA 해석을 위한 스크립트 생성을 수행하는 대신, 비정형 프롬프트에 대하여 2.4절에서 설명한 구조 스키마(SPEC TEMPLATE.md)를 활용하여 핵심 파라미터를 구조화하고, 누락되거나 임의로 채워진 정보에 대해 사용자의 명시적 승인을 구하는 절차를 수행한다. 이 과정에서 각 항목은 사용자가 직접 제공한 값(user), 에이전트가 공학적 판단에 따라 가정한 값(llm_assumed), 그리고 사용자 검토 후 승인된 값(user_confirmed)으로 관리된다.
사용자가 “200 mm 외팔보 집중하중 정적해석”과 같이 아직 충분히 구체화되지 않은 프롬프트를 입력한 경우, 시스템은 이를 즉시 해석 코드로 변환하지 않고 먼저 Table 7과 같은 형식으로 8개의 필수 항목 범주에 따라 구조화한다. 이때 외팔보 형상과 길이 200mm는 user 정보로 분류되지만, 폭과 높이와 같은 단면 치수는 llm_assumed 항목으로 제안될 수 있다. 이후 시스템은 “다음 항목들은 사용자가 명시하지 않아 가정된 값입니다: 보 폭, 보 높이, 재료, 요소 타입, 시드 크기, 하중 크기, 하중 방향. 이 값을 그대로 사용할까요?”와 같은 형식으로 사용자에게 확인을 요청하며, 사용자가 특정 항목을 수정하면 해당 값은 user로 갱신되고, 전체 승인이 이루어지면 관련 항목은 user_confirmed로 전환된다. 승인 과정 후 메인 에이전트는 문제 정의 명세 파일인 Spec.JSON을 작성한다.
Table 7.
Structured parameter values including user and LLM-assumed entries
이와 같은 절차를 통해 시스템은 사용자의 비정형 입력을 단순히 내부적으로 보완하는 것이 아니라, 누락된 정보와 가정된 값을 명시적으로 노출하고 사용자 피드백을 반영하여 최종 해석 명세를 확정한다.
확정된 정형화 입력을 바탕으로 5회의 반복 수행을 실시한 결과, Fig. 7에 제시된 바와 같이 모든 수행 차수에서 응력 분포와 변형 형상이 완벽하게 일치하는 결과를 얻었다. 이는 환각 완화 장치 미적용 시 발생했던 모델 정의의 임의적 보완과 그로 인한 결과의 변동성이 효과적으로 억제되었음을 의미한다. 결과적으로 논리적 제약 메커니즘 기반의 환각 완화 장치는 에이전트가 임의의 가정을 모델에 포함시키는 환각 상황을 효과적으로 억제하며, 공학 해석의 재현성을 확보하는 데 결정적인 역할을 수행한다.
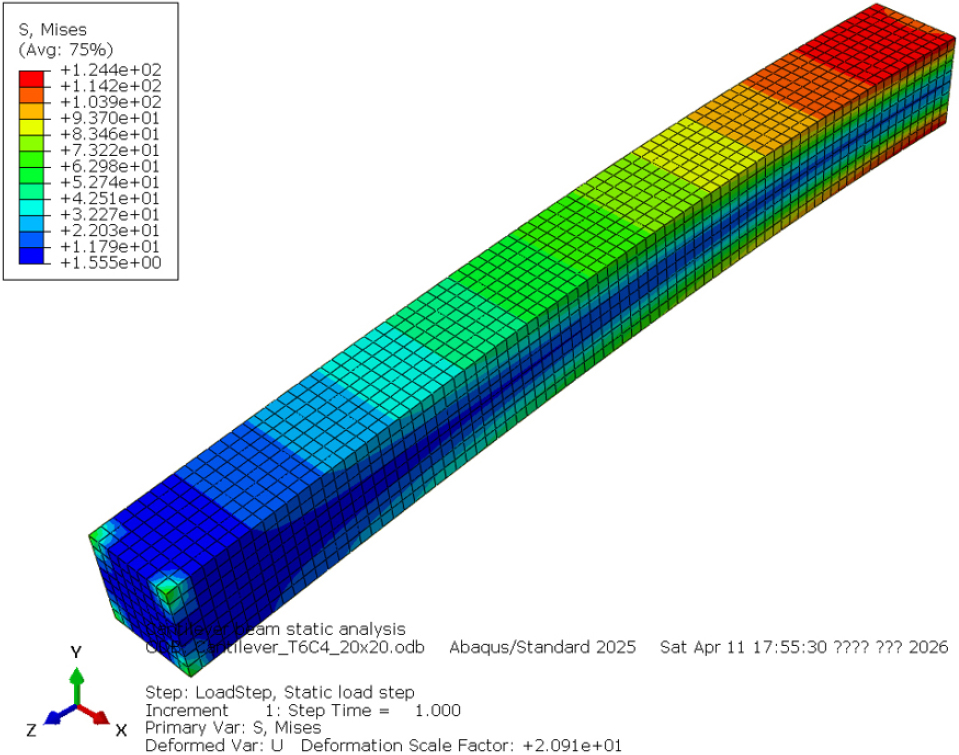
3.2.3 환각 완화 장치 적용에 따른 결론 및 한계
검증 결과, 정형화된 파라미터 구조를 명시하고 확정하는 시스템적 절차를 구축함으로써 동일 프롬프트 반복 수행에서 결과의 재현성이 완벽하게 확보됨을 확인하였다.
