

1. 서 론
2. 랜덤필드
2.1 유한 차원 분포
2.2 카루넨 뢰브 전개
3. 랜덤필드-유한요소 모델
4. 적합 일반화 분해
4.1 오프라인 단계
4.2 온라인 단계
5. 랜덤필드-적합 일반화 분해 기반 불확실성 정량화
6. 수치예제
7. 결 론
1. 서 론
신뢰성 있는 설계를 위해서는 시스템 내 존재하는 불확실성을 체계적으로 정량화하고, 이를 설계 전 과정에 반영하는 것이 필수적이다. 실제 공학 시스템에는 재료의 물성치, 제조 공정의 편차, 작동 환경 등 다양한 형태의 불확실성이 존재한다. 이러한 입력의 불확실성은 시스템의 출력 거동에 직・간접적인 영향을 미친다. 만약 이러한 불확실성을 고려하지 않고 결정론적인 입력 값으로 가정하여 설계를 수행할 경우, 예기치 못한 품질 저하나 낮은 확률로 발생하더라도 치명적인 결과를 초래할 수 있는 위험 상황으로 이어질 수 있다(Lee and Rahman, 2020).
출력의 불확실성을 정량화하려면, 불확실한 입력 변수들이 시스템의 출력에 어떤 영향을 미치는지를 파악해야 한다. 일반적으로 몬테카를로 시뮬레이션을 통해 다수의 샘플을 생성하고, 이에 대한 응답을 분석함으로써 출력의 확률적 특성을 추정하게 된다. 그러나 고차원의 불확실성이 존재하는 경우, 출력의 확률 분포를 정확히 추정하기 위해서는 수십만 개 이상의 샘플이 필요하며, 특히 계산 비용이 큰 공학 시스템에서는 현실적인 적용이 어려워진다.
이러한 몬테카를로 기반 접근법의 한계를 극복하기 위해 시스템의 차원을 효과적으로 낮추어 해를 빠르게 근사하는 다양한 차수축소모델이 제안되어 왔다(Lucia et al., 2004). 대표적으로, 적합 직교 분해(Proper Orthogonal Decomposition, POD)는 고충실도 모델의 해를 기반으로 특이값 분해(Singular Value Decomposition)를 수행하여 주요 패턴을 추출하고, 이를 통해 구성된 기저 공간으로 시스템을 투영함으로써 차원을 축소한다(Liang et al., 2002). 이 방식은 시스템 자체의 규모를 줄이기 때문에 투영 이후 계산 속도가 매우 빠르다는 장점이 있다. 하지만 학습 데이터를 기반으로 기저를 구성하기 때문에 데이터 의존성이 크며, 불확실성을 포함된 다양한 변수 조합에 따른 응답을 포괄적으로 반영하기 어렵다는 한계가 존재한다.
적합 일반화 분해(Proper Generalized Decomposition, PGD, Chinesta et al., 2011)는 시스템의 약형식을 분리하여 해를 점진적으로 근사하고, 동시에 차원을 축소하는 방식을 취한다. 특히, 오프라인 단계에서 전역 해를 분리된 표현으로 구한 뒤, 온라인 단계에서 이를 조합하여 다양한 파라미터 조합에 대한 응답을 빠르게 계산할 수 있다. 고차원 파라메트릭 문제에 유연하게 적용 가능하다는 점에서 불확실성 정량화에 특히 적합한 방법론이다.
한편, 재료 물성의 불확실성은 공간적으로 분포되는 특성을 갖기 때문에, 이를 보다 정밀하게 반영하기 위해 랜덤 필드 기반의 모델링이 필요하다. 본 연구에서는 카루넨 뢰브 전개(Karhunen-Loève Expansion, KL Expansion)를 통해 재료의 공간적 불확실성을 적은 수의 확률 변수로 효율적으로 근사하고, 이를 PGD와 결합하여 구조물 응답의 확률 분포 및 신뢰성을 효과적으로 평가하였다. 또한, 위험가치(Value at Risk, VaR)를 도입해 시스템의 신뢰성을 정량적으로 검증하였다.