이러한 접근은 단순히 입력 문장을 개선하는 프롬프트 엔지니어링의 차원을 넘어, 사용자의 설계 의도를 파라미터 구조로 명시하고 이를 강제로 확인하는 절차를 추가했다는 점에서 차별성을 가지며, 결과적으로 문제 정의의 견고성과 이후 수행되는 해석 프로세스의 안정성이 향상되었다.
하지만 본 절의 실험은 외팔보와 같은 제한된 예제에 기반하고 있어 모든 종류의 공학 문제와 해석 유형을 포괄하기에는 여전히 경험적 지식 데이터가 부족한 상태이다. 특히 복잡 형상, 다단계 비선형 해석 등 문제가 고도화될수록 현재의 파라미터 정형화 규칙만으로 대응하기 어려운 새로운 유형의 모호성이 발생할 가능성이 존재한다. 따라서 향후 연구에서는 더욱 광범위한 공학 문제에 대한 검증 규칙을 확장하고, 다양한 물리적 환경에서의 실패 패턴을 지속적으로 학습시켜 시스템의 일반화 성능을 확장할 필요가 있다.
3.3 고난도 문제 해결 역량 검증: 풍력 블레이드 사례
3.3.1 풍력 블레이드 모델
본 절에서는 시스템의 공학 문제 해결 역량을 정밀 검증하기 위해 복잡한 기하학적 정의와 고도화된 모델링 기법을 요구하는 풍력 블레이드(Wind Turbine Blade) 해석 사례를 다룬다. 블레이드 모델은 정교한 익형(Airfoil) 데이터를 생성하고 수만 개의 절점과 요소를 모델링에 반영해야 할 뿐만 아니라, 루트(Root)에서 팁(Tip)으로 갈수록 변화하는 코드(Chord) 길이와 비틀림(Twist) 각도를 구현해야 하므로 일반적인 예제 대비 해석 난이도가 높다.
3.3.2 실험 케이스 구성 및 조건
시스템의 설계 유연성과 파라미터 변화에 대한 대응력을 평가하기 위해, 에이전트의 경험적 지식 데이터 축적 단계에 따른 4가지 실험 케이스를 구성하였다. 모든 케이스에서 알루미늄 합금 재질, 블레이드 압력면에 2kPa의 풍압 하중, 허브 내경을 완전 고정(Encastre)하는 조건을 동일하게 유지하였다.
1) Case 1(초기 모델링 및 정적 해석): 시스템에 기존 경험적 지식 데이터가 전혀 없는 상태에서의 첫 번째 수행으로, 에이전트는 사용자의 프롬프트로부터 문제를 정형화하여 3개의 날개를 가진 블레이드 모델과 NACA 4412 익형 정보, 허브 구속 조건을 정의하고 해석 절차에 따라 FEA를 수행한다.
2) Case 2(경험 기반 수행): Case 1을 거치며 발생했던 스크립트 오류나 수렴 실패를 해결해 본 경험적 지식 데이터가 축적된 상태에서의 재수행이다. 에이전트는 경험적 지식 데이터(LESSONS_LEARNED.md)에 기록된 이전 시도의 오류 패턴을 참조하여 더욱 안정적인 스크립팅 전략을 채택한다.
3) Case 3(기 수행 데이터 기반 형상 수정): Case 2에서 성공적으로 수행된 데이터를 기반으로 익형 단면 형상(NACA 4418)과 블레이드 길이(1,500mm)를 변화시켜 시스템의 설계 갱신 능력을 확인한다.
4) Case 4(복합 조건 변경 및 확장): 완성형 코드 플랫폼과 축적된 경험적 지식 데이터를 바탕으로 익형 단면 형상(NACA 0025) 변화와 날개 개수 증설(6개) 등 위상 변화를 요구하여, 에이전트가 복잡한 좌표 변환 로직을 일관성 있게 구현할 수 있는지와 문제 해결 성능 향상을 정량적으로 검증한다.
3.3.3 고난도 문제 해결 실험 결과 및 분석
풍력 블레이드 시나리오에 따른 시스템 수행 결과는 Table 8에 요약되어 있으며, 각 실험의 응력 분포와 변형 형상은 Fig. 8의 Abaqus GUI 시각화 결과를 통해 확인할 수 있다. 이는 경험적 지식 데이터 축적에 따른 해석의 안정성과 효율성 변화를 정량적으로 보여준다.
Table 8.
Experimental specifications and performance metrics for wind turbine blade analysis (Cases 1-4)
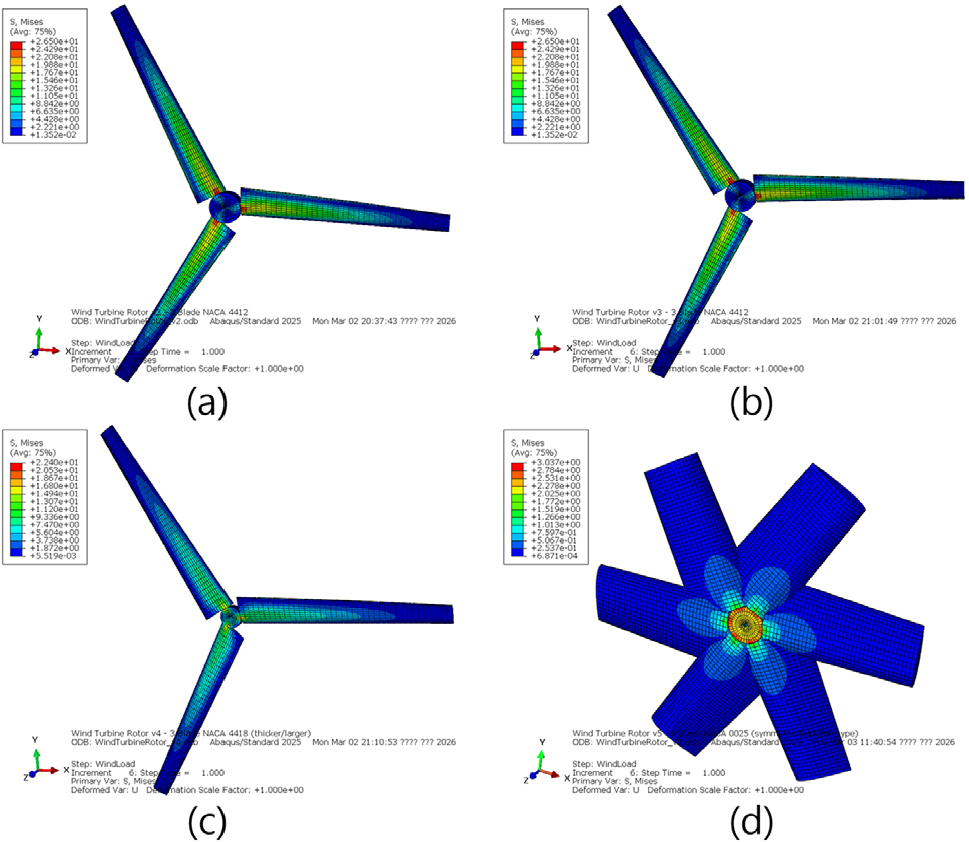
지식 데이터가 전무한 Case 1에서는 복잡한 형상 구현 중 Negative Jacobian 발생 및 명칭 정의 오류 등으로 총 5회의 자기 수정 루프가 발생하여 22분 20초가 소요되었다. 시스템은 이러한 실패 양상을 진단 문서로 구조화하여 교정하고, 도출된 해결 전략을 LESSONS_LEARNED.md에 기록하여 지식 자산화하였다.