2. 랜덤필드
랜덤필드는 다차원 공간상의 각 점에 확률변수를 대응시키는 함수이다. 이때 각 위치의 확률 변수는 공간적으로 상관성을 가지며, 이러한 통계적 구조는 평균 함수, 공분산 함수, 상관 거리 등으로 정량적으로 표현된다. 랜덤필드는 이러한 특성 덕분에 연속적인 공간이나 시간, 또는 그 이상의 고차원 영역에서의 불확실성을 효과적으로 모델링할 수 있다.
랜덤필드는 연속적인 공간상의 모든 점에 대해 하나의 확률변수를 할당하는 구조이며 무한한 개수의 확률변수들로 구성된다. 이러한 무수한 확률 변수들의 누적 분포함수 또는 확률 밀도함수를 정의하는 것은 불가능하기 때문에 유한개의 지점들에 대한 확률 분포를 이용하여 랜덤필드를 특정(Characterize)해야 한다.
2.1 유한 차원 분포
랜덤필드 는 정의된 영역 상의 유한한 지점 에서의 값을 기반으로, 각 위치 에서의 확률 변수들의 집합인 -차원의 랜덤 벡터 식 (1)과 같이 이산화할 수 있다.
이러한 유한 차원 표현에 대해 랜덤필드 의 유한 차원 분포는 랜덤 벡터 X의 결합 누적 분포 함수로 정의되며, 미분 가능할 경우 랜덤필드의 확률 밀도 함수 또한 정의할 수 있다. Kolmogorov의 정리에 따르면, 랜덤 벡터의 유한차원 분포 이 임의의 양의 정수 에 대하여 일관성(Consistency) 조건 식 (2)를 만족한다.
여기서, 는 각 랜덤변수 의 실현값 (realization)을 의미한다. 또한, 임의의 순열 에 대하여 대칭성(Symmetry) 조건 식 (3)을 만족할 때,
해당 유한 차원 분포들과 일치하는 연속적인 랜덤필드의 존재성이 보장된다.
2.2 카루넨 뢰브 전개
카루넨-뢰브 전개는 랜덤필드를 무한개의 고유값과 고유함수으로 구성된 KL 모드, 그리고 확률변수의 선형 조합 식 (4)로 표현하는 방법이다.
여기서, 는 고유값, 는 대응되는 고유모드함수, 는 서로 비상관적인 확률변수이다.
실제 계산에서는 무한개의 고유값과 고유함수를 모두 구할 수 없기에 상위 개의 KL모드만을 사용하는 절단(truncation)이 필요하다. 이에 따라 유한 차원 랜덤필드의 KL 근사 표현은 다음 식 (5)와 같이 주어진다:
KL 전개의 고유값은 대응되는 고유함수가 랜덤필드 전체 변동성에 기여하는 정도를 나타내므로, 누적 에너지를 기준으로 충분한 비율을 설명하는 상위 개의 KL 모드만을 사용하여 랜덤필드를 효율적으로 근사할 수 있다(Lindgren et al., 2011). 또한, 원래 랜덤필드가 가우시안 분포를 따를 경우, KL 근사를 통해 근사된 랜덤필드는 기존의 랜덤필드와 동일한 확률 분포를 가진다. 이는 KL전개 기반의 근사가 랜덤필드의 확률적 특성을 효과적으로 보존함을 의미한다.
3. 랜덤필드-유한요소 모델
시스템이 속한 공간 𝛺의 특정 위치 에서 랜덤필드는 강성 텐서
안에 포함되어 유한요소 강성행렬 조립은 식 (7)과 같이 반영된다.