경험 데이터베이스인 LESSONS_LEARNED.md는 핵심 원칙, 실패 사례, 성공 사례, API 사용 팁 등의 내용으로 구성되며, 설계, 스크립트 생성, 오류 수정 단계에서 공통으로 참조되어 활용된다. 이러한 구조는 검증된 모델링 전략과 오류 회피 지식을 프로젝트 간 재사용 가능한 형태로 축적하는 역할을 한다.
동일 조건으로 재수행한 Case 2에서는 축적된 지식을 참조하여 에러 수정 루프없이 단 한 번의 실행으로 해석을 완료하였다. 수행 시간은 10분 27초로 Case 1 대비 약 53% 단축되었으며, 동일한 수준의 응력과 변위를 산출함으로써 실행 안정성을 입증하였다. 익형과 길이를 변화시킨 Case 3에서는 기존 로직을 기반으로 필요한 코드만을 정밀하게 수정하여 3분 56초 만에 해석을 마쳐 설계 갱신 효율성을 극대화하였다. 익형과 길이 변경 뿐만 아니라 블레이드 개수를 6개로 증설한 Case 4는 기존에 축적된 스크립트와 경험적 데이터를 기반으로 2분 12초라는 가장 짧은 시간 내에 모든 과정을 완료하였다.
이러한 결과는 시스템이 검증된 모델링 전략과 코드 자산을 축적할 경우, 이를 기반으로 다양한 FEA 문제로의 확장이 가능함을 시사한다. 특히 에이전트가 기검증된 로직을 재사용함으로써 다양한 설계 변환 문제를 신속하게 생성하고 해석할 수 있는 운용 환경을 제공한다. 결과적으로 경험적 지식 데이터 기반의 피드백 구조는 태스크의 복잡도가 높을수록 문제 해결 효율을 가속화하는 핵심 동력이 된다. 초기 수행 대비 최종 수행 시간이 약 90% 단축된 결과는, 지능형 에이전트가 학습을 통해 실무 워크플로우를 최적화하고 공학적 신뢰성을 확보할 수 있음을 정량적으로 입증한다.
3.4 사례 검증 결론 및 한계
본 연구에서 수행한 다양한 시나리오별 사례 검증 결과는 Table 9에 요약되어 있다. 간단한 FEA 문제부터 복잡한 풍력 블레이드 모델까지 모든 실험에서 해석 절차 완료율 100%를 달성하며 시스템의 효용성을 입증하였다.
Table 9.
Summary of validation cases and key outcomes
제안된 환각 완화 장치는 비정형 프롬프트 입력 환경에서 문제를 구조화하고, 확정된 해석 파라미터를 사용자에게 사전 검토받는 절차를 통해 LLM 특유의 환각 문제를 효과적으로 제어하였다. 또한, 단순히 주어진 명령을 수행하는 수준을 넘어, 구조화된 문서 형태인 LESSONS_LEARNED.md를 통해 수행 과정의 경험을 자산화하였다. 이러한 지식 축적 구조는 시스템이 스스로 학습하여 성능을 개선하는 결과를 실현하였으며, 이는 복잡한 해석 시나리오에서 시행착오와 해석시간을 획기적으로 줄이는 핵심 동력으로 작용하였다.
다만, 본 연구에서 사용한 소요 시간(Elapsed time) 지표는 시스템 수행 효율을 비교하는 데 유용한 실험적 지표이지만, Claude와 같은 외부 상용 LLM API를 사용하는 환경에서는 서버 부하 상태, 네트워크 지연, 응답 대기 시간 등 통제하기 어려운 외부 요인의 영향을 받을 수 있다는 방법론적 한계가 있다. 따라서 본 논문에서 제시한 수행 시간 단축 결과는 경험적 지식 축적에 따른 효율 향상의 경향성을 보여주는 지표로 해석하는 것이 타당하며, 에이전트 자체의 문제 해결 효율을 보다 엄밀하게 평가하기 위해서는 입출력 토큰 사용량과 같은 토큰 기반 지표를 함께 계측하여 보완할 필요가 있다. 후속 연구에서는 대표 사례에 대한 토큰 사용량 감소 추이를 정량적으로 제시함으로써 보다 객관적인 성능 비교 체계를 구축할 필요가 있다.