식 (6)과 식 (7)에서 는 평균 탄성 계수이며, B는 strain-displacement 행렬, D는 물성 행렬이고, :는 이중 텐서 내적을 의미한다. 이때 유한한 랜덤필드의 값은 매핑 함수를 통해 요소별 적분점(Integration Point)으로 직접 매핑된다.
KL 전개의 선형적인 연산 방식 때문에 KL 모드는 결정론적 값으로써 Finite Element Method(FEM)의 강성 행렬 조립 식 내에 포함되고, 확률변수는 외부에서 곱해져 전역 단위에서 강성 행렬을 동적으로 재구성할 수 있다(Garikapati et al., 2019). 결과적으로 랜덤필드가 바뀔 때마다 FEM의 강성행렬 전체를 새로 조립할 필요 없이 사전 계산된 KL 모드별 강성 행렬에 확률변수를 곱하고 더하는 방식으로 빠른 계산이 가능하다. 최종적으로 개의 KL 모드를 반영한 랜덤필드의 유한요소 모델은 식 (8)로 표현되고,
4. 적합 일반화 분해
적합 일반화 분해(Proper Generalized Decomposition, PGD)는 고차원 문제를 효율적으로 해결하기 위한 차수 축소 기법이다. d개의 스칼라 또는 벡터 변수 에 대한 해 를 공간, 시간, 물성치와 같은 여러 변수에 대해 분리된 함수 들의 곱 형태는 식 (11)과 같이 근사한다.
각 변수들의 조합에 대한 해를 각각 계산하는 기존의 해석 방식과 달리, PGD는 전체 해 공간을 각 변수에 대한 함수를 순차적으로 반복 계산하며 점진적으로 근사하는 구조를 갖는다. PGD는 전체 해 공간을 표현하는 변수별 분리된 함수들을 구하는 오프라인 단계와, 분리된 함수들을 조합하여 빠르게 해를 근사하는 온라인 단계로 나뉜다.
4.1 오프라인 단계
오프라인 단계에서는 전체 해공간을 분리된 표현으로 연속적으로 계산한다. PGD는 풀고자 하는 편미분 방정식을 각 변수에 대해 곱 형태로 분리하여 고차원 문제를 변수별 저차원 문제로 나눈다.
변수별 분리된 함수들은 고정점 반복법(Fixed Point Iteration, Chinesta et al., 2013)을 통해 계산된다. 이는 각 변수에 해당하는 함수를 계산할 때 나머지 변수들의 함수는 고정한 상태로 반복적으로 갱신하며 잔차를 줄이는 방식이다.
이러한 과정을 모든 변수에 대해 순차적으로 반복함으로써 전체 해를 점진적으로 개선(Enrichment)해 나간다. 한 번의 고정점 반복법이 완료되면 계산된 함수들의 곱으로 하나의 모드가 완성된다. 이는 시스템의 고차원 해공간을 표현하는 첫 번째 rank-1 근사에 해당한다. 이후 과정에서는 구해진 모드들을 제외하고 새로운 rank-1 항만을 계산하게 된다. 이러한 반복적인 개선 과정을 통해 추가적인 모드들을 구하고, 이를 기존 모드들과 합하여 근사해의 정확도를 지속적으로 향상시킨다. 위와 같은 과정은 현재 단계에서 계산된 번째 모드와 첫 번째 모드의 크기의 비로 표현되는 에러는 식 (12)와 같이 충분히 작아졌을 때 종료된다.
4.2 온라인 단계
온라인 단계에서는 오프라인 단계에서 구한 분리된 함수들을 단순히 곱해줌으로써 전체해를 근사한다. 이를 통해 실시간으로 빠르게 여러 변수들의 조합에 대한 해를 계산할 수 있다.
5. 랜덤필드-적합 일반화 분해 기반 불확실성 정량화
랜덤필드-적합 일반화 분해를 이용한 전체 알고리즘을 Fig. 1에 나타내었다. 오프라인 단계에서는 먼저 카루넨-뢰브 전개를 통해 랜덤필드를 효율적으로 근사하여 상위 KL 모드(고유함수, 고유값)을 추출한다. 각 KL 모드는 FEM 강성행렬 조립 시 분리된 형태로 반영되어 평균 강성행렬 K0와 모드별 강성행렬 로 저장되며, 이를 기반으로 분리된 형태의 약형식을 얻는다. 분리된 약형식에 대해 고정점 반복법을 통해 분리된 함수를 교대로 갱신하여 수렴할 때까지 반복한다. 이때 확률 변수 값에 따라 전체 강성행렬 를 재조립없이 빠르게 계산할 수 있고 최종적으로 공간에 대한 함수와 확률 변수에 대한 함수를 얻는다.
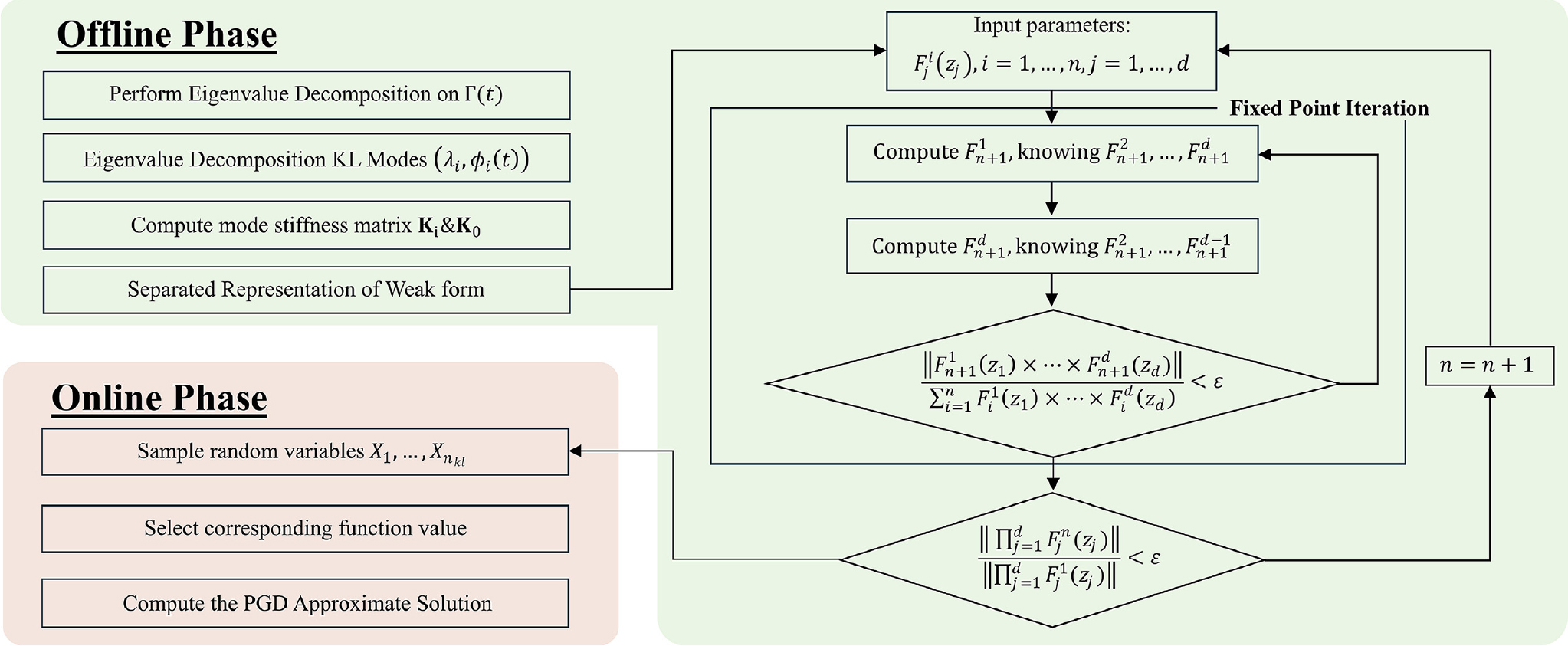
온라인 단계에서는 생성한 확률변수값에 따라, 오프라인에서 계산된 분리 함수 중 해당 함수 값을 선택하고 공간 함수와 곱셈으로 결합하여 PGD 근사해 를 즉시 얻는다.