또한 본 연구에서 사용된 FEA 문제는 비교적 정형화된 형태와 선형 문제 위주로 검증되었다는 점에서 활용 범위의 한계가 존재한다. 재료 비선형, 접촉, 열-구조 연성과 같은 문제는 기존 구조화 명세와 도구 체계를 확장함으로써 대응 가능성이 있으나, 균열 전파 문제(XFEM, VCCT, Cohesive Zone)나 사용자 정의 재료 서브루틴(UMAT/VUMAT)과 같은 고도 비선형 문제의 경우에는 문제 특화 파라미터 정의, 컴파일 환경 관리, 비구체적 수렴 오류 해석 등의 측면에서 현재 프레임워크만으로는 적용에 한계가 있다. 향후 연구에서는 다단계 비선형 해석, 복잡한 접촉 조건 정의, 그리고 다물리 연성 해석 등으로 검증 범위를 확장하고, 에이전트가 물리적 타당성을 스스로 판단할 수 있는 V&V(Verification and Validation) 체계를 고도화할 필요가 있다(Oberkampf and Trucano, 2002).
4. 결 론
본 연구에서는 LLM과 상용 FEA 소프트웨어인 Abaqus를 MCP로 통합하여, 사용자의 자연어 명령(프롬프트)만으로 문제 정의부터 결과 도출까지의 전 과정을 자동화된 절차에 따라 수행하는 에이전틱 자동화 시스템을 개발하였다. 제안한 시스템은 메인 에이전트와 하위 에이전트로 구성된 멀티 에이전트 구조를 기반으로, Abaqus 실행 과정에서 발생하는 오류를 자기 수정 루프를 통해 진단하고 교정함으로써 최종 해석 결과 도출까지의 절차를 안정적으로 수행할 수 있음을 보였다.
또한 본 연구에서는 공학 해석의 신뢰성 확보를 위해 논리적 제약 메커니즘 기반의 환각 완화 장치를 도입하였다. 메인 에이전트는 비정형 프롬프트를 즉시 해석 코드로 변환하지 않고, SPEC TEMPLATE.md를 참조하여 FEA 문제 정의에 필요한 핵심 파라미터를 구조화한 뒤, 실행 전 사용자 검토 및 승인 절차를 거쳐 해석 명세를 확정하였다. 이를 통해 LLM이 누락된 정보를 임의로 보완하는 환각 문제를 효과적으로 억제하고, 설계 의도의 재현성과 해석 절차의 일관성을 향상시킬 수 있음을 확인하였다.
사례 검증 결과, 제안한 시스템은 단순 정적 및 모달 해석 문제뿐 아니라 풍력 블레이드와 같은 고난도 형상 모델에 대해서도 end-to-end 해석 절차를 성공적으로 수행하였다. 특히 동일 프롬프트 반복 수행 실험에서는 환각 완화 장치 적용 시 결과의 재현성이 확보되었고, 고난도 풍력 블레이드 사례에서는 경험적 지식 데이터가 축적됨에 따라 자기 수정 루프 횟수가 감소하고 전체 소요 시간이 단축되는 경향을 확인하였다. 이는 LESSONS_LEARNED.md 기반의 경험 지식 축적 구조가 복잡한 공학 문제 해결의 안정성과 효율 향상에 실질적으로 기여할 수 있음을 보여준다.
그러나 본 연구의 검증은 비교적 정형화된 선형 구조해석 문제를 중심으로 수행되었으며, 소요시간 지표 역시 외부 LLM API 환경의 서버 부하, 네트워크 지연, 응답 대기 시간 등의 영향을 받을 수 있다는 한계가 있다. 또한 재료 비선형, 접촉, 열-구조 연성, 균열 전파, 사용자 정의 재료 서브루틴과 같은 고도 비선형 문제에 대해서는 현재의 구조화 규칙과 도구 체계만으로 충분하지 않을 수 있다.
따라서 향후 연구에서는 보다 다양한 공학 문제와 해석 유형으로 검증 범위를 확장하고, 토큰 사용량 기반 효율 지표와 물리적 타당성 검증(V&V) 체계를 함께 고도화함으로써, 제안한 프레임워크의 일반성과 실용성을 더욱 강화할 필요가 있다. 또한 탄소성, 접촉, 기하비선형 해석과 사용자 정의 재료 서브루틴(UMAT/VUMAT)이 적용되는 보다 복잡한 비선형 문제로 확장하여, 제안된 방법론의 적용 가능성을 검증하고 그 고도화를 수행할 예정이다.