PGD의 계산량은 고전적인 방식과 달리 해공간의 차원이 늘어날수록 지수적으로 증가하지 않고, 형태로 선형적으로 증가한다(Chinesta et al., 2013). 대부분의 공학 문제에서는 충분한 정확도를 가지기 위해 필요한 모드의 수 N이 수십 개 수준에 불과하기 때문에 PGD는 고차원 파라메트릭 문제에 대해 전통적인 FEM 기반의 몬테카를로 방식보다 훨씬 빠른 계산이 가능하다.
6. 수치예제
본 수치 예제에서는 무작위 영률(Young’s modulus) 을 갖는 평판 문제에 대해 PGD를 적용했다. 평판은 Fig. 2와 같이 4절점 2차원 사각형 요소를 기반으로 총 252개의 요소로 이산화되었다.
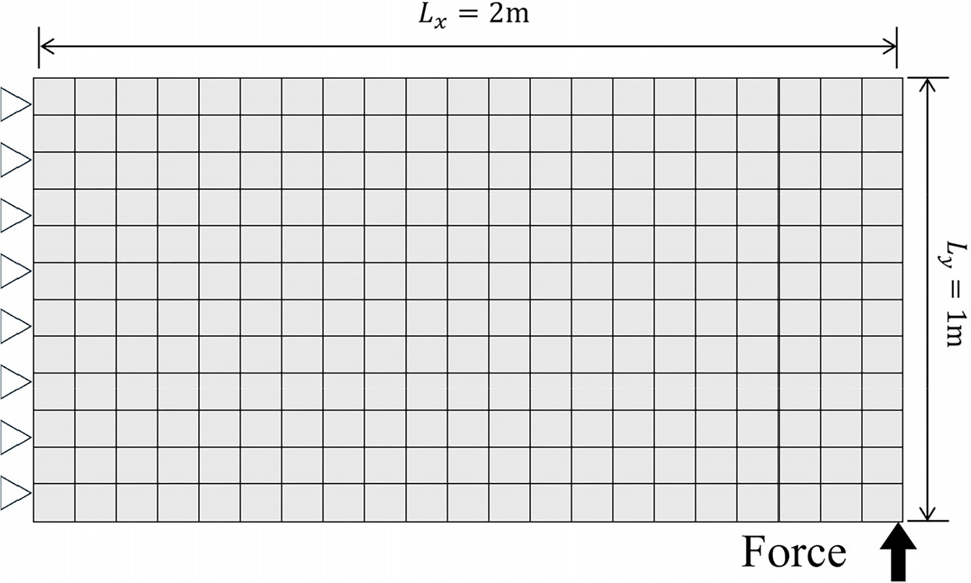
랜덤필드는 동일한 평판 형상에 대해 동일한 격자로 이산화하였으며, 각 격자 포인트의 값을 형상함수를 통해 각 요소의 적분점에 직접 매핑하였다. 랜덤필드의 공분산 함수는 KL 근사를 통해 계산되었으며, 상위 5개(N = 5)의 고유값과 고유함수를 사용하여 다음 식 (13)과 같이 근사하였다:
여기서, 평균 영률 는 200GPa, 표준편차 𝜎는 20GPa이며, 공분산 함수로는 가우시안 커널 형태의 식 (14)를 사용하였다.
이때 는 영역 내 임의의 위치이고, 상관길이 L은 0.5로 설정하였다.
해석에 사용된 평판 모델은 546개의 자유도를 가지며, 5개의 확률 변수는 각각 0부터 1까지의 범위를 균등하게 100개로 이산화하여 총 100개의 확률 공간 자유도를 가지도록 구성하였다. 공간에 대한 적분은 가우스 적분법을, 확률 변수에 대한 적분은 사다리꼴 공식(Trapezoidal Rule)을 이용하여 수행하였다. 또한, 오차 의 계산을 간소화하기 위해 확률 변수에 대한 함수는 모두 정규화하여 공간에 대한 함수의 크기가 각 모드의 기여도를 나타내도록 하였다.
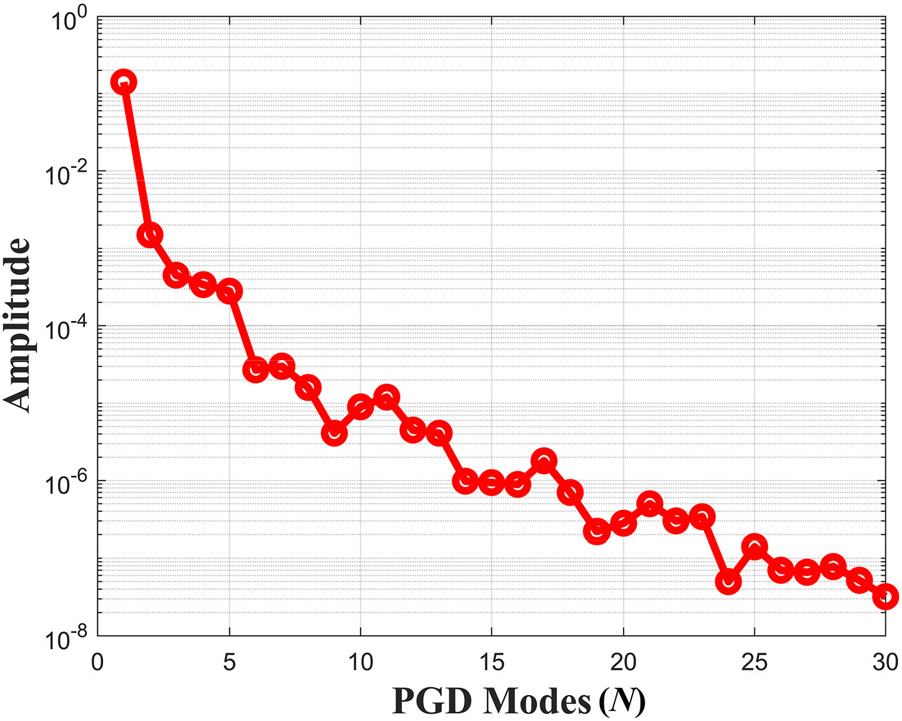
Fig. 3은 PGD 모드별 크기를 나타낸 것으로 각 모드가 전체 해에 얼마나 기여하는지를 보여준다. 고차 모드로 갈수록 크기가 감소하는 양상이 줄어드는 것을 확인할 수 있으며, 이는 랜덤 필드에 의한 시스템의 주요 변동성이 저차 모드에 집중되어 있음을 의미한다. 이러한 결과는 낮은 차수의 근사만으로도 높은 정확도를 확보할 수 있는 PGD의 효율성을 잘 보여준다.
모드 수가 증가함에 따라 PGD 근사 해의 정확도는 점진적으로 향상되는 경향을 보인다. Fig. 4는 PGD 모드 개수에 따른 평균 오차와 계산 시간의 변화를 나타낸다. 평균 상대 오차는 초기 저차 모드에서 급격히 감소하며 빠른 수렴 양상을 보이는 반면, 고차 모드로 갈수록 감소폭이 완만해져 추가 모드에 따른 성능 향상 효과가 점차 제한됨을 알 수 있다. 이는 저차 모드가 전체 해공간을 지배하는 주요 정보를 효과적으로 포착하고 있으며, 고차 모드는 세부적인 오차를 보완하는 역할을 함을 의미한다.
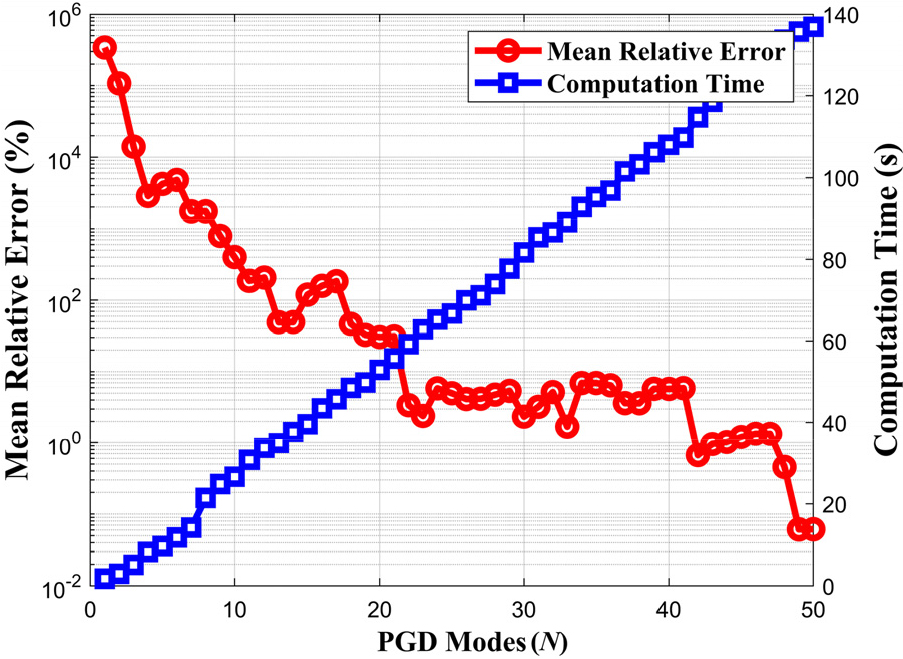
반면, 계산 시간은 모드 수에 따라 거의 선형적으로 증가하는 양상을 보여, 실용적인 관점에서는 오차 감소 효과 대비 계산 비용을 고려한 적절한 모드 수 선택이 요구된다.
상위 5개의 KL 모드를 포함한 랜덤필드를 활용하여 PGD 근사 해와 FEM 기반 몬테카를로 시뮬레이션(MCS)으로 얻은 응력의 불확실성 정량화 결과를 Fig. 5에 제시하였다. 온라인 단계에서 PGD 근사해는 각 확률 변수를 정규분포에 따라 샘플링하여 계산되었으며, 총 10,000개의 샘플을 바탕으로 몬테카를로 시뮬레이션이 수행되었다. 비교는 평균값 기반 FEM 해석에서 최대 응력이 발생한 요소의 본 미제스 응력을 기준으로 이루어졌고, 응력 집중과 같이 민감한 영역에서도 두 방법 간 결과 차이가 작게 유지됨을 확인할 수 있었다.
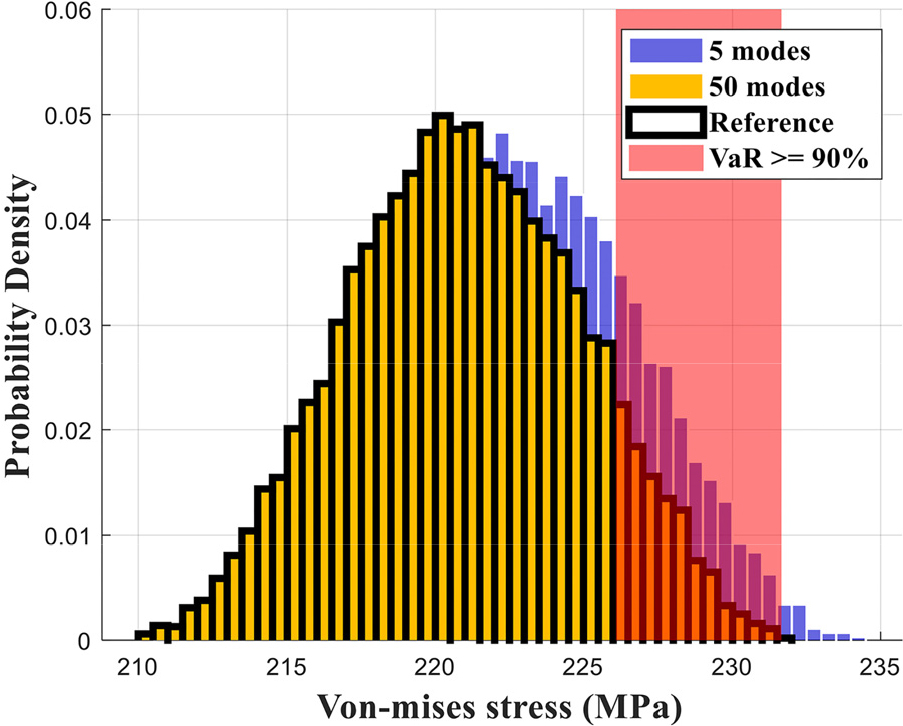
추가적으로 불확실성이 존재하는 시스템의 신뢰성 평가를 위해 90%(𝛽=0.90) 수준의 위험가치(Value at Risk, VaR0.90)VaR0.90를 산정하였다. VaR0.09은 전체 응력 분포 중 발생 확률이 10% 이하인 극단 구간에 해당하는 응력 값들의 평균으로 정의되며, 낮은 확률의 위험 상황에서 기대되는 평균 응답을 수치적으로 정량화한 지표이다. PGD 기반 샘플링을 통해 계산된 VaR0.90은 몬테카를로 시뮬레이션의 참값과 매우 유사하게 나타나, 제안된 방법이 평균 응답뿐 아니라 극단값 통계 특성까지도 정확하게 재현할 수 있음을 확인하였다(Table 1).
7. 결 론
본 연구에서는 차수 축소 기법인 적합 일반화 분해(Proper Generalized Decomposition, PGD)를 활용하여, 랜덤필드 기반 재료 불확실성을 갖는 구조 시스템의 해를 효율적으로 계산하고 그에 따른 불확실성을 정량화하는 방법을 제안하였다.
무작위 영률을 따르는 재료 모델은 카루넨 뢰브 전개를 통해 상위 고유값 및 고유함수를 기반으로 유한 개의 확률 변수로 근사되었으며, 해당 랜덤 필드는 유한요소 모델과 연계되어 시스템 전반의 확률적 거동을 반영할 수 있도록 구성되었다. 또한, KL 모드 기반의 강성 행렬 분리 표현을 적용함으로써 확률 변수의 변화가 FEM 강성 행렬의 전체 조립에 영향을 미치지 않도록 설계되었고, 이를 통해 높은 계산 효율성을 확보하였다.
PGD를 적용한 수치 예제에서는 적은 수의 모드만으로도 해의 정확도가 빠르게 수렴함을 확인할 수 있었으며, 해 전체의 주요 변동성이 저차 모드에 집중되어 있음을 통해 차수 축소 모델의 실효성을 입증하였다. 특히, 전통적인 FEM 기반 몬테카를로 시뮬레이션과 비교했을 때, 동일한 수준의 정확도를 유지하면서도 약 100배 이상의 계산 시간 절감 효과를 나타내었으며, 이를 통해 PGD가 고차원 시스템에서의 효율적인 불확실성 정량화를 위한 효과적인 수단임을 확인하였다.
